条件
采用64位Oracle Linux 6.4, JDK:1.8.0_131 64位, Hadoop:2.7.3
Spark集群实验环境共包含3台服务器,每台机器的主要参数如 表所示:
| 服务器 | HOSTNAME | IP | 功能 |
|---|---|---|---|
| spark1 | spark1 | 92.16.17.1 | NN/DN/RM Master/Worker |
| spark2 | spark2 | 92.16.17.2 | DN/NM/Worker |
| spark3 | spark3 | 92.16.17.3 | DN/NM/Worker |
过程
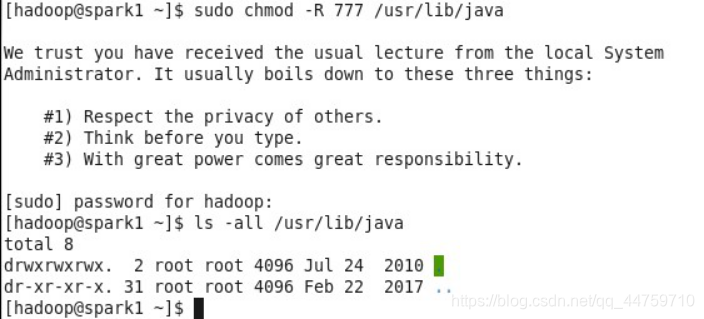
以hadoop用户登陆,切换到 root,修改/stage目录所有者为 hadoop 用户, 接着授予 hadoop 用户对 /usr/lib/java 目录的完全权限:
然后把 JDK 安装包拷贝到 /usr/lib/java 目录下,并进行解压。解压后可以看到 jdk1.8.0_181 目录,如图所示:


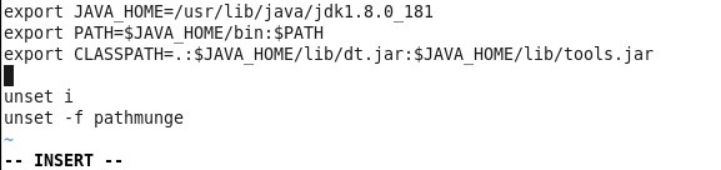
再次切换到 root 用户,修改 /etc/profile 配置文件,添加如图所示的项:
最后,重启系统,验证 java 信息,如图所示:

在 spark2 和 spark3 主机上分别进行 JDK 的安装