本博客运行环境为jupyter下python3.6
完成对口罩佩戴与否的模型训练,采取合适的特征提取方法,输出模型训练精度和测试精度(F1-score和ROC);完成一个摄像头采集自己人脸、并能实时分类判读(输出分类文字)的程序。
环境搭建可参看上一篇博客:https://blog.csdn.net/weixin_44436677/article/details/107171190
图片预处理
把数据集中的图片人脸部分裁剪下来。记得修改路径为自己的路径哦。
import dlib # 人脸识别的库dlib
import numpy as np # 数据处理的库numpy
import cv2 # 图像处理的库OpenCv
import os
# dlib预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')
# 读取图像的路径
path_read = "data"
for file_name in os.listdir(path_read):
#aa是图片的全路径
aa=(path_read +"/"+file_name)
#读入的图片的路径中含非英文
img=cv2.imdecode(np.fromfile(aa, dtype=np.uint8), cv2.IMREAD_UNCHANGED)
#获取图片的宽高
img_shape=img.shape
img_height=img_shape[0]
img_width=img_shape[1]
# 用来存储生成的单张人脸的路径
path_save="maskdata"
# dlib检测
dets = detector(img,1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
if len(dets)>1:
continue
# 计算矩形大小
# (x,y), (宽度width, 高度height)
pos_start = tuple([d.left(), d.top()])
pos_end = tuple([d.right(), d.bottom()])
# 计算矩形框大小
height = d.bottom()-d.top()
width = d.right()-d.left()
# 根据人脸大小生成空的图像
img_blank = np.zeros((height, width, 3), np.uint8)
for i in range(height):
if d.top()+i>=img_height:# 防止越界
continue
for j in range(width):
if d.left()+j>=img_width:# 防止越界
continue
img_blank[i][j] = img[d.top()+i][d.left()+j]
img_blank = cv2.resize(img_blank, (200, 200), interpolation=cv2.INTER_CUBIC)
cv2.imencode('.jpg', img