监控学习算法-回归问题-梯度下降法及其改进算法
前言
监控学习-回归,supervised learning,就是说,给你一些training set训练集,然后呢,每一组训练集都有x1,x2,…xn这些输入变量,同时还会给出对应的结果y(咱们这里就先讨论single output).然后需要你依据这些数据,对新的数据列表进行判断,给出算法认为的y。(其他的监控学习还有classification)
预估函数
对于已经给定的training set,咱们需要拟合出一个函数,这个函数呢,需要尽可能的贴合training set。我们不妨称之为预估函数H。
很显然,对于预估函数H的选择上可以有线性函数,或者是二次函数,以及更多。咱们这次介绍的梯度下降算法,不挑H是哪种函数类型。
代价函数
其实代价函数cost function就是描述,在预估函数为前提下,将training set输入到H中得到的输出,与原y的误差表达。这里的误差表达通常是选择平方差的和,当然也有其他表达方式。
通俗的理解代价函数,即预估函数得出的y与实际y的误差表达。
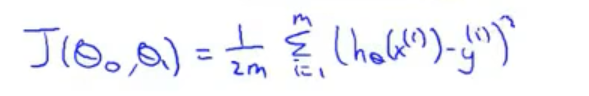
算法目的
咱们搞了这么久,究竟是要干嘛?以H函数为一次函数为例,H = Theta0 + Theta1*x,代价函数J(Theta0, Theta1),希望求得的Theta0与Theta1使得代价函数J最小。
梯度下降算法 gradient descent
原理非常简单,即对所有模型参数Theta-i求偏导后,乘上learning rate-α,最后作为差值更新到原始Theta-i上。
首先选择一组数值作为Theta-i的初始值。
然后不断通过梯度下降方式更新Theta-i,注意是同时更新。
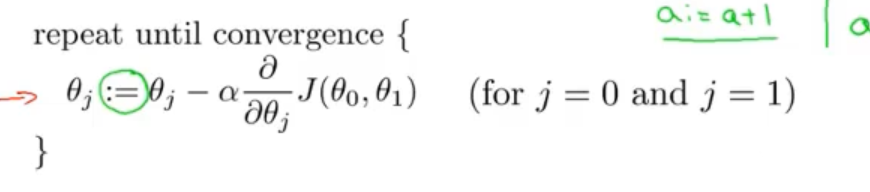

经过不断迭代后,查看J值–迭代次数曲线,若发现曲线经过快速下降后趋于稳定,则可停止迭代,成功退出。
梯度下降算法的优缺点
很显然,learning rate-α的选择是一件让人觉得麻烦的事情。如果选择过大,则可能在全局最优解处发生震荡甚至发散;如果选择过小,确实不会错过全局或者局部最优解,但迭代速度就太慢了。另外,针对不同的训练数据,可能需要不同的α。这就更僵硬了。
其次,这个方法需要代价函数是凸函数。
否则,梯度下降算法得到的最优解很有可能是局部最优解。
当然优点也有(得有个比较对象),比如,它可以允许输入非常多的特征量。
batch gradient descent, stochastic gradient descent, mini-batch gradient descent
这么多类型的梯度下降算法?咱们稍微花点时间区分一下。
batch gradient descent批量梯度下降算法
正如上文所说的那样,梯度算法中对所有training set都参与到计算过程中。
stochastic gradient descent随机梯度下降算法
在每次更新时用1个样本,随机也就是说我们用样本中的一个例子来近似我所有的样本,来调整θ,因而随机梯度下降是会带来一定的问题。因为计算得到的并不是准确的一个梯度,对于最优化问题,凸问题,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。但是相比于批量梯度,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的,所以这个方法用的也比上面的多。
mini-batch gradient descent最小梯度下降算法
在每次更新时用b个样本,其实批量的梯度下降就是一种折中的方法,他用了一些小样本来近似全部的,其本质就是我1个指不定不太准,那我用个30个50个样本那比随机的要准不少了吧。而且批量的话还是非常可以反映样本的一个分布情况的。在深度学习中,这种方法用的是最多的,因为这个方法收敛也不会很慢,收敛的局部最优也是更多的可以接受。
改进算法
部分引自CSDN@史丹利复合田,侵删。
momentum动量算法
这个算法对梯度下降算法的改进还是非常直观的。想象一下,之前的梯度下降算法,从A点计算得到下降梯度后,计算并更新走到了B点,然后继续迭代。可是迭代的过程中,前后两次是没有任何关联的。这种迭代过程因此变得更加曲折且缓慢。
于是引入动量算法,将迭代过程中新点的诞生过程中加入上一次的梯度结果的部分。

上图直观的解释了动量法的全部内容。
新点梯度对旧点梯度的依赖需要有一个衰减值γ\gammaγ ,推荐取0.9。这样的做法可以让早期的梯度对当前梯度的影响越来越小,如果没有衰减值,模型往往会震荡难以收敛,甚至发散。
Nesterov accelerated gradient (NAG)算法
这个算法又是对momentum动量算法的改进。想想,动量算法在B点处,将上一个点A的梯度*某个系数,与当前B点的梯度,做矢量相加,诞生了下一个点。
既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什么不先按照历史梯度往前走那么一小步,然后再从这个超前点处,继续按照自己的梯度再走一步呢?

NAG方法收敛速度明显加快。波动也小了很多。实际上NAG方法用到了二阶信息,所以才会有这么好的结果。
Adagrad自适应学习率调整算法
Adadelta的特点是在下降初期,梯度比较小,这时学习率会比较大,而到了中后期,接近最低点时,梯度较大,这时学习率也会相对减小,放慢速度,以便可以迭代到最低点。
假设梯度为gt,那么在使用Adagrad时并非直接减去gt*γ,而是先对学习率进行一个处理:
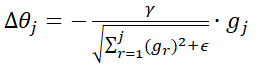
即把所有的梯度的平方根,作为一个正则化约束项,加上ε的作用是为了避免分母为0,同时这也是调控全局学习率的手段。
缺点:由公式可以看出,仍依赖于人工设置一个全局学习率ε设置过大的话,会使regularizer过于敏感,对梯度的调节太大;中后期,分母上梯度平方的累加将会越来越大,使使得训练提前结束。