这篇文章我们会从网络的底层开始分析编码问题,并结合requests库,实例演示,彻底解决python的乱码问题!
直接开始,我们知道在网络世界中所有的数据都是二进制的形式进行传播的。web世界就是由0,1构成的世界,也就是说,我们每天从网上获取的所有的信息,在网路上传播,在到达你的电脑之前都是二进制数据,那么,然后通过编码显示我们人类能理解的文本!
一、从底层,数据在网络中传播时,具体如tcp报文,ip包等都是二进制的数据,在物理层上是光电信号。也就是说,光电信号传播到我们的主机时,首先是变成二进制的数据,然后,向上传递到应用层,这时我们就需要对二进制数据进行处理变成我们人类能读懂的文本形式了。那这个从二进制数据转化为文本的形式(字符集)的过程我们就称之为一个解码过程(decode),而从字符集转化为二进制数字的过程就是一个编码(encode)过程!
二、好了,了解了编码和解码,我们来从定义中找出几个关键字理解一下
- 码:编码,解码中的码指的是二进制码(十六进制)的意思,记住这个我们就能区分为什么称为编码和解码了
- 字符集:何谓字符集,从表面意思上说,字符集,不就是字符的集合吗!而字符就是我们人类能够看懂的文本,其实,字符集就是语言字符的集合。
- 还是字符集:上面其实有些歧义,码也确实是二进制码,但我们通常用十六进制来表示,创建一个字符集就是对语言的每个字符映射一个十六进制码。本质上来讲,编码和解码,就是一个互逆 的映射过程。
最后介绍一下字符集:每个国家的语言都可以创建自己的字符集,如中国的gbk,gb2312等,西欧国家的iso-8859-1等,国际通用编码utf8等,这些都是字符集,一些从十六进制到字符的映射集。这些字符集都是由国际组织Unicode统一管理
好了,现在 你大概是了解了什么是编码,解码,字符集。知道了本质,现在进行一些编码解码操作就很容易了!
接下来介绍两个python中的编码和解码的方法:encode和decodestr.encode(encoding = ”,error)
字符串的编码- str.decode(encoding= ”,error)
字符串的解码
# 详细的去百度一下吧!!!
又一个重点,用requests库结合实例来实现一下实际编程过程中的乱码问题
首先,第一个网站:盗墓笔记
这个网站,我们用requests请求一下
html = requests.get(url='http://seputu.com/biji1/1.html',headers=headers)
print(html.text)
打印出结果:
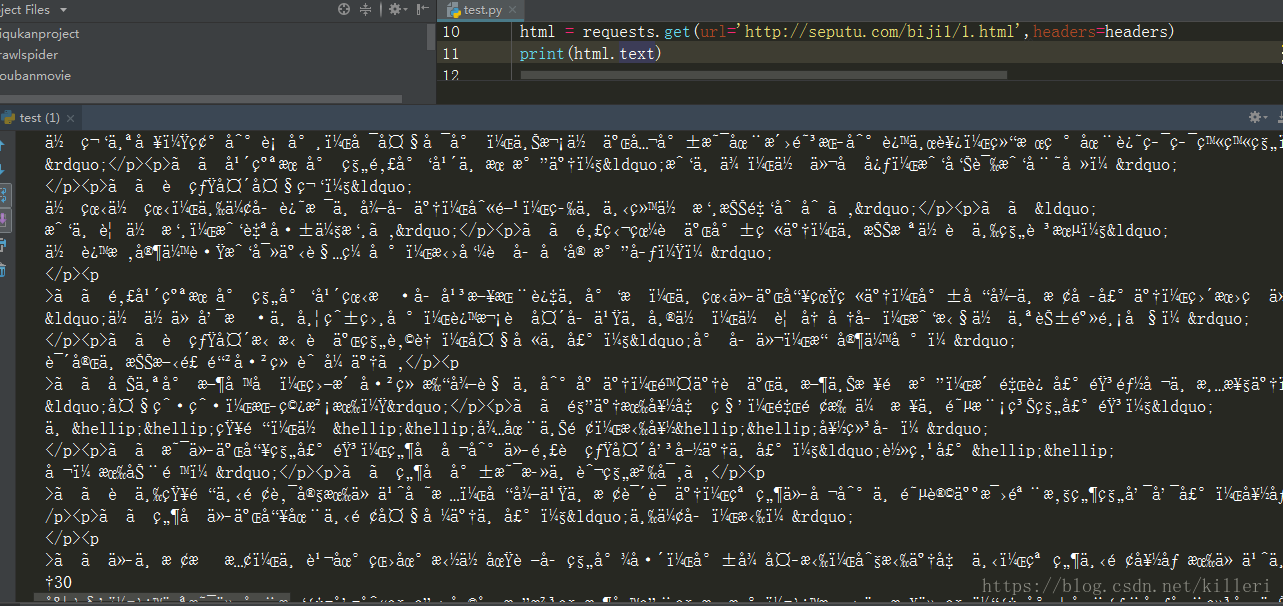
我靠,这是什么鬼,一堆乱码!!!!
怎么解决呢?
明显就是,网页的编码方式和你的编码方式不一样从而出现了乱码呀,所以我们只要将自己的编码方式和网页的一样不就行了
所以,我们首先要知道,网页的编码方式什么,用python的chardet库就可以了,这个库可以推测网页的原编码方式

import chardet
print(chardet.detect(html.content))
# 该方法接受bytes类型的参数这样我们就知道了网页的原编码方式了,如下:
{'language': '', 'encoding': 'UTF-8-SIG', 'confidence': 1.0}
也就是说网页的原编码是:utf-8-sig
还有一种知道网页原编码的方式:
直接从响应实体主体的headers里面找:
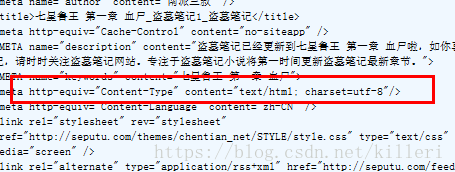
看这个响应体里面,header标签里面的charset参数就指定了内容的编码方式。。。。
我们知道了网页的原编码,现在只要我们按照原编码来编码响应不就行了!
这里有几种方式:
一、通用的方式
html.content.decode('utf-8-sig')
# 将内容解码用utf-8-sig这里的html.content,是requests库自带的一个将响应内容以二进制输入。
对于其他的字符串,想用改变他的编码方式,可以这样:
str.encode(' ').decode(' ')
# 空格中是你想用的解码和编码的编码方式二、用requests的方式:
html.encoding = 'utf-8-sig'
print(html.text)
# 指定html.text的编码方式通过上面两种方式的任何一种都可以对内容进行很好的正确编码。好了,我们讲完了一个例子,再来时候另一个:
网站:美女
这个网站是我们之前一个实战项目的网站,当我提取它的套图的标题的时候,发现出现了乱码
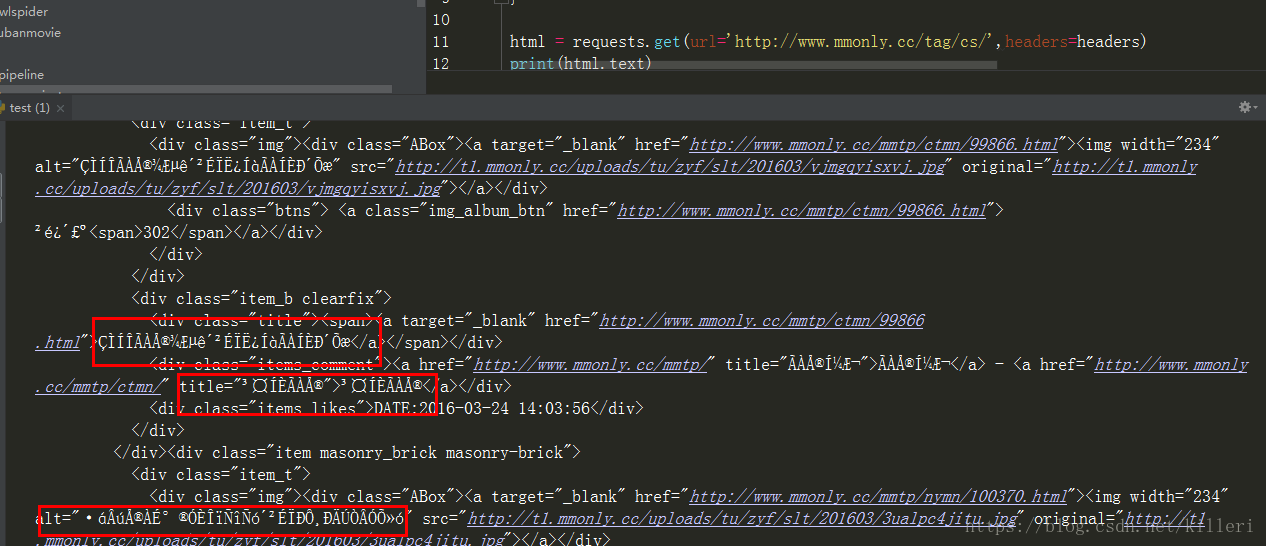
图中标记出来的都是乱码的汉字。
按规矩
找出原编码方式,从新编码
html = requests.get(url='http://www.mmonly.cc/tag/cs/',headers=headers)
print(chardet.detect(html.content))
# {'language': 'Chinese', 'encoding': 'GB2312', 'confidence': 0.99}
print(html.content.decode('GB2312','ignore'))
# 这里因为有些字符GB2312无法编码,所以用了ignore忽略
# html.encoding = 'gb2312'
# print(html.text)
# 这样也行
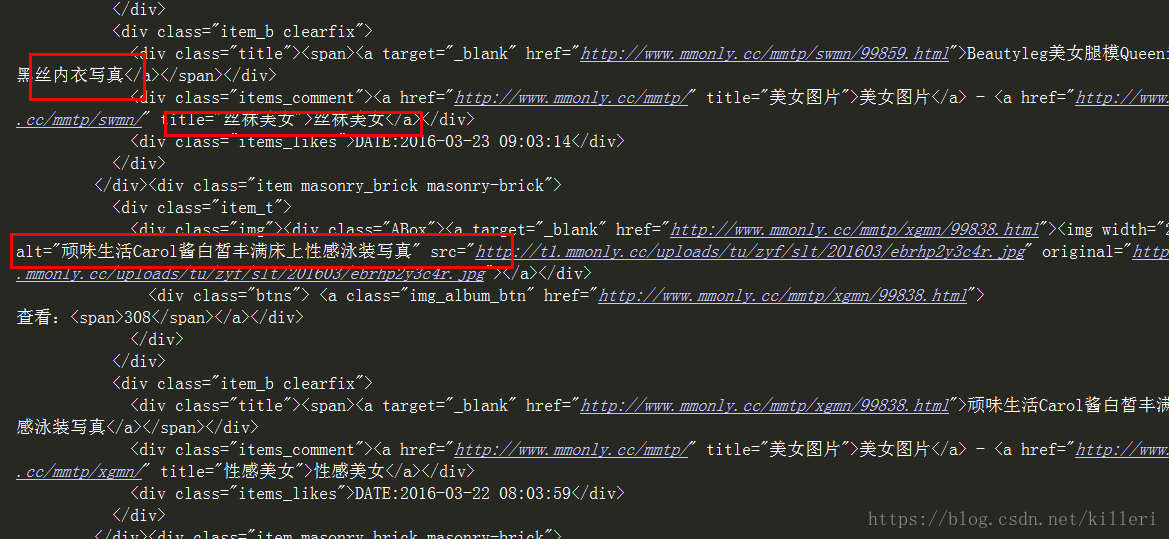
这样我们就正确解码这个了。
这个就是我们编码乱码的全部内容了!
对了,如果你学了scrapy,那其中的编码问题又怎么解决呢?
我这里简单的讲一下:
首先,一、response.text这里我们直接用encode+decode方式可以
当然,二、TextResponse有一个encoding可以指定文本编码,大概就是这两种方式了。
欢迎学习交流!!!