python超星尔雅学习通自动登录,自动批量下载课程资料
前言
最近超星尔雅开发上线了新版的登录系统,去掉了过去的验证码登录过程。于是就想着重新写段更简易的代码来实现标题上的内容。在这里写出相关功能实现的过程。以前实现这些功能一般都是用的selenium库利用chrome自动化解决,只需要涉及少量的前端就能写出代码,但是利用selenium在其他没有环境的电脑运行需要数百M的文件支持,并不具有通用性,所以这次尝试通过使用requests库解决这个问题,使代码更加通用化。
Chrome开发者工具抓包
访问超星尔雅最新的登录系统只需在requests.get原有登录网址时加上参数&newversion=true
浏览器访问可以直接输入网址http://passport2.chaoxing.com/login?fid=1467&refer=&newversion=true
首先在登录页面登录并进行抓包

除去不必要的数据,得到这五个结果
其中第一个是向http://passport2.chaoxing.com/getauthstatus请求获取登录二维码(三秒一刷新)
第二个是http://passport2.chaoxing.com/getauthstatus返回的二维码png图片
第三到第五个便是登录所需要的部分,首先对第三个进行分析

向http://passport2.chaoxing.com/fanyalogin发送post请求
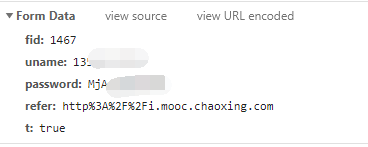
post的表单内容如上,fid为学校代号,uname为手机号,password是经过加密的密码,refer是指向的网址
回退至登录界面,在Chrome开发者工具全局搜索password

找到这里对password的加密是通过base64加密。
至此便通过基本的分析确认了超星尔雅登录所需要的内容,接下来就是进入pycharm实现自动登录并保持Session
Python自动登录并保持Session
本文所需要使用到的python库有:requests,js2py,re,base64,os
安装相关库
pip install requests
pip install js2py
pip install re
输入相关信息并进行整理
import requests
import js2py
import re
import base64
import os
import time
usernm = input("请输入手机号")
passwd = input("请输入密码")
schcode = input("请输入学校代码")
#转码成utf-8并进行base64加密
passwd = passwd.encode("utf-8")
code2 = base64.b64encode(passwd)
FormData = {
'fid': schcode,
'uname': usernm,
'password': code2,
'refer': 'http%3A%2F%2Fi.mooc.chaoxing.com',
't': 'true'
}
创建Session并POST请求
session = requests.session()
URL = "http://passport2.chaoxing.com/fanyalogin"
headers = {
'Referer': 'http://passport2.chaoxing.com/login?fid=1467&refer=&newversion=true',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
resp = session.post(URL, data=FormData, headers=headers)
获取返回Response Headers
cookie = requests.utils.dict_from_cookiejar(resp.cookies)
至此便完成了登录至超星尔雅并利用返回的cookies保持Session
获取所有课程并下载课程资料
由于超星网页的设计并不复杂,所以我在这里使用的是re正则表达式获取所需要的信息,同样可以选择使用BeautifulSoup库
抓包
接着同样进行分析获取课程列表的方式,在Chrome中点击“我的课程”后抓到的数据有

可以看出第一个就是我们获取课程列表的方式
Python获取所有课程
URL2 = "http://mooc1-1.chaoxing.com/visit/courses/study?isAjax=true&fileId=0&debug=true"
resp2 = requests.session().get(URL2, headers=headers, cookies=cookie)
webfile = resp2.text
raw_Result = re.findall("href='/mycourse/studentcourse\?courseId=(.*?)&vc=1&clazzid=(.*?)&enc=(.*?)' target=\"_blank\" title=\"(.*?)\">(.*?)</a>",webfile)
print("您有"+ str(len(raw_Result)) + "个课程")
批量自动下载所有课程文件资料
所有源码
import requests
import js2py
import re
import base64
import os
import time
class Mooc():
def login(self):
headers = {
'Referer': 'http://passport2.chaoxing.com/login?fid=1467&refer=&newversion=true',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
usernm = input("请输入手机号")
passwd = input("请输入密码")
schcode = input("请输入学校代码")
#转码成utf-8并进行base64加密
passwd = passwd.encode("utf-8")
code2 = base64.b64encode(passwd)
FormData = {
'fid': schcode,
'uname': usernm,
'password': code2,
'refer': 'http%3A%2F%2Fi.mooc.chaoxing.com',
't': 'true'
}
URL = "http://passport2.chaoxing.com/fanyalogin"
resp = requests.session().post(URL, data=FormData, headers=headers)
cookie = requests.utils.dict_from_cookiejar(resp.cookies)
self.get_classNames(cookie)
def get_classNames(self,cookie):
headers = {
'Referer': 'http://passport2.chaoxing.com/login?fid=1467&refer=&newversion=true',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
URL2 = "http://mooc1-1.chaoxing.com/visit/courses/study?isAjax=true&fileId=0&debug=true"
resp2 = requests.session().get(URL2, headers=headers, cookies=cookie)
webfile = resp2.text
# print(webfile)
raw_Result = re.findall("href='/mycourse/studentcourse\?courseId=(.*?)&vc=1&clazzid=(.*?)&enc=(.*?)' target=\"_blank\" title=\"(.*?)\">(.*?)</a>",webfile)
print("您有"+ str(len(raw_Result)) + "个课程")
t = 0
for item in raw_Result:
print(t,end="")
print("、" + item[3])
t += 1
num = int(input("请输入您要下载文件的课程编号"))
if num < len(raw_Result):
courseInfo = raw_Result[num]
self.load_ClassFile(courseInfo,cookie)
else:
print("输入有误")
self.get_classNames(cookie)
def load_ClassFile(self,courseInfo,cookie):
clinfo ={}
headers = {
'Referer': 'http://i.mooc.chaoxing.com/space/index?t=1593067396204',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
print(courseInfo)
isExists = os.path.exists(courseInfo[3])
if not isExists:
os.makedirs(courseInfo[3])
print("创建目录成功")
else:
print("目录已存在")
t = js2py.eval_js("new Date().getTime()")
t = str(t)
url = "http://i.mooc.chaoxing.com/space/index?t=" + t
resp = requests.session().get(url, headers=headers, cookies=cookie)
file = resp.text
s= re.findall('src="http://mooc1-1.chaoxing.com/visit/interaction\?s=(.*?)"',file)
url2 = 'http://mooc1-1.chaoxing.com/visit/interaction?s=' + s[0]
resp2 = requests.session().get(url2,headers=headers,cookies=cookie)
txt = resp2.text
cpi = re.findall("href='/mycourse/studentcourse\?courseId=" + courseInfo[0] + "&clazzid=" + courseInfo[1] + "&vc=1&cpi=(.*?)&enc=",txt)
cpi = cpi[0]
url3 = "http://mooc1-1.chaoxing.com/mycourse/studentcourse?courseId=" + courseInfo[0] + "&clazzid=" + courseInfo[1] + "&vc=1&cpi=" + cpi + "&enc=" + courseInfo[2]
resp3 = requests.session().get(url3,headers=headers,cookies=cookie)
txt = resp3.text
openc = re.findall("openc : '(.*?)'",txt)
openc = openc[0]
clinfo['courseId'] = courseInfo[0]
clinfo['clazzid'] = courseInfo[1]
clinfo['enc'] = courseInfo[2]
clinfo['cpi'] = cpi
clinfo['openc'] = openc
print(clinfo)
self.find_file(clinfo,cookie,courseInfo[3])
def find_file(self,clinfo,cookie,name):
path = name
datas = []
headers = {
'Referer': 'http://i.mooc.chaoxing.com/space/index?t=1593067396204',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
url = "https://mooc1-1.chaoxing.com/coursedata?classId="+clinfo['clazzid']+"&courseId="+clinfo['courseId']+"&type=1&ut=s&enc="+clinfo['enc']+"&cpi="+clinfo['cpi']+"&openc="+clinfo['openc']
resp = requests.session().get(url,headers=headers,cookies=cookie)
cookie2 = requests.utils.dict_from_cookiejar(resp.cookies)
cookie.update(cookie2)
print(cookie)
info = resp.text
fls = re.findall("οnclick=\"toOpen\('(.*?)','(.*?)',(.*?),",info)
if len(fls) != 0:
for item in fls:
if item[1] == "afolder":
self.find_folders(headers,cookie,clinfo,path+"\\"+item[0],item[0],item[2])
else:
self.batchdownload(item[0],item[2],path+"\\"+item[0],cookie,clinfo)
else:
print("无资料")
def find_folders(self,headers,cookie,clinfo,path,name,id):
datas = []
isExists = os.path.exists(path)
if not isExists:
os.makedirs(path)
print("创建目录成功")
else:
print("目录已存在")
url2 = "https://mooc1-1.chaoxing.com/coursedata?courseId=" + clinfo['courseId'] + "&dataId=" + id + "&type=1&parent=[]&flag=0&classId=" + clinfo['clazzid'] + "&enc=" + clinfo['enc'] + "&ut=s&cpi=" + \
clinfo['cpi'] + "&openc=" + clinfo['openc']
resp2 = requests.session().get(url2, headers=headers, cookies=cookie)
file = resp2.text
files = re.findall("toOpen\('(.*?)','(.*?)',(.*?),", file)
for choice in files:
if choice[1] == "afolder":
self.find_folders(headers,cookie,clinfo,path+"\\"+choice[0],choice[0],choice[2])
else:
self.batchdownload(choice[0],choice[2],path+"\\"+choice[0],cookie,clinfo)
def batchdownload(self,name,data,path,cookie,clinfo):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
url = 'https://mooc1-1.chaoxing.com/coursedata/batchDownload?dataId=' + data +'&courseId='+clinfo['courseId']+'&classId='+clinfo['clazzid']+'&ut=s'
resp = requests.session().get(url,headers=headers,cookies=cookie)
file = resp.text
print(file)
link = re.findall("https://cs-ans\.chaoxing\.com/download/(.*?)",file)
print(link)
link = link[0]
url2="https://cs-ans.chaoxing.com/download/"+ link
try:
down_res = requests.get(url=url2, headers=headers,cookies=cookie)
with open(path, "wb") as code:
code.write(down_res.content)
print("下载" + name + "完成")
except:
time.sleep(5)
self.batchdownload(name,data,path,cookie,clinfo)
if __name__ == '__main__':
mooc = Mooc()
mooc.login()
整段代码直接复制可用
在选择完课程开始下载课程文件资料的过程中会出现有持续五秒左右的卡顿情况,这是正常情况,是服务器自动的断开连接行为,代码中的设定是五秒后尝试重新连接。
整段代码运行时间长短取决于网络状况与课程资料数量
代码运行结果:


