一、一致性hash算法
对我们有什么启发?
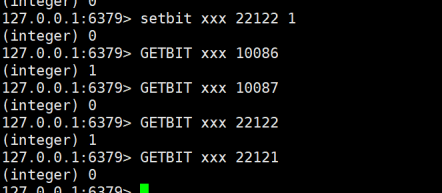
一致性hash,本质就是把数据分散在(2^32-1) 圆形的槽里面!
假设我们的(2^32-1) 每个槽里面,只存储一个bit,那我们占用的内存之后
(2^32)-1 bit 大
1 个int = 4 个byte
1 个byte = 8bit
1 int = 32 个bit
二、问题的引入?
怎么判断1亿 数据里面是否存在某个数据?要求算法的复杂度,控制在常数范围内!
14亿人身份证号码,怎么快速判断某个身份证号码在这个里面?
2.1 解决方案1 HashSet
把14亿个字符串存在在HashSet 里面,使用HashSet的 判断是否存在某个值解决
2.2 解决方案2 TreeSet 里面
把14亿个字符串存在在TreeSet 里面,使用TreeSet 的 判断是否存在某个值解决

速度问题:使用Hash>>Tree
占用空间问题:若14个值都存储满,占用大小基本是一样的!
2.3 使用集合存储字符串数据的优缺点
优点:非常简单,我们可以直接是HashSet 来存储
缺点:当我们的数据量约大,它的存储的数据将无法估量,可能导致JVM 内存的移除
HashSet 和TreeSet 直接存储字符串占用的内存太大了,我们需要去选择别的结构了
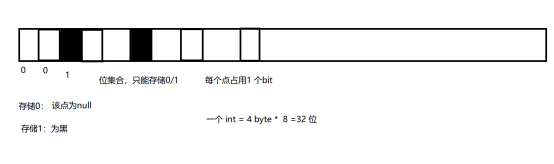
三、引入位集合
3.1 图示
3.2 特点
集合里面只能存储0/1 ,
每个点都占用1 个bit

四、Hash
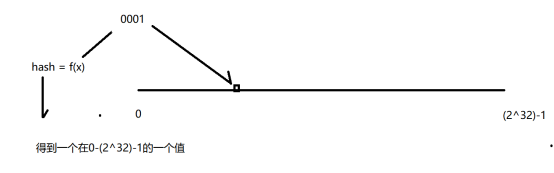
4.1 hash
什么叫hash?
Hash 就是为把某个值,映射在一个有序的长度上面,得到一个映射值
4.2 hash 和hashCode
在一段长度的位置值

和HashCode的关系:
HashCode 不等于该位置的值,
HashCode 一般是个非常特殊的值,是通过一个质数做变化得来的?

该值不容易重复,该值算出来可以很多!
什么是位置的pos:
位置的值,不等于hashCode 的值:
比如我们的长度有20 ,但是你的hashCode 是100 ;
我们没有放下你,需要一个变化?
怎么把hashCode 值变成一个Pos的值?
Int pos = getPos(hashCode);
Int pos(){
Int pos = hashCode & (len-1) ;
}
通过该方法我们可以把任意的hashCode 映射在我们的固定长度位置上面
4.3 怎么解决Hash 冲突的问题
有2 个值,他们的hash值/pos值都是相同的?
Hash冲突怎么搞?
4.3.1 拉链法解决
就是HashMap 里面的解决思路
4.3.2 二次hash
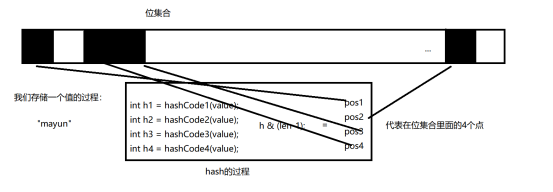
我们若计算出来该值的hash 和之前的值有冲突,我们使用另一个hashCode函数在计算hashCode,得的不同的pos ,有新的pos
4.3.3 跳跃法


