文章目录
前言
基于mysql的话语法和其他数据库都类似,其中与Oracle中的区别就是字段不同,还有注释也不同,mysql搭配NaviCat这个可视化工具简直不要太方便,但是企业的话一般都是云端数据库,理解并且掌握基本语法将能让我们的开发效率更高。
一、数据库账号管理
1.数据库账号管理的作用是什么?
对于互联网大型公司来说每一条数据就是财富,能够保护某些数据隐私安全
2.现象为什么有的表可以看到所有库有的却不能呢?
因为权限被限制了,基于这里贴上图方便理解权限的层次。

3.案例(1)
我们来创建一个zara账号,这个账号只能看到girls数据库,并且这个数据库中的表操作权限只有查询
语法 : grant select,update…
grant select
on girls.*
to 'zara'@'localhost'
identified by 'zara123';
看一下结果:1142 -用户’zara’@localhost对表’tsolr job’的删除命令被拒绝

3.案例(2)
对比上面我们创建一个用户给他所有权限,让他可以看到所有数据库并且都能进行增删改查。
GRANT ALL PRIVILEGES ON *.* TO 'zhangsan'@'%' IDENTIFIED BY 'zhangsan123'
WITH GRANT OPTION;
结果:可以正常使用所有权限。

4.原理
数据库中有四张表和mysql权限是有关系的这是创建数据库时候自带的。
| 表名 | 权限 |
|---|---|
| db表 | 控制所有用户对库的权限 |
| user表 | 管理所有的账号 |
| tables_priv表 | 表层权限 |
| columns_priv表 | 字段层权限 |
上图:

按权限从大到小来说依次顺序
db>user>tables>columns
用处:方便保护某些数据隐私
二、四大引擎
- InnoDB存储引擎
- MyISAM存储引擎
- MEMORY存储引擎
- Archive存储引擎
mysql创建的时候默认采取的是InnoDB
1.常用引擎
InnoDB存储引擎和MyISAM存储引擎比较常用。
2.区别
对于一些项目中的配置有些不需要涉及到增删改,就用不到事务,这个时候就可以选择MYISAM引擎它查询速度快。
3.什么是事物?
举个简单又经典的例子就是转账了,事务中张三要进行转账给李四,那么转出的账号要扣钱,转入的账号要加钱,这两个操作都必须同时执行成功,为了确保数据的一致性。

