快速排序算法是分治法的一个典型实例,也是冒泡排序的改进,算法的思维逻辑也挺容易理解的。
算法思路
我个人把快速排序思路分成以下的三个部分:
1. 基准数的选取,一般来说我们把数组(或者分区)的第一个数作为基准数
2. 将比基准数大的都放置在它的右边,将比基准数小的都放置在它的左边,以基准数为分界线,原来的数组被分成了左右两个分区
3.左右两个分区 分别重复步骤1,2,直到每个分区中只有一个数
思路就是这么多话糙理不糙,下面解释一下这三个步骤的意义,还有是如何实现的。
算法实现图解
原数组如下
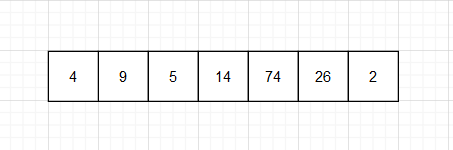
1 .取准基数
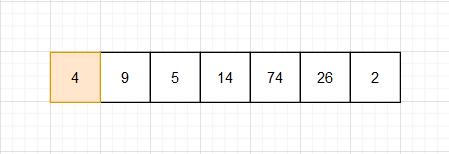
2. 我们如何实现基数左边都比基数小,右边都比它大呢?
(1)设置高位(high)和低位(low)
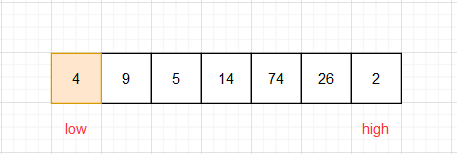
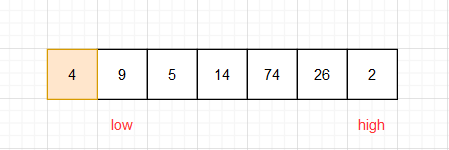
(2)先从high端开始
若high对应数组中的数大于或等于基准数,high –
若high对应数组中的数小于准基数,high位置不动,
接下来我们再从low端开始
若low对应数组中的数小于或等于准基数,low++
若low对应数组中的数大于准基数,low位置不动,
此时数组
(3)交换高位和低位中的数,
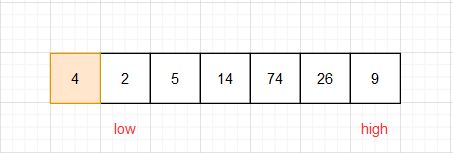
(4) 重复执行(2)(3)直到高位与低位相等,这里注意每次都是high先走。
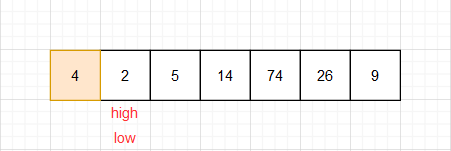
(5)此时high和low现在的位置就是准基数在有序数组中的位置,把准基数和low(heig)位置的数调换,此时会发现比4大的都在4的后面,比4小的都在4的前面
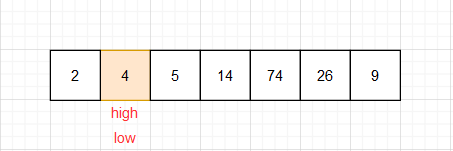
- 由上图所示,4后面的称为右分区,4前面的成为左分区。右分区随便取一个数肯定大于左分区的任意一个数。由于左分区只有一个数就不在进行操作。下面的步骤基本上都是重复步骤1 和步骤 2,左右分区分别选取准基数,在分区内把小于准基数的放置左边,大于准基数的放置右边 ,分区内再分区,一直到所有的分区都为一个数为止。粉红色是被选过为基准数的数
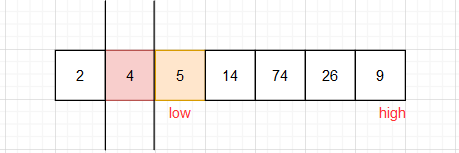
最后结果
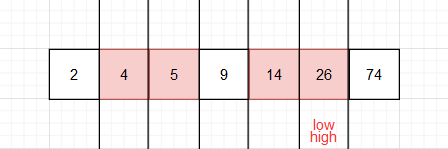
分治思想就体现在此。每次分区都是右分区大于左分区,最终有多少个数就会有多少个分区,每个分区只有一个数,自左向右分区递增,数组自然也就排好序了。
代码实现
public class QuickSort {
public void Quick_Sort(int[]arr ,int begin,int end) {
//合法性判断
if (begin > end) {
return;
}
//基数的选取
int temp = arr[begin];
int i = begin;
int j = end;
//当i=j时,我们就找到基数应有的位置了
//当i != j 我们就要一直不停的找
while(i != j) {
while(arr[j] >= temp &&j > i)
j--;
while(arr[i] <= temp &&j > i)
i++;
if (j > i) {
int t = arr[i];
arr[i] = arr[j];
arr[j] = t;
}
}
//基数交换到应该的位置
arr[begin] = arr[i];
arr[i] = temp;
Quick_Sort(arr, begin, i - 1);
//end的作用体现在递归调用本身
Quick_Sort(arr, i + 1, end);
}
}
代码中有些需要注意的地方,因为方法要递归调用本身,所以合法性判断必不可少,即什么时候不进入此方法。内部while循环中要加j > i 的判断,为了防止某种情况,比如beg一直加直到比end还大,可能会导致溢出异常。还有一种情况是如果不加限制的话,while(arr[j] >= temp &&j > i)中 j不断的自减,直到准基数应放的位置,但是这时外层的while循环还没完,接着执行内部的第二个while循环,如果不加限制 i 一直自加会错过j 的位置 ,导致外层while捕捉不到i == j 的循环结束条件。
快速排序的平均时间复杂度也是:O(nlogn)和堆排序一样,但是堆排序数据交换次数比快速排序多,在数据较多的情况下,还是快速排序效率更高一些。