五、使用位集合存在字符串,并且判断该字符串是否存储在该位集合里面
5.1 思维导图
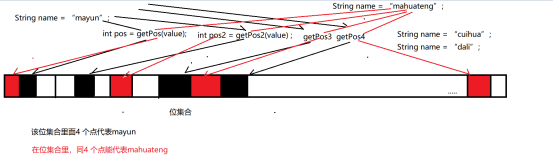
5.2 将上面的图,使用代码表示出来
5.3.1 新建HashCodeFun
public class HashCodeFun {
/**
* 质数,计算hashCode值的关键
*/
private int seed ;
public HashCodeFun(int seed){
this.seed = seed ;
}
/**
* 给一个value ,计算该value的hashCode
* @param value
* @return
*/
public int hashCodeFun(String value) {
char[] chars = value.toCharArray();
int h = 0;
if (h == 0 && chars.length > 0) {
char val[] = chars;
for (int i = 0; i < chars.length; i++) {
h = seed * h + val[i];
}
}
return h;
}
}
5.3.2 新建Quesion类
public class Question {
/**
* 位集合的长度
*/
private int len = 32 ;
/**
* 创建一个位集合
*/
private BitSet bitSet = new BitSet(len) ;
private int []seeds = new int[]{31,37,41,43};
private HashCodeFun[] hashCodeFuns = new HashCodeFun[4] ;
{
for (int i = 0; i < seeds.length; i++) {
hashCodeFuns[i] = new HashCodeFun(seeds[i]) ;
}
}
/**
* 往位集合里面设置一个值
* @param value
*/
public void addValue(String value){
for (HashCodeFun hashCodeFun : hashCodeFuns) { // 循环hashCode的方法
int hashCode = hashCodeFun.hashCodeFun(value); // 通过质数计算HashCode的值
int pos = hashCode & (len-1) ;
System.out.println(pos);
bitSet.set(pos,true);
}
}
/**
* 怎么判断该位集合里是否存在某个值
* 1 判断集合里面的代表该value的4 个点
*/
public boolean existValue(String value){
for (HashCodeFun hashCodeFun : hashCodeFuns) {
int hashCode = hashCodeFun.hashCodeFun(value);
int pos = hashCode & (len-1) ;
if(!bitSet.get(pos)){ // 若该位集合上面的该点,没有被占用,
return false ; // 有一个点不符合
}
}
return true ;
}
public static void main(String[] args) {
Question question = new Question();
question.addValue("mayun");
// question.addValue("mahuateng");
System.out.println(question.existValue("mahuateng"));
// System.out.println(question.existValue("mahuateng"));
}
}
5.3 hash 函数的本质是是啥?
Hash过程的本质是啥:
Hash函数的本质在于特征的提取
做人脸识别:鼻子 + 嘴巴 + 耳朵 + 眼睛
鼻子 = Hash1(人脸);
嘴巴 = Hash2(人脸);
耳朵 = Hash3(人脸);
眼睛 = Hash4(人脸);
假设我们的hash函数可以做一个特征的提取,
利用高斯函数叠加:得到一个具体的特征
你的脸和刘德华的脸:
对比你们2个的鼻子,嘴巴,耳朵,眼睛
在人脸识别里面,需要一个特征的提取,在把字符串映射在位集合上,它的本质也是提取字符串某个特征!
5.4 我们上面使用位集合存储值,并且判断位集合里面是否有值,属于BloomFilter的算法
5.6 作业
5.6.1 把今天Mycat的高可用测试成功
5.6.2 使用位集合存储值,并且判断值是否有,这个算法实现了
5.6.3 使用Redis 来实现我们上面写的BloomFilter这个算法
提示:
1 bitset 在jvm的内存里面,无法和别的jvm 共享
2 bitset 太大了,可能会占用内存!
使用Redis 使用BloomFilter
在redis 里面有个数据结构:BitMap

5.6.4 BitMap的结构

5.6.5 bitMap的操作