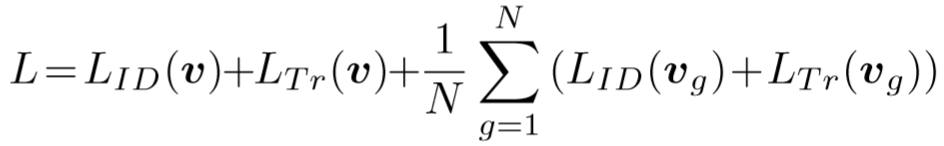Relation-Aware Global Attention for Person Re-identification
本文主要提出了一个Relation-Aware Global Attention(RGA)模块,该模块可以提取空间上不同区域之间的关系向量,从而每个区域的特征能够“抓住局部”,同时“把握全局”。
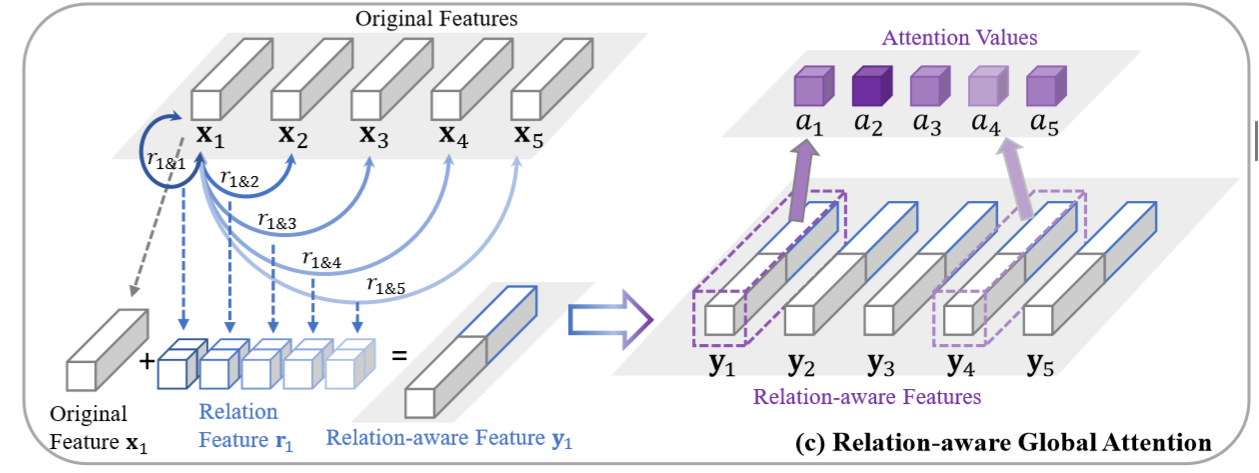
该注意力的思想是计算每个区域特征向量与其它区域特征向量的关系,并进行concat,再评估注意力得分。

作者将这个思想应用到了空间维度和通道维度。
① 空间维度:定义两个空间node的特征向量为![]() ,由两个1x1卷积、BN、ReLU构成。有此获得空间的relation映射图。重构的特征映射由三部分组成,第一部分为原始的特征映射的投影,第二部分为relation映射中纵向获取关系向量,第三部分横向获取关系向量,特征的融合过程为:原始特征通过1x1卷积、BN、ReLU、通道池化压缩为1维度的映射,后两部分的关系特征通过1x1卷积、BN、ReLU获得关系映射,最后concat。最后的空间注意力包含两层卷积:
,由两个1x1卷积、BN、ReLU构成。有此获得空间的relation映射图。重构的特征映射由三部分组成,第一部分为原始的特征映射的投影,第二部分为relation映射中纵向获取关系向量,第三部分横向获取关系向量,特征的融合过程为:原始特征通过1x1卷积、BN、ReLU、通道池化压缩为1维度的映射,后两部分的关系特征通过1x1卷积、BN、ReLU获得关系映射,最后concat。最后的空间注意力包含两层卷积:![]() 。
。
② 通道维度:将每个通道的H*W特征转为特征向量。之后同上。
Multi-Granularity Reference-Aided Attentive Feature Aggregation for Video-based Person Re-identification
本文提出了Multi-Granularity Reference-aided Attentive Feature Aggregation(MG-RAFA)网络框架。该方法考虑到行人的图片存在不同尺度的特征,因此采用了多粒度的网络结构,为了把我全局的特征,采用了关系特征来生成注意力。
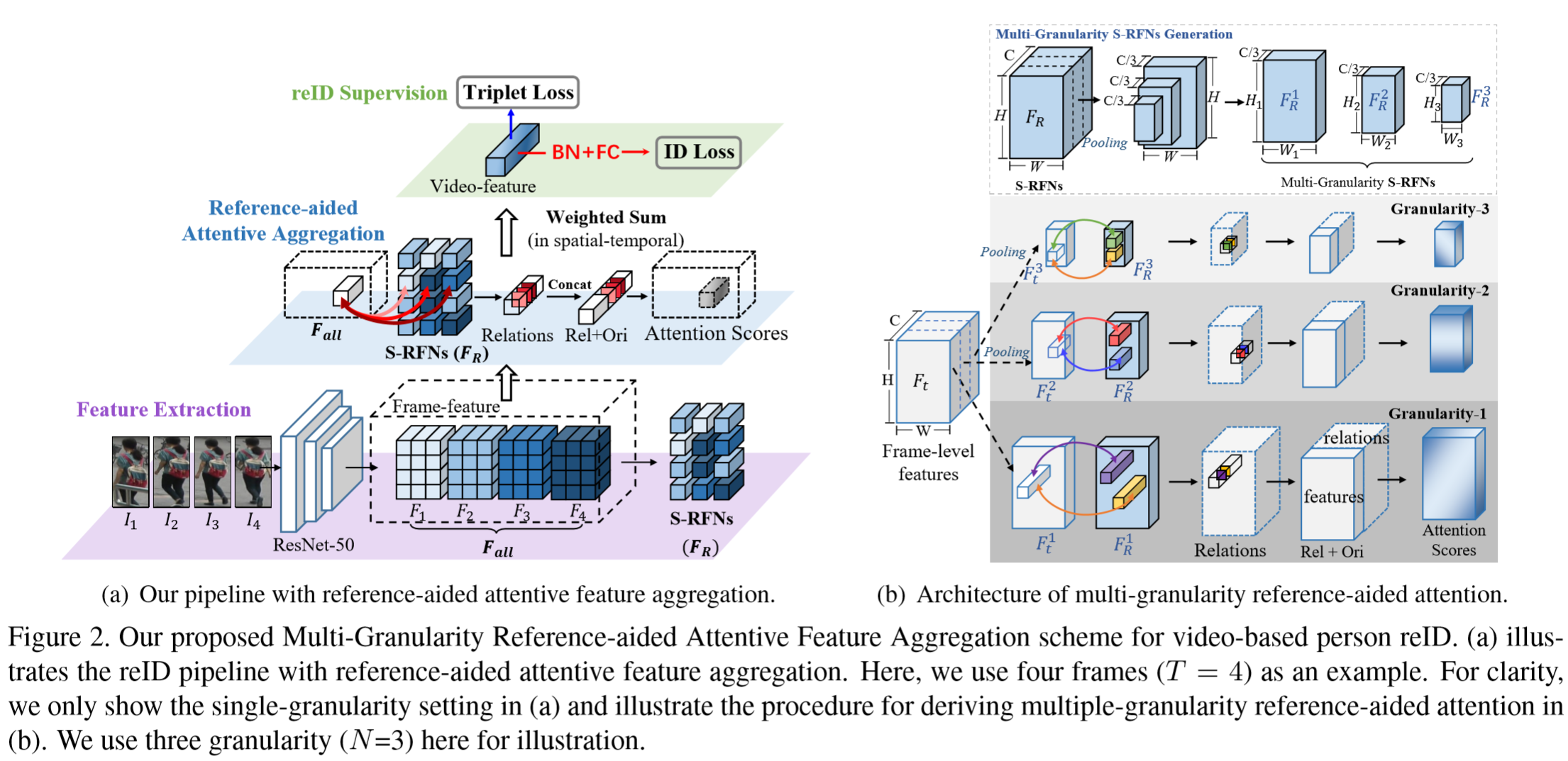
左图展示了单个粒度的特征提取过程,按像素空间划分成若干区域特征向量,每个特征向量都与其它区域特征计算关系特征,并级联得到新特征。第一层:通过骨干网络提取各帧的特征映射,然后采用时间维度的平均值作为参考帧。第二层:各帧的区域特征与参考帧计算相关度:![]() ,通过1x1卷积、BN、ReLU,再向量相乘。将原始特征映射与关系特征进行两层卷积变换得到注意力得分,为:
,通过1x1卷积、BN、ReLU,再向量相乘。将原始特征映射与关系特征进行两层卷积变换得到注意力得分,为:![]() 。得到的注意力得分通过Softmax,再与原始特征相乘。
。得到的注意力得分通过Softmax,再与原始特征相乘。
右图展示了多粒度的特征提取过程。按通道维度划分成3组,其余两组通过空间平均池化进行尺寸的压缩,最后将特征进行级联。
损失函数为: