Redis简介 :
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。 redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。这使得Redis可执行单层树复制。存盘可以有意无意的对数据进行写操作。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步树时,可订阅一个频道并接收主服务器完整的消息发布记录。同步对读取操作的可扩展性和数据冗余很有帮助。
Redis安装:
下载redis
wget http://download.redis.io/releases/redis-4.0.6.tar.gz #下载redis客户端下载地址:http://redis.io/download,下载最新稳定版本。
解压文件
tar -zxvf redis-4.0.6.tar.gz #解压文件
安装GCC依赖
yum install gcc #安装GCC环境
cd redis-4.0.6 #跳转到目录下
编译安装并且加载src文件
make MALLOC=libc #编译文件
cd src && make install #将/usr/local/redis-4.0.6/src目录下的文件加到/usr/local/bin目录
启动Redis
./redis-server /usr/local/redis-4.0.6/redis.conf
Redis对象 :
首先认识一下redis数据对象有很多种比如我们常用的 字符串(String), 列表(List), Set(集合), Hash(哈希),Sorted Set(有序集合)等等,对于Redis来说键总是一个字符串对象,值可以是列表中的任意一种。
Redis使用对象来表示数据库中的键值,每当在redis创建一个键值对时,将会创建两个对象 即键对象,值对象,
字符串(String)
字符串对象的编码可以是int、 raw、 embstr,为啥它有3个?还不是因为用的多,最常用了,所以作者才特别关照对它千方百计的优化。如果一个字符串保存的是整数值,并且这个值可以用long类型表示,那么字符串对象会将整数值保存在字符串对象结构的ptr属性里。并将字符串编码encoding设置为int。此处要注意,1-9999之间的数值字符串在内存中可以复用。如果保存的是一个字符串的值,并且长度大于44字节(redis3.0之前是39),那么字符串对象将使用raw编码的简单动态字符串保存这个值。如果长度小于等于44,将使用embstr编码的简单动态字符串保存这个值。
39/44这个值从哪里来的:
要先看下当字符串类型时,redisObject的结构:

原因是,3.0版本之前,sdshdr这个结构里len和free记录了这个SDS的长度和空余空间,是unsigned int类型的,可以保存很大的数字,但是对于很短的SDS就浪费空间了(2个unsigned占8个字节)。而Redis分配内存一般是8 16 32 64这种分配的,redisObject占16个字节,最初free和len各占4个字节,字符串buf后面还有1个\0字节。所以当buf中为39字节时,16+8+39+1=64字节。当字符数少于39都会分配64字节的长度,3.0之前的39界限从这里得来的。3.0之后发现对于一些短的这样做不太合理,于是做了一次优化,优化点主要就在len free这2个属性上,之前一个len和一个free分别占用4字节,现在分别占用1个字节,又加了一个标识位flag占用1个字节,于是从原来的8到现在的 1*2+1=3。刚好缩短了5个字节,从39变成了44。另外embstr是只读的,在它进行运算时会先转成raw类型。
列表对象
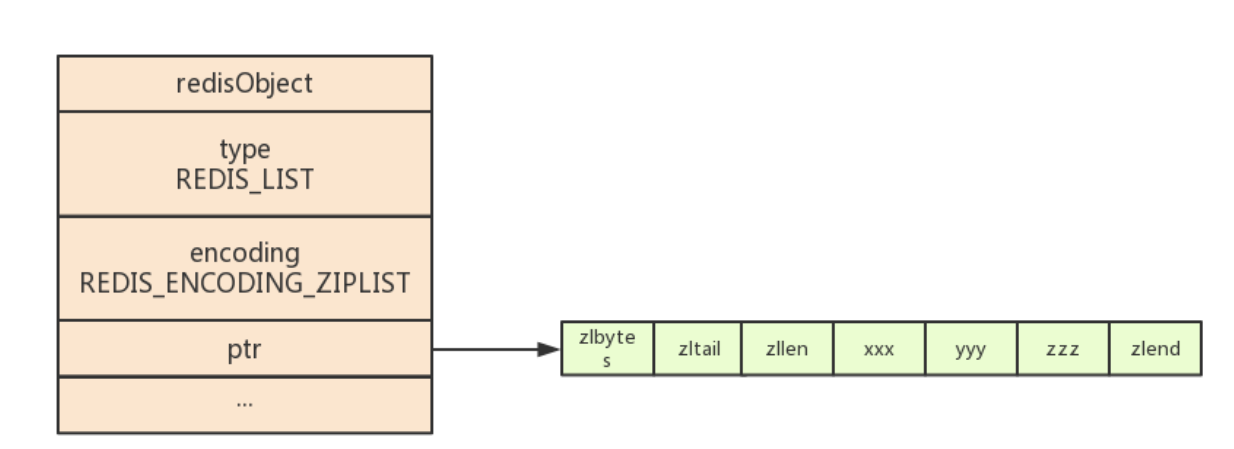
列表对象的编码可以是ziplist、linkedList结构。也就是压缩列表和双向链表结构。ziplist编码的列表对象使用压缩列表作为底层实现,每个压缩列表节点保存了一个列的元素。如下:
zlbytes记录整个压缩列表占用的内存字节数,在对压缩列表进行内存重分配或计算zlend的位置时使用。zltail记录压缩列表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以直接确定尾节点的位置。zllen记录压缩列表包含的节点数量,xxx/yyy/zzz表示各种节点,数量和长度不一定。zlend用于标记压缩列表的末端。
哈希对象
列表对象的编码可以是ziplist、linkedList结构。也就是压缩列表和双向链表结构哈希对象的底层编码可以是ziplist或者hashtable,目前仅分析之前版本的ziplist结构的哈希。
ziplist作为哈希对象的底层实现的时候,每当有新的键值对要加入到哈希对象时,程序会先把键放到ziplist的末尾,再把值放在ziplist的末尾。因此键值总是挨在一起的,键在前,值在后。如下图所示:

哈希对象保存的所有键值对的键和值的字符串长度都小于64字节
哈希对象保存的键值对数量小于512
这2个值也是在配置文件中可以修改的在redis.conf
集合对象set
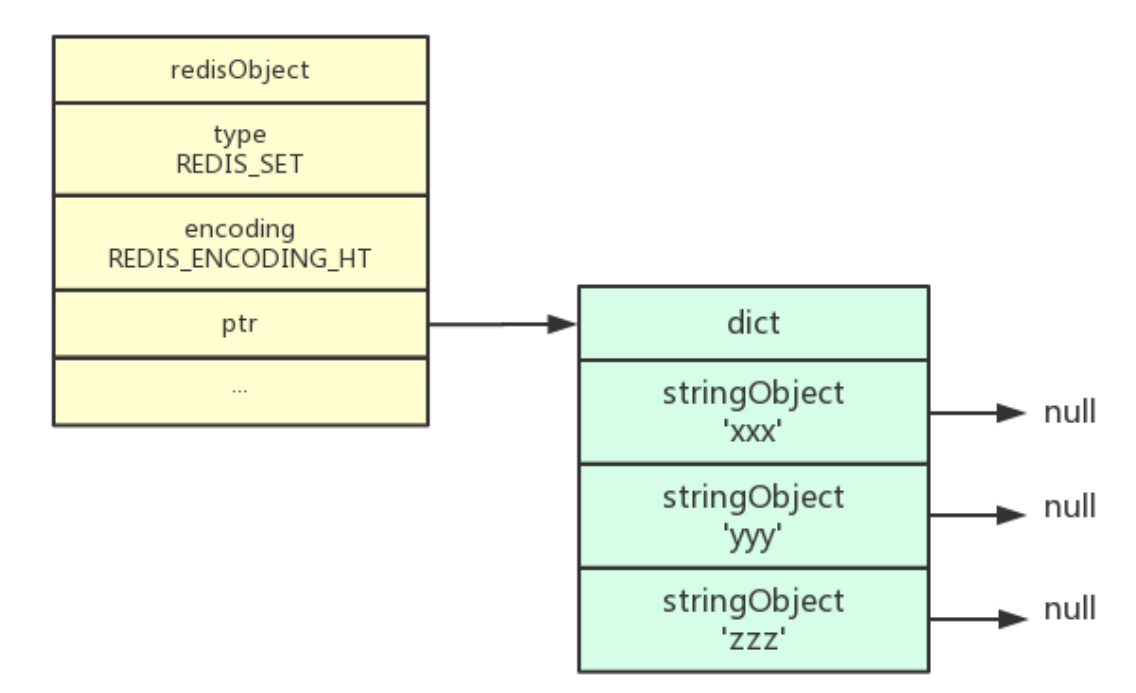
集合对象也有2种编码,分别是intset整数集合和hashtable哈希表。简单介绍一下:
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。

另一方便,hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是一个字符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为null.
直接切入正题:编码转换,当集合对象同时满足下面2个条件,使用intset,否则使用hashtable
-
集合里所有元素都是整数值
-
集合元素个数不超过512(可配置,redis.conf)
localhost:6379> sadd numbers 1 2 3 4 5
(integer) 5
localhost:6379> object encoding numbers
"intset"
localhost:6379> sadd numbers aaa
(integer) 1
localhost:6379> object encoding numbers
"hashtable"
localhost:6379>
有序集合对象
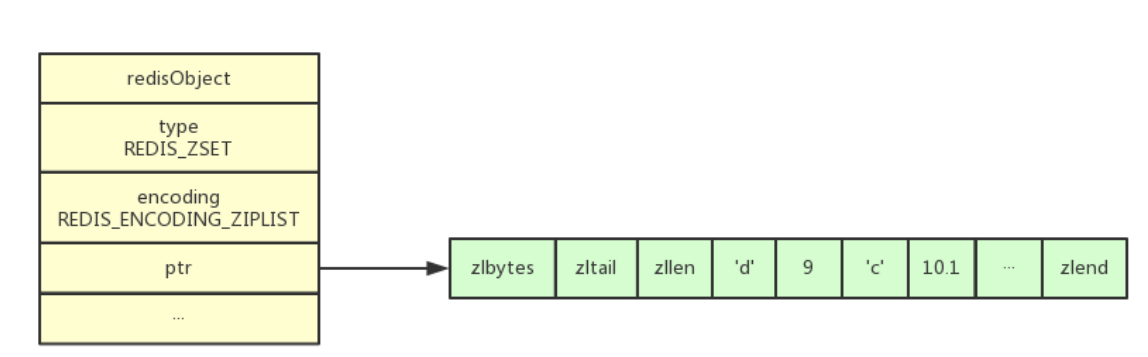
底层编码可以是ziplist或者skiplist结构,压缩列表特性之前说过,每个元素的集合使用2个位置相邻的节点保存,在有序集合中,第一个存放的是元素本身,第二个存放的是元素的分值score。压缩列表的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的位置。
localhost:6379> zadd socres 10.2 b 10.1 c 9 d 11 a
(integer) 4
localhost:6379> object encoding socres
"ziplist"
它的底层结构如下: