简介
我们在实现一些业务的时候,做一些比较特有的需求,用传统的DB去做会很繁琐,比如实现一个微信记步排行,频繁访问封锁IP,秒杀等等需求,而利用Redis里面的数据结构特性,能相对便携的实现这些需求。
详解
1. String
value 值可以是字符型,也可以是数字。
其实没有什么特别的特点,正常的持久化那些基本操作,get set 然后获取字符串长度,让字符串拼接等 如果是数字的话,可以incre decre 计数功能

常用命令:
get、set、incr、decr、mget等
应用场景:
因为Redis是单线程的,所以Redis使用INCRBY计数命令是原子操作,不会出现并发问题,可以防止刷单。
例如:超过访问次数,封锁IP
实现方式:
m,decr等操作时会转成数值型进行计算,此时redisObject的encoding字段为int。
2.Hash
主要用来存储一个对象信息,用的比较多。因为他的Value的底层类似、map的存储结构,便于用他的API进行存取,当然可以用Redis中String,kv进行存储,多少个属性值就用多少对KV,这样的话,会有类似的重复字段,造成存储浪费。或者Value以Json的形式存储,但是这样用的时候,会增加序列化和反序列化的开销。所以Redis的Hash解决了这些问题。
这里同时需要注意,Redis提供了接口(hgetall)可以直接取到全部的属性数据,但是如果内部Map的成员很多,那么涉及到遍历整个内部Map的操作,由于Redis单线程模型的缘故,这个遍历操作可能会比较耗时,而另其它客户端的请求完全不响应,这点需要格外注意。

常用命令:
hget、hset、hgetall等
应用场景:
- 典型应用场景
实现方式:
Redis的Hash对应的Value内部实际就是一个HashMap,实际有两种不同的实现,如果成员较少时,Redis为了节省内存会采用类似一维数组方式存储,对应的value RedisObject的encoding为zipmap,当成员数量增大时会自动转成真正的HashMap,此时encoding为ht。
3.List
list 是用的一个双向链表,所以他是有顺序的,其特点就跟链表特点一样了,从链表的两端推入或者弹出元素,根据偏移量进行修剪[trim] ,读取单个或者多个元素,根据值查找或者移除元素。

常用命令:
lpush,rpush,lpop,rpop,lrange,BLPOP(阻塞版)等。
应用场景:
- 用户关注列表,新增一个关注在后面增加一个。
- 异步队列使用【将需要延后处理的任务结构体序列化成字符串进redis 的列表,另一个线程从这个列表中轮询数据进行处理】。
- 秒杀场景,秒杀前将本场秒杀的商品放到list中,因为list的pop操作是原子性的,所以即使有多个用户同时请求,也是依次pop,list空了pop抛出异常就代表商品卖完了.
实现方式:
4. Set
存储的是一堆不重复的无序数据,操作有添加,获取,移除单元素,检测是否存在元素,计算交集,并集,差集,从集合里随机获取元素等
set 的内部实现是一个 value永远为null的HashMap,实际就是通过计算hash的方式来快速排重的,这也是set能提供判断一个成员是否在集合内的原因。

常用命令:
sadd,srem,spop,sdiff ,smembers,sunion 等。
应用场景:
- 不可重复,但是value可以为null ,用在一些去重的场景,比如用户只能参加一次活动,一个用户只能中一次奖等等去重场景。还有就是求交集并集补集的场景。
实现方式:
- set内部实现是一个value永远为null的HashMap,实际就是通过hash的方式快速排重的。
5. Sort Set
set基础上增加了的顺序的特性,每一个value加入的时候带有一个分值以表示权重,
内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。

常用命令:
zadd,zrange,zrem,zcard等
应用场景:
- 排行榜功能,歌曲排行榜,播放次数,播放数,点赞数等等需要排序的场景。
- 实现时间轴列表功能
Sorted中score可以以时间作为排序条件,例如:奖池奖品按时间分布。twitter 的public timeline可以以发表时间作为score来存储,这样获取时就是自动按时间排好序的。
实现方式:
Redis sorted set的内部使用HashMap和跳跃表(SkipList)来保证数据的存储和有序,HashMap里放的是成员到score的映射,而跳跃表里存放的是所有的成员,排序依据是HashMap里存的score,使用跳跃表的结构可以获得比较高的查找效率,并且在实现上比较简单。
扩展:4种特殊数据结构
就这么多?除了以上五种数据结构,了解其他的数据结构吗?那是当然的还是有的!!!
多余的话不多说,今天给大家带来的是 Redis 中的四种特殊的数据结构 Bitmap,BloomFilter,GeoHash ,HyperLogLog。这四种数据结构其实有点类似于算法层面了,比如 GeoHash 其实就是一个 zset,bitmap 就是 string,只是使用的方法不同导致了更多的功能。
一:Bitmap( 位图)
常用命令:
-
setbit key index 0/1 设置某位的值
-
getbit key index 获取某位的值
-
bitcount key start end 获取指定范围内为1的数量
需要注意的是,这里的start 和 end是指的字符位置不是比特位置!!!包括下面的 bitpos 也是 -
bitpos key bit start end 获取第一个值为bit的从start到end字符索引范围的位置
-
bitop and/or/xor/not destkey key1 key2 对多个 bitmap 进行逻辑运算。
对于bitmap还有一个好玩的指令就是 bitfield ,这里我不做过多介绍,感兴趣的同学自己可以了解一下。
应用场景:
我们来思考一个比较有意思的场景,老板想让你统计一年内多个用户之间他们同时在线的天数,这个时候你怎么办?
你可能会想到使用 hash 存储,这太浪费空间了,有没有更好的办法呢?答案是有的,Redis 中使用了 bitmap位图。
如果有了这个我们是不是可以用来计算一个用户在指定时间内签到的次数?也就是一个位置代表一天,0代表未签到,1代表签到,在上图中,该用户在八天内签到了四次。
Redis 中的 bitmap 还提供了多个 bitmap 进行与,或,异或运算的命令,当然还有单个 bitmap 的 非 运算。这是不是给你提供了一点思路对于我们一开始的需求呢?
实现方式:

我们知道,字符串中一个字符是使用8个比特来表示的(如上图),在 Redis 中 bitmap 底层就是 string,也可以说 string 底层就是 bitmap。
二:BloomFilter( 布隆过滤器)
Bloom Filter 是 Redis 的扩展模块,所以需要额外下载!它是一种空间效率很高的随机数据结构,它利用位数组很简洁地表示一个集合,并能判断一个元素是否属于这个集合。Bloom Filter的这种高效是有一定代价的:在判断一个元素是否属于某个集合时,有可能会把不属于这个集合的元素误认为属于这个集合(false positive)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
常用命令:
bf.add key element 添加
bf.exists key element 判断是否存在
bf.madd key element1 element2 … 批量添加
bf.mexists key element1 element2 … 批量判断
应用场景:
比如我们进行网页爬虫,需要对爬过的 url 进行去重以避免爬到已经爬过的网站,如果我们使用 set 那么也就意味着我们需要将所有爬过的 url 放入集合中,假设一个 url 64字节,那么一亿个 url 意味着我们需要占用 6GB,十亿就是 60GB 左右。请注意,是内存!!!
比如这个时候我们要进行垃圾邮件或者垃圾短信的过滤,我们需要从数十亿个垃圾邮件列表或者垃圾电话列表中进行判断此时的邮件或者短信是否是垃圾的。如果我们此时使用 set 那么占用空间不用我多说了,也是 百GB级别 的。
上面的面试中我提到了 缓存穿透 ,用户故意请求数据库本来就不存在的(比如ID = -1),这个时候如果不做处理那么肯定会穿透缓存去查询数据库,一个查询还好,如果几千,几万个同时进来呢?你的数据库顶得住吗?那么此时我们使用 set 进行处理,占用那么多内存空间,你觉得值得吗???或者说,还有没有更好的方法了?
- 总结:
上面所讲的三个典型场景,网站去重,垃圾邮件过滤,缓存穿透 ,这三个只要使用 BloomFilter 就能完美解决。
实现方式:
下面我们具体来看Bloom Filter是如何用位数组表示集合的。初始状态时,Bloom Filter是一个包含m位的位数组,每一位都置为0。

为了表达S={x1, x2,…,xn}这样一个n个元素的集合,Bloom Filter使用k个相互独立的哈希函数(Hash Function),它们分别将集合中的每个元素映射到{1,…,m}的范围中。对任意一个元素x,第i个哈希函数映射的位置hi(x)就会被置为1(1≤i≤k)。注意,如果一个位置多次被置为1,那么只有第一次会起作用,后面几次将没有任何效果。在下图中,k=3,且有两个哈希函数选中同一个位置(从左边数第五位)。
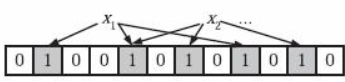
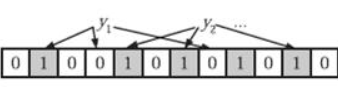
在判断y是否属于这个集合时,我们对y应用k次哈希函数,如果所有hi(y)的位置都是1(1≤i≤k),那么我们就认为y是集合中的元素,否则就认为y不是集合中的元素。下图中y1就不是集合中的元素。y2或者属于这个集合,或者刚好是一个false positive。
三:HyperLogLog
Redis 在 2.8.9 版本添加了 HyperLogLog 结构。
常用命令
-
Pfadd
将所有元素参数添加到 HyperLogLog 数据结构中
PFADD key-name element [element …]
如果至少有个元素被添加返回 1, 否则返回 0 -
Pfcount
PFCOUNT key [key …]
返回给定 HyperLogLog 的基数估算值
返回给定 HyperLogLog 的基数值,如果多个 HyperLogLog 则返回基数估值之和 -
Pgmerge
将多个 HyperLogLog 合并为一个 HyperLogLog ,合并后的 HyperLogLog 的基数估算值是通过对所有 给定 HyperLogLog 进行并集计算得出的
PFMERGE dest-key key [key …]
返回 OK
应用场景
举个栗子:假如我要统计网页的UV(浏览用户数量,一天内同一个用户多次访问只能算一次),传统的解决方案是使用Set来保存用户id,然后统计Set中的元素数量来获取页面UV。但这种方案只能承载少量用户,一旦用户数量大起来就需要消耗大量的空间来存储用户id。我的目的是统计用户数量而不是保存用户,这简直是个吃力不讨好的方案!而使用Redis的HyperLogLog最多需要12k就可以统计大量的用户数,尽管它大概有0.81%的错误率,但对于统计UV这种不需要很精确的数据是可以忽略不计的
实现方式
在真正介绍HyperLogLog算法之前,我们来回顾一个简单的概率论知识:
抛一个硬币,抛一次为反面的概率是1/2,抛两次都为反面的概率是1/4,抛三次都为反面的概率是1/8…依次类推,连续抛k次都是反面的概率1为2^(-k)。 因此,从概率论上来说,假如每一轮抛硬币的结果都不一样,我们最多尝试2^k轮就能抛出连续反面的情况。
HyperLogLog算法也是基于上面这个概率论知识,他认为:给定一系列的随机整数,我们可以通过这些随机整数的低位连续零位的最大长度 k,估算出随机数的数量,估算的公式为:n=2^k(n为随机数数量)。
四:GeoHash
Redis在3.2版本增加了GEO模板,意味着通过redis可以做附近的人,附近的门店,附近的商场这样的功能。
常用命令
1、增加
127.0.0.1:6379> geoadd company 116.48105 39.996794 juejin
(integer) 1
127.0.0.1:6379> geoadd company 116.514203 39.905409 ireader
(integer) 1
127.0.0.1:6379> geoadd company 116.489033 40.007669 meituan
(integer) 1
127.0.0.1:6379> geoadd company 116.562108 39.787602 jd 116.334255 40.027400 xiaomi
(integer) 2
也许你会问为什么 Redis 没有提供 geo 删除指令?前面我们提到 geo 存储结构上使用的是 zset,意味着我们可以使用 zset 相关的指令来操作 geo 数据,所以删除指令可以直接使用 zrem 指令即可。
2、距离
geodist 指令可以用来计算两个元素之间的距离,携带集合名称、2 个名称和距离单位。
127.0.0.1:6379> geodist company juejin ireader km
"10.5501"
127.0.0.1:6379> geodist company juejin meituan km
"1.3878"
127.0.0.1:6379> geodist company juejin jd km
"24.2739"
127.0.0.1:6379> geodist company juejin xiaomi km
"12.9606"
127.0.0.1:6379> geodist company juejin juejin km
"0.0000"
我们可以看到掘金离美团最近,因为它们都在望京。距离单位可以是 m、km、ml、ft,分别代表米、千米、英里和尺。
3、获取元素位置
geopos 指令可以获取集合中任意元素的经纬度坐标,可以一次获取多个。
127.0.0.1:6379> geopos company juejin
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
127.0.0.1:6379> geopos company ireader
1) 1) "116.5142020583152771"
2) "39.90540918662494363"
127.0.0.1:6379> geopos company juejin ireader
1) 1) "116.48104995489120483"
2) "39.99679348858259686"
2) 1) "116.5142020583152771"
2) "39.90540918662494363"
我们观察到获取的经纬度坐标和 geoadd 进去的坐标有轻微的误差,原因是 geohash 对二维坐标进行的一维映射是有损的,通过映射再还原回来的值会出现较小的差别。对于「附近的人」这种功能来说,这点误差根本不是事。
4、获取元素的 hash 值
geohash 可以获取元素的经纬度编码字符串,上面已经提到,它是 base32 编码。 你可以使用这个编码值去 geohash.org/${hash}中进行直… geohash 的标准编码值。
127.0.0.1:6379> geohash company ireader
1) "wx4g52e1ce0"
127.0.0.1:6379> geohash company juejin
1) "wx4gd94yjn0"
范围 20 公里以内最多 3 个元素按距离正排,它不会排除自身
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 asc
1) "ireader"
2) "juejin"
3) "meituan"
# 范围 20 公里以内最多 3 个元素按距离倒排
127.0.0.1:6379> georadiusbymember company ireader 20 km count 3 desc
1) "jd"
2) "meituan"
3) "juejin"
# 三个可选参数 withcoord withdist withhash 用来携带附加参数
# withdist 很有用,它可以用来显示距离
127.0.0.1:6379> georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc
1) 1) "ireader"
2) "0.0000"
3) (integer) 4069886008361398
4) 1) "116.5142020583152771"
2) "39.90540918662494363"
2) 1) "juejin"
2) "10.5501"
3) (integer) 4069887154388167
4) 1) "116.48104995489120483"
2) "39.99679348858259686"
3) 1) "meituan"
2) "11.5748"
3) (integer) 4069887179083478
4) 1) "116.48903220891952515"
2) "40.00766997707732031"
除了 georadiusbymember 指令根据元素查询附近的元素,Redis 还提供了根据坐标值来查询附近的元素,这个指令更加有用,它可以根据用户的定位来计算「附近的车」,「附近的餐馆」等。它的参数和 georadiusbymember 基本一致,除了将目标元素改成经纬度坐标值。
127.0.0.1:6379> georadius company 116.514202 39.905409 20 km withdist count 3 asc
1) 1) "ireader"
2) "0.0000"
2) 1) "juejin"
2) "10.5501"
3) 1) "meituan"
2) "11.5748"
应用场景
在一个地图应用中,车的数据、餐馆的数据、人的数据可能会有百万千万条,如果使用Redis 的 Geo 数据结构,它们将全部放在一个 zset 集合中。在 Redis 的集群环境中,集合 可能会从一个节点迁移到另一个节点,如果单个 key 的数据过大,会对集群的迁移工作造成 较大的影响,在集群环境中单个 key 对应的数据量不宜超过 1M,否则会导致集群迁移出现 卡顿现象,影响线上服务的正常运行。
所以,这里建议 Geo 的数据使用单独的 Redis 实例部署,不使用集群环境。
如果数据量过亿甚至更大,就需要对 Geo 数据进行拆分,按国家拆分、按省拆分,按 市拆分,在人口特大城市甚至可以按区拆分。这样就可以显著降低单个 zset 集合的大小。
实现方式
GeoHash算法将二维的经纬度数据映射到一维的整数,这样所有的元素都将挂载到一条线上,距离靠近的二维坐标映射到一维后的点之间距离会很接近。当我们想要计算附近的人时,首先将目标位置映射到这条线上,然后在这条一维的线上获取附近的点就ok了。
那这个映射算法具体是怎样的呢?它将整个地球看成一个二维平面,然后划分成了一系列正方形的方格,就好比围棋棋盘。所有的地图元素坐标都将放置于唯一的方格中。方格越小,坐标越精确。然后对这些方格进行整数编码,越是靠近的方格编码越是接近。那如何编码呢?一个最简单的方案就是切蛋糕法。设想一个正方形的蛋糕摆在你面前,二刀下去均分分成四块小正方形,这四个小正方形可以分别标记为 00,01,10,11 四个二进制整数。然后对每一个小正方形继续用二刀法切割一下,这时每个小小正方形就可以使用 4bit 的二进制整数予以表示。然后继续切下去,正方形就会越来越小,二进制整数也会越来越长,精确度就会越来越高。
编码之后,每个地图元素的坐标都将变成一个整数,通过这个整数可以还原出元素的坐标,整数越长,还原出来的坐标值的损失程度就越小。对于「附近的人」这个功能而言,损失的一点精确度可以忽略不计。
GeoHash算法会对上述编码的整数继续做一次base32编码(0 ~ 9,a ~ z)变成一个字符串。Redis中经纬度使用52位的整数进行编码,放进zset中,zset的value元素是key,score是GeoHash的52位整数值。在使用Redis进行Geo查询时,其内部对应的操作其实只是zset(skiplist)的操作。通过zset的score进行排序就可以得到坐标附近的其它元素,通过将score还原成坐标值就可以得到元素的原始坐标
总之,Redis中处理这些地理位置坐标点的思想是: 二维平面坐标点 --> 一维整数编码值 --> zset(score为编码值) --> zrangebyrank(获取score相近的元素)、zrangebyscore --> 通过score(整数编码值)反解坐标点 --> 附近点的地理位置坐标。
参考资料 & 致谢
【1】redis的五种数据结构及其使用场景
【2】Redis典型应用场景
【3】百度面试:如何使用Redis实现微信步数排行榜?
【4】Redis中bitmap的妙用
【5】Redis数据结构及各自适用场景
【6】Redis 精确去重计数 —— 咆哮位图
【7】redis使用场景及案例
【8】Redis不是只有5种基本数据类型?
【9】Redis 的 HyperLogLog