1. 什么是模块?
模块就是一系列功能的集合体, 分为三大类:
1. 内置模块 (python解释器提供的, 用C语言编写的模块)
2. 自定义模块 (可以是python, C 或 C++写的)
一个python文件本身就是一个模块, 文件名m.py, 模块名m
3. 第三方模块
模块其实分为四个通用类别,分别是:(关注1和3)
1、使用纯Python代码编写的py文件
2、包含一系列模块的包 (把一系列模块组织到一起的文件夹, 文件夹下有一个__init__.py文件, 该文件夹称为包)
3、使用C编写并链接到Python解释器中的内置模块
4、使用C或C++编译的扩展模块
2. 为何要有模块?
内置与第三方模块拿来就可以用, 无需定义, 这可以极大地提高开发效率.
自定义模块:
可以将程序的各部分功能提取出来放到一个模块中为大家共享使用, 好处是减少代码冗余, 程序组织结构更加清晰.
3. 如何用模块?
1. import 模块名
foo.py代码如下:
print('模块foo>>>') x = 1 def get(): print(x) def change(): global x x = 0 print(x)
run.py代码如下:
import foo
x = 111
y = 222 foo.get() foo.change() ''' 结果: 模块foo>>> 1 0 '''
原理图如下:

x = 000 y = 111 z = 222 import foo ''' 1. 首次导入模块会发生的三件事: 1. 执行foo.py 2. 产生foo.py的名称空间, 将foo.py运行过程中产生的名字丢到foo的名称空间中 3. 在当前文件中产生产生一个名字foo, 该名字指向2中产生的名称空间. 之后的导入, 都是引用首次导入产生的名称空间, 不会重复执行代码. ''' # 2. 引用 print(foo.x) # 结果: 1 print(foo.login) # 结果: <function login at 0x0000018A359C1488> ''' 强调1: 模块名.名字, 是指明道姓地问某一个模块要名字对应的值, 不会与当前名称空间冲突. 强调2: 无论查看还是修改, 操作的都是模块本身, 以定义模块为准, 与调用位置无关. ''' # 3. 补充 # 可以一行一行地写, 也可以用逗号隔开, 写在同一行, 但是不推荐写在同一行, 示例: # import time # import foo # import m # import time, foo, m # 4. 导入模块的规范 # 1. python内置模块 # 2. 第三方模块 # 3. 程序员自定义模块 # 5. import...as... # 给导入的模块起个别名, 示例: # import foo as f # 当模块名比较长, 用起来比较麻烦时可以采用这种方法 # 6. 模块是第一类对象 # 可以当作返回值, 可以当作容器类数据的元素... # 7. 自定义模块的命名应该采用纯小写加下划线的风格(python3), python2中有些采用驼峰体的格式 # 8. 可以在函数内导入模块, 如果是在全局导入, 则导入的模块可以在全局使用, 如果在函数内导入, 则导入的模块只能在局部使用
一个py文件的两种用途:
1. 当作py文件运行
2. 当作模块被导入
每个py文件都内置有__name__, 当该文件被运行时, __name__的值为__main__, 当该文件被当作模块导入时, __name__的值为__模块名__.
注意: 输 if __name__ == '__main__': 的快捷方式为: 输入main, 然后按回车键即可.
import 导入模块在使用时必须加前缀:
优点: 肯定不会与当前名称空间中的名字冲突.
缺点: 加前缀显得麻烦.
2. from...import...
from...import...导入发生的三件事:
1. 产生一个模块的名称空间
2. 运行foo.py将运行过程中产生的名字都丢到模块的名称空间中去
3. 在当前名称空间拿到一个名字, 该名字对应模块名称空间中的某一个内存地址
优点: 代码更精简
缺点: 容易与当前名称空间混淆
补充:
1. 可以在同一行导入多个名字, 示例:
from foo import x, get, change
不推荐使用以上方法
2. *导入模块中的所有名字, 大多数情况下都不要使用这种情况
from foo import *
3. 被导入的模块中默认内置有__all__, __all__中存放的是字符串格式的名字的列表,
__all__ = ['x', 'get', 'change']
可以用__all__控制*代表的名字有哪些
4. from foo import get as g
以上方法是针对get起别名
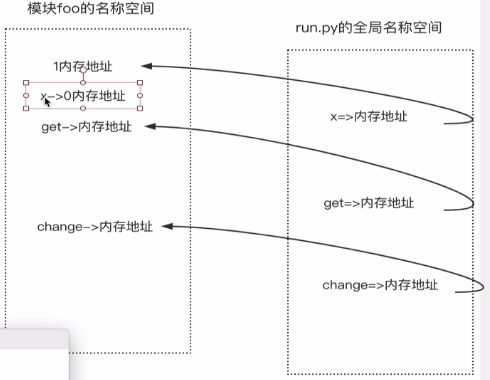
foo.py的代码如下:
print('模块foo>>>') x = 1 def get(): print(x) def change(): global x x = 0 print(x) __all__ = ['x', 'get'] # 可以用它控制*代表的名字有哪些
run.py的代码:
from foo import x from foo import get as g # 将get重命名为g from foo import change print(x) # 结果: 1 g() # 结果: 1 change() # 结果: 0 print(x) # 结果: 1 # from foo import * # print(change) # 结果: NameError: name 'change' is not defined
原理图如下:
4. 循环导入
循环导入, 如从m1导入m2, 从m2导入m1, 会导致报错.
解决方案一: 将名字前提
解决方案二: 如果导入的模块是给某个功能用的, 那么就不要在全局导入.
不过, 不推荐使用循环导入的方式.
5. 模块查找优先级
无论是import还是from...import...在导入模块时都涉及到查找问题
查找优先级:
1. 内存(内置模块)
2. 硬盘: 按照sys.path中存放的文件的顺序依次查找要导入的模块
可以通过sys.modules查看已经加载到内存中的模块.
导入的模块, 通过del不能从内存中删除; 在函数中导入的模块, 函数运行完毕后, 也不会从内存中回收.
如果导入模块不在sys.path中, 即导入模块与执行文件不在同一路径下, 则会报错, 为了避免这一问题, 可以采用以下方法将导入模块的路径追加到sys.path中.
import sys sys.path.append(r'F:\python全栈开发\python\day21\aa') # 注意: 这里追加的是aa文件夹的路径, 这种方法是临时加的. import mm mm.login()
6. 编写规范的模块
编写一个模块时最好按照统一的规范去编写,如下:
#!/usr/bin/env python #通常只在类unix环境有效,作用是可以使用脚本名来执行,而无需直接调用解释器。 "The module is used to..." #模块的文档描述 import sys #导入模块 x=1 #定义全局变量,如果非必须,则最好使用局部变量,这样可以提高代码的易维护性,并且可以节省内存提高性能 class Foo: #定义类,并写好类的注释 'Class Foo is used to...' pass def test(): #定义函数,并写好函数的注释 'Function test is used to…' pass if __name__ == '__main__': #主程序 test() #在被当做脚本执行时,执行此处的代码
7. 函数的类型提示
# 函数类型提示 def register(name:str, hobbies:'必须传入元祖', age:int = 18, )->'int': print(name) print(age) print(hobbies) return 111 register('egon', ('篮球', '足球')) # 函数定义阶段, 对参数进行注释, 并对返回结果进行注释, 添加注释并不影响函数的运行. print(register.__annotations__) # 结果: {'name': <class 'str'>, 'hobbies': '必须传入元祖', 'age': <class 'int'>, 'return': 'int'}