系统-Fugaku System
名字的来源就是Mount Fuji,简单翻译就是富士山或者富岳的意思
一个系统有396个满配的Rack和36个半配的Rack;
一个Rack有384个Node(CPU);
那么Node数目就是396Full *384+36Half*192=152064+6912=158976个CPU;
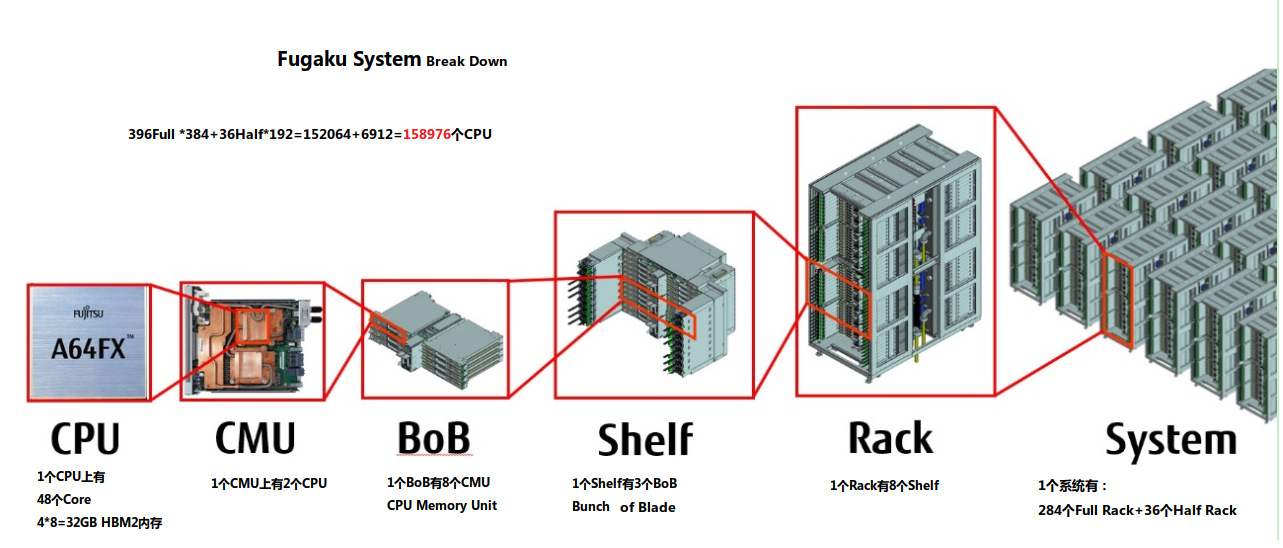
Rack高度2000mm,宽度800mm,深度是1400mm;
存储分为三层
第一层是全局文件系统的cache;
第二层是Lustre Based 文件系统;
第三层是还没实现的Off Site的云存储服务;
互联-TofuD网络
Tofu代表
Torus
Fusion,环形融合;
最后的一个D代表,High Density的节点和Dynamic packet slicing for Dual-rail (双导轨)transfer。
6D网络使用六个坐标系表示,X,Y,Z,A,B,C,其中
A,C坐标可以是0或者1;B坐标可以是0,1,2;X,Y,Z的坐标值取决于系统的规模;(所谓1图胜千言,请看下图)

X,Y,Z,B使用2个Port,A,C使用1个Port;每个Port的Link提供5GB/s的峰值吞吐(其中每个Link是8个6.25Gb/s的差分速率的lan组成的(
这句话不是很懂));
- 6D mesh/torus 网络实现了计算节点的高扩展性;
- 虚拟的3D torus rank mapping scheme同时提供了高可用和topology-aware的可编程性;
单个节点:1个TofuD Link有10个Port合计20个Lane,Data rate可以达到28Gbps, (28 Gbps x 2 lane x 10port=28Gbps*20Lanes=70GB/s)
单个Link的带宽是:28.05Gbps*2 lane* /8=7.0125GB/s
那么6个Link的带宽一共是:6.8GB/s*6=
40.8GB/s
实际可以达到38.GB/s,转化效率是38.1/40.8=93%;

TNI Tofu Network Interface
| C | Z*A | B | X*Y | ||
| CPU | CMU | BoB | Shelf | Rack | System |
| 2 | 8=4*2 | 3 | 8=2*4 4=2*2 | 284full +36half | |
| 16 CPU | 48 CPU | 384 CPU |
那么单个的CMU的规模就是X*Y*Z*A*B*C=1*1*1*1*1*2
那么单个的SHELF的规模就是
X*Y*Z*A*B*C=1*1*4*2*3*2
那么半框的RACK的规模就是:
X*Y*Z*A*B*C=2*2*4*2*3*2
其他的就暂时没看懂了。
CPU-A64FX
A64FX实物

芯片的大小是60mm*60mm,
TSMC 7 nm FinFET & CoWoS封装;
芯片布局
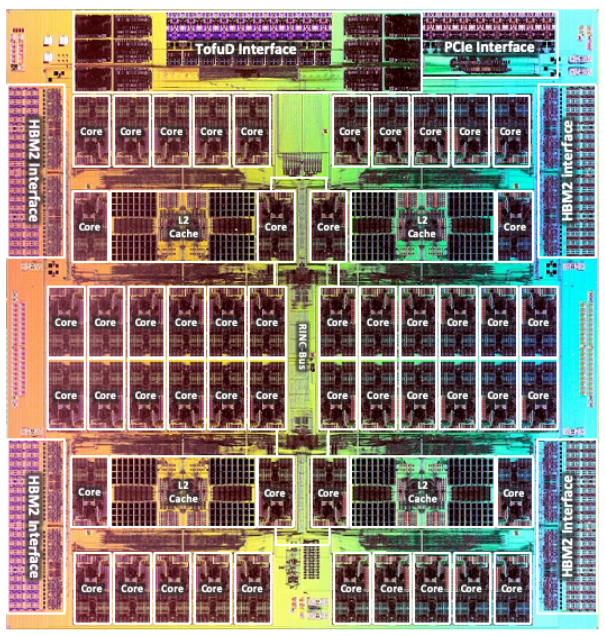
可以看到四边是四个HBM2的片上内存,上边是IO接口,其他大部分是Core和Cache,一共48个计算核心;另外4个Core不做计算;
片上内存部分,每个Stack是8GB,带宽是1024GB/s;
IO部分有两个,一个是TofuD Interface,一个是X16 PCIe Gen 3;
Core部分,是ARM V8.2 64bit的核心,实现了2个512bit的向量指令单元SVE(scalable vector extensions)(2*512*2MA/64=32FLOPS);
说是CPU的基础频率是2GHz,睿频是2.2GHz;
理论的FLOPS是488PFLOPS,睿频下的FLOPS是537PFLOPS;不考虑半宽的Rack的话,理论的PFLOPS是514PFLOPS;计算如下:
考虑152064个CPU的话,每个CPU48Core,运行在2.2GHZ,每个周期可以完成32个FP64的运算,理论性能是152064*48*2.2G*32/1000000=514PFLOPS
96%的节点的实际的HPL的性能是415PFLOPS,那么转化率就是415/514=
81
%;
功耗和散热的设计
跑HPL的压力的时候的耗电是28.33MW(7.33*3.863)。或者是14.7GFLOPS per Watt,这个要
再看一下是什么负载。
节点的大小是:
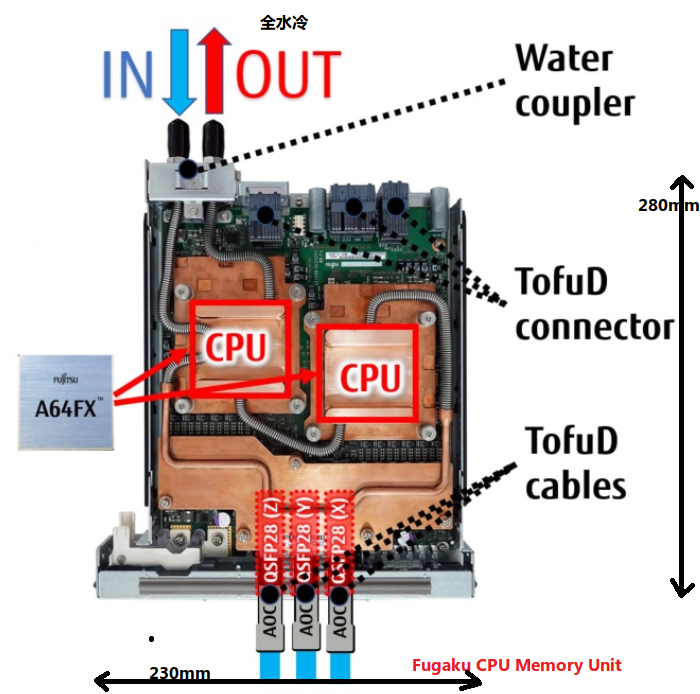
最后看一下实物集群:

参考文献:
- PPT地址:https://www.bnl.gov/modsim2019/files/talks/SatoshiMatsuoka.pdf
- 论文地址:https://www.icl.utk.edu/files/publications/2020/icl-utk-1379-2020.pdf
- 系统主页:https://postk-web.r-ccs.riken.jp/
- 系统的SPEC地址:https://postk-web.r-ccs.riken.jp/spec.html
- A64FX的芯片手册:https://github.com/fujitsu/A64FX
- TofuD的论文:https://ieeexplore.ieee.org/document/8514929
- tofuD的胶片:https://www.fujitsu.com/jp/Images/the-tofu-interconnect-d.pdf