
Hadoop主要解决问题
存 大量的存 HDFS
算 大量的算 MapReduce
优势:
高可靠性
高扩展性
高效性 MapReduce 使得并行执行运算
高容错性 自动失败的任务重新分配
Hadoop1.x 和 Hadoop2.x区别
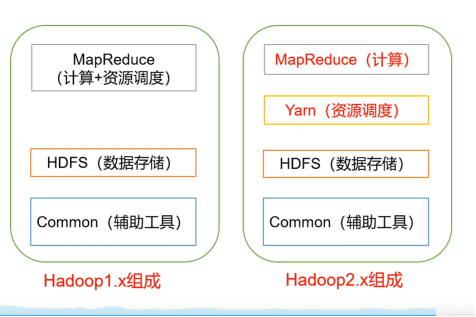
实现计算与调度解耦 Yarn不但可以调度MapReduce 还可以调度其他资源
HDFS架构
NameNode(nn) 存储文件的元数据(文件名,文件目录结构,文件属性)
DataNode(dn) 存储数据本身
Secondary NameNode(2nn) nn的好助手/替身
Yarn架构 调度CPU和内存资源分配
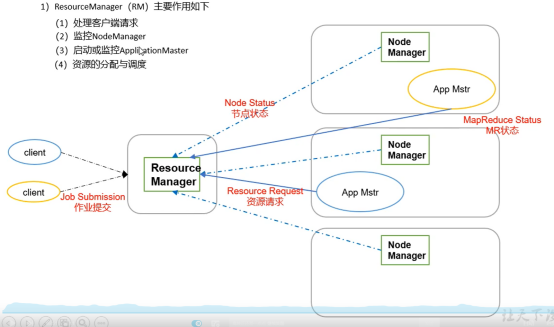
ResourceManager(RM)(主管,负责从客户端接项目 然后安排人员 监控人员)
1处理客户端请求
2监控NodeManager
3启动并监控ApplicationMaster
4资源的分配和调度
NodeManager(NM)(项目组的程序员 负责具体干活的人)
1管理单个节点的资源
2执行ResourceManager的命令
3执行ApplicationMaster的命令
ApplicationMaster(跟进具体项目的临时负责人,项目结束打包离职)
1负责数据切分
2负责为应用程序申请资源
3任务的监控和容错
Container容器(物资)
是资源的抽象 封装了多维度资源(内存,cpu,磁盘,网络等) 由NodeManager使用
MapReduce架构
MapReduce将计算分为两阶段 Map 和 Reduce
大数据生态体系
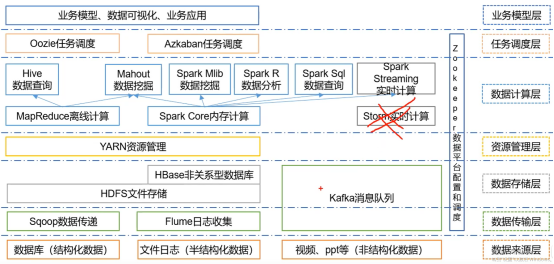
大数据分析过程

最终用户画像 和 产品聚类
Zookeeper在整个过程中充当润滑剂
集群搭建:正常六台机器
NN一台 DN+NM共三台 2NN一台 RM一台
HDFS —Hadoop Distributed File System
适合一次写入 多次读出 且不支持文件修改
优点:
高容错性:多副本机制
适合处理大量数据
可构建在廉价机器上
缺点:
不适合低延迟数据访问
不适合存储大量小文件:因为NameNode空间是有限的。小文件寻址时间远超过读写时间
不支持并发写入,文件随便修改
HDFS架构
NameNode
DataNode
Client
将文件切分成一个个的block然后上传
Secondary NameNode
辅助分担NameNode
HDFS文件分块Block: 默认128M
寻址时间/读取时间 规范 1/100
设置的文件块太小-导致寻址时间过长
设置文件快太大-文件处理会很慢
HDFS上传过程
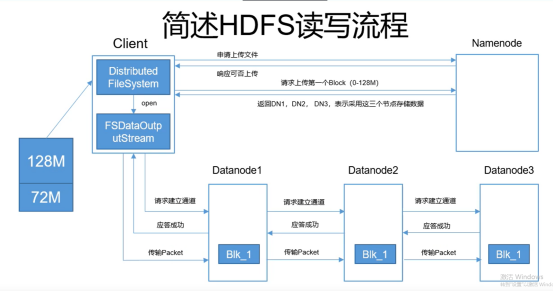
(1) 建立一个客户端Client,输入流读取本地文件,输出流上传文件
(2) 向NameNode发送申请上传,经过审核(上传路径是否正确,是否有权限)得到响应是否可上传
(3) 将本地文件逻辑切分,128M分一块
(4) 请求上传第一个Block块,返回n个节点数的DataNodeList(n为DataNode副本数量),选出离客户端最近的DataNode作第一个,该DataNode再选出其他的DataNode。
(5) 按顺序发送DataNode请求建立通道,请求建立通道,请求建立通道
(6) 按顺序返回应答成功,应答成功,应答成功
(7) 按顺序传输packet,传输packet,传输packet
(8) 传完第一个块 再重新找DataNode重复(5)-(7)步骤
(9) NameNode更新元数据
传输packet过程中不是完全串行的,客户端发给DN1,DN1还没落入磁盘就继续发送packet给DN2,然后继续发给DN3. 从DN3开始逐个返回成功,最后返给客户端成功
如果中途请求建立通道或相应应答失败了,则文件传输失败
如果第一个DataNode的传输packet失败了,那么文件传输失败。
如果后边DataNode的传输packet失败了,前边的DataNode会再找新DataNode补齐
HDFS下载过程
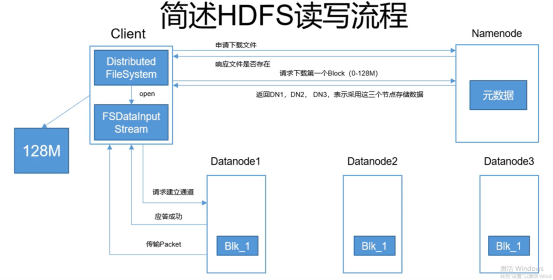
也是一个块一个块的读
当一个DataNode能满足提供一个块 其他DataNode副本就不会再给了
NameNode
元数据内存持久化
Fsimage 类似于Redis的RDB 记录了某一刻内存的 负责将磁盘恢复到内存
edits.log 类似于Redis的AOF 记录的每一步的操作 负责NameNode内存持久化到磁盘
NameNode服务器启动 先加载Fsimage 再加载edit.loB
存入新数据 存入edits.log 再由2NN合并入Fsimage
2NN作为秘书 把edits.log整合到Fsimage
询问NameNode 是否需要CheckPoint,
触发条件:
(1) 定时时间到
(2) Edits的数据满了
整合步骤:
(1) NN同意整合CheckPoint,然后将edits和Fsimage发给2NN
(2) 2NN根据edits保存的指令,整理出新的Fsimage发回NN
(3) NN创建新的edits存指令,旧的edits不会删,旧的Fsimage会删
DataNode存储
存储块的数据 存储块的元数据(数据长度,校验和,时间戳)
(1) DN启动后向NameNode注册
(2) 注册成功后,以后每周期(一小时)上报所有块信息
(3) 每3秒一次心跳,心跳返回结果带有NameNode返给DataNode。NN超过十分钟没有接到心跳则认为DN挂了。
DataNode扩展集群
退役旧DataNode节点
添加白名单 用来保证集群安全性 白名单外一律不允许连接NameNode
黑名单退役 用来退役 放入黑名单安乐死 还有心跳但是没他事了
MapReduce 分布式运算程序的框架
优点:简单
简单,易编程
良好扩展性,加机器扩展运算能力
高容错性,一个机器挂了 放别的机器算,只要不是所有机器全挂了就不会失败
海量数据离线处理
缺点: 慢
不擅长实时计算
不擅长流式计算 MapReduce输入的数据是静态的 文件块 不支持动态流式计算
不擅长有向图计算 后一个输入是前一个输出的有向图计算,由于MapReduce的计算结果都要落入磁盘,导致有向图计算会产生大量IO效率特别低
Map阶段
将数据映射为想要的KEY-V形式 <word,1>
Reduce阶段
再将数据进行合并处理 <word,n>
MrAppMaster
MapTask
ReduceTask
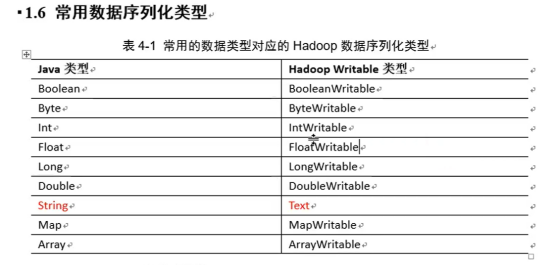
代码三部分:
WcMapper
WcReducer
WcDriver
未完待更新 !
Hadoop常用命令:
全开启
start-all.sh等价于start-dfs.sh + start-yarn.sh
hadoop fs -ls / hadoop下查看所有目录
hadoop fs -mkdir /aaa hadoop下创建目录
查看指定目录内容
hdfs dfs –ls [文件目录]
打开某个已存在文件
hdfs dfs -cat [path]
本地文件存入hadoop
hdfs dfs -put [hadoop目录] [本地地址]
将hadoop文件down到本地已有目录
hadoop dfs -get [hadoop目录] [本地目录]
删除hadoop上指定文件
hdfs dfs -rm [文件地址]
hadoop上创建新目录
hdfs dfs -mkdir [目录名]