不同的存储引擎都有各自的特点,以适应不同的需求,如下表。
重要的三点:
- 储存限制
- 支持事务
- 支持全文索引

提交、回滚、奔溃恢复能力,并要求实现并发控制,建议使用InnoDB
3.外键问题
思考如果一张表用MYISAM又用了InnoDB如果连表查询那么我改走哪个搜索引擎?
答:所以如果你的表的是MYISAM引擎它是不支持外键的所以不会遇到上面这个问题。
4.四大引擎的作用
InnoDB存储引擎
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,上图也看到了,InnoDB是默认的MySQL引擎。InnoDB主要特性有:
1、InnoDB给MySQL提供了具有提交、回滚和崩溃恢复能力的事物安全(ACID兼容)存储引擎。InnoDB锁定在行级并且也在SELECT语句中提供一个类似Oracle的非锁定读。这些功能增加了多用户部署和性能。在SQL查询中,可以自由地将InnoDB类型的表和其他MySQL的表类型混合起来,甚至在同一个查询中也可以混合
2、InnoDB是为处理巨大数据量的最大性能设计。它的CPU效率可能是任何其他基于磁盘的关系型数据库引擎锁不能匹敌的
3、InnoDB存储引擎完全与MySQL服务器整合,InnoDB存储引擎为在主内存中缓存数据和索引而维持它自己的缓冲池。InnoDB将它的表和索引在一个逻辑表空间中,表空间可以包含数个文件(或原始磁盘文件)。这与MyISAM表不同,比如在MyISAM表中每个表被存放在分离的文件中。InnoDB表可以是任何尺寸,即使在文件尺寸被限制为2GB的操作系统上
4、InnoDB支持外键完整性约束,存储表中的数据时,每张表的存储都按主键顺序存放,如果没有显示在表定义时指定主键,InnoDB会为每一行生成一个6字节的ROWID,并以此作为主键
5、InnoDB被用在众多需要高性能的大型数据库站点上
InnoDB不创建目录,使用InnoDB时,MySQL将在MySQL数据目录下创建一个名为ibdata1的10MB大小的自动扩展数据文件,以及两个名为ib_logfile0和ib_logfile1的5MB大小的日志文件
MyISAM存储引擎
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。MyISAM主要特性有:
1、大文件(达到63位文件长度)在支持大文件的文件系统和操作系统上被支持
2、当把删除和更新及插入操作混合使用的时候,动态尺寸的行产生更少碎片。这要通过合并相邻被删除的块,以及若下一个块被删除,就扩展到下一块自动完成
3、每个MyISAM表最大索引数是64,这可以通过重新编译来改变。每个索引最大的列数是16
4、最大的键长度是1000字节,这也可以通过编译来改变,对于键长度超过250字节的情况,一个超过1024字节的键将被用上
5、BLOB和TEXT列可以被索引
6、NULL被允许在索引的列中,这个值占每个键的0~1个字节
7、所有数字键值以高字节优先被存储以允许一个更高的索引压缩
8、每个MyISAM类型的表都有一个AUTO_INCREMENT的内部列,当INSERT和UPDATE操作的时候该列被更新,同时AUTO_INCREMENT列将被刷新。所以说,MyISAM类型表的AUTO_INCREMENT列更新比InnoDB类型的AUTO_INCREMENT更快
9、可以把数据文件和索引文件放在不同目录
10、每个字符列可以有不同的字符集
11、有VARCHAR的表可以固定或动态记录长度
12、VARCHAR和CHAR列可以多达64KB
使用MyISAM引擎创建数据库,将产生3个文件。文件的名字以表名字开始,扩展名之处文件类型:frm文件存储表定义、数据文件的扩展名为.MYD(MYData)、索引文件的扩展名时.MYI(MYIndex)
MEMORY存储引擎
MEMORY存储引擎将表中的数据存储到内存中,未查询和引用其他表数据提供快速访问。MEMORY主要特性有:
1、MEMORY表的每个表可以有多达32个索引,每个索引16列,以及500字节的最大键长度
2、MEMORY存储引擎执行HASH和BTREE缩影
3、可以在一个MEMORY表中有非唯一键值
4、MEMORY表使用一个固定的记录长度格式
5、MEMORY不支持BLOB或TEXT列
6、MEMORY支持AUTO_INCREMENT列和对可包含NULL值的列的索引
7、MEMORY表在所由客户端之间共享(就像其他任何非TEMPORARY表)
8、MEMORY表内存被存储在内存中,内存是MEMORY表和服务器在查询处理时的空闲中,创建的内部表共享
9、当不再需要MEMORY表的内容时,要释放被MEMORY表使用的内存,应该执行DELETE FROM或TRUNCATE TABLE,或者删除整个表(使用DROP TABLE)
5.存储引擎的选择
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive
使用哪一种引擎需要灵活选择,一个数据库中多个表可以使用不同引擎以满足各种性能和实际需求,使用合适的存储引擎,将会提高整个数据库的性能
三、DDL(数据定义语言)
1.库的管理
库的管理分别有、创建、修改、删除。
- 创建:create
- 修改:alter
- 删除:drop
语法:
创建数据库
create database [if not exists]库名;
如果没有这个库就创建
create database if not exists books;
2.表的管理
语法:
create table 表名(
列名 列的类型【(长度)约束】,
列名 列的类型【(长度)约束】,
列名 列的类型【(长度)约束】,
.........
列名 列的类型【(长度)约束】
)
#案例:创建表book
create table book(
id int ,#编号
Bname VARCHAR(20),#图书名
price DOUBLE,#价格
authorId int,#作者编号
publishDate DateTIME#出版日期
)
#查看表结构
DESC book;
#1.表的修改
语法
alter table 表名 add|drop|modify|change column 列名【列类型 约束】;
#修改列名
alter table book change column publishdate pubDate datetime;
#修改列的类型或约束
alter table book modify column pubdate timestamp;
#添加新列
alter table author add column annual double;
#删除列
alter table book_author drop column annual;
#修改表名
alter table author rename to book_author;
desc book;
2.表的删除
drop table if exists book_author ;
show tables;
#通用的写法
drop database if exists 旧库名;
create database 新库名;
drop table if exists 旧表名;
create tables 表名();
#3.表的复制
insert into author values
(1,'剑圣','中国'),
(2,'德玛','中国'),
select *from author;
select *from copy2;
#仅仅复制表的结构
create tables copy2
select *from author;
#复制表的结构+数据
create tables copy2
select *from author;
#只赋值部分数据
create table copy3
select *from id,au_name
from author
where nation='中国';
#仅仅复制某些字段
create tables copy4
select *from id,au_name
from author
where 0;
四、常见的约束
1.约束的含义
含义:是一种限制,用于限制于表中的数据,为了保证表中的数据的准确和可靠性。
2.分类
可以分为六大约束
| 约束 | 意思 |
|---|---|
| not null | 非空,用于保证该字段的值不能为空比如姓名学号等 |
| default | 默认,用于保证该字段有默认值比如性别 |
| primary key | 主键,用于保证该字段的值具有唯一性,并且非空,比如学号,一个编号等 |
| check | 检查约束【mysql中不支持】比如年龄,性别 |
| unique | 唯一,用于保证该字段的值具有唯一性,可以为空比如座位号 |
| foreign key | 外键,用于限制两个表的关系,用于保证该字段的值必须来自于主表的关联列的值在从表添加外键约束,用于引用主表中某列的值,比如学生表的专业编号,员工表的部门编号,员工表的工种编号 |
3.添加约束的时机
有两种时机,创建表时、修改表时。
4.约束的添加分类
六大约束语法上都支持,但外键约束没有效果。
表级约束:
除了非空、默认、其它的都支持。
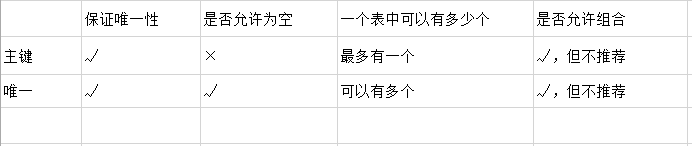
主键和唯一的大对比:
外键:
- 要求在从表设置外键关系
- 从表的外键列的类型和主表的关联列的类型要求一致或兼容,名称无要求。
- 主表的关联列必须是一个key(一般是主键或唯一)
- 插入数据时,先插入主表,在插入从表删除数据时,先插入主表,在删除主表
创建表时添加约束
语法:
直接在字段名和类型后面追加 约束类型即可
只支持:默认、非空、主键、唯一
create table 表名(
字段名 字段类型 列级约束,
字段名 字段类型,
表级约束
)
语法:
create database students;
use students;
drop table stuinfo ;
create table stuinfo(
id int primary key,#主键
stuName varchar(20) not null unique,#非空
gender char(1) check(gender='男' or gender='女'),#检查
seat int unique, #唯一
age int default 18,#默认约束
majorId int referendes major(id)#外键
);
create table major (
id int primary key,
majorName varchar(20)
)
#查看stuinfo中的所有索引,包括主键,外键,唯一
show index from stuinfo;
#.添加表级约束
#语法:在各个字段的最下面
【constraint 约束名】 约束类型(字段名)
drop table if exists stuinfo;
drop table if exists stuinfo;
create table stuinfo(
id int ,
stuname varchar(20),
gender char(1),
seat int ,
age int,
majorid int,
constraint pk primary key(id),#主键
constraint uq unique(seat),#唯一键
constraint ck check(gender='男' or gender ='女'),#检查
constraint fk_stuinfo_major foreign key(majorid)
references major(id)#外键
)
#通用的写法
create table if not exists stuinfo (
id int primary key,
stuname varchar(20),
sex char(1),
age int default 18,
seat int unique ,
majorid int ,
constraint fk_stuinfo_major foreign key(majorid)references major (id)
);
# 二 ,修改表时添加约束
#1.添加列级约束
alert table 表名 modify colum 字段名 字段类型 新约束;
#2.添加表级约束
alert table 表名 add【constraint 约束名】约束类型 (字段名)【外键的引用】;
drop table if exists stuinfo ;
create table stuinfo(
id int,
stuname varchar(1),
gender char(1),
seat int,
age int,
majorid int
)
desc stuinfo ;
#1.添加非空约束
alter table stuinfo modify column stuname varchar(20) not null;
#2.添加默认约束
alter table stuinfo modify column age int default 18;
#3.添加主键
#3.1列级约束
alter table stuinfo modify column id int primary key;
#3.2表级约束
alter table stuinfo add unique (seat);
#添加外键
alter table stuinfo add constraint fk_stuinfo_major foreign key(majorid) references major (id);
#三、修改表时删除约束
#1.删除非空约束
alter table stuinfo modify column stuname varchar(20)null;
#2.删除默认约束
alter table stuinfo modify column age int;
#3.删除主键
alter table stuinfo drop primary key,
#4.删除唯一
alter table stuinfo drop index seat;
#5.删除外键
alter table stuinfo drop foreign key fk_stuinfo_major;
show index from stuinfo ;
show index from stuinfo;
#标识列
#又称为自增长列
#含义:可以不用手动的插入值,系统提供默认的序列值
#特点:
#1,标识列必须和主键搭配吗?不一定,但要求是一个key
##2.一个表可以有几个标识列?最多一个!
#3.标识列的类型只能是数值型
#4.标识列可以通过SET auto_increment_increment=3;数值步长可以通过手动插入值,设置起始值
#一、创建表时设置标识列
drop table if exists tab_identity ;
create table tab_identity(
id int ,
name float unique auto_incrment,
seat int
);
truncate table tab_identity;
insert into tab_identity (id,name)values(null,1);
insert into tab_identity (name)values(2);
insert into tab_identity (id)values(6);
select*from tab_identity;
show variables like'%auto_increment%'
#设置步长
set auto_increment_increment=3;
尾言
有些东西就是根据结果来推敲的,不要去死记硬背,学习方法和思维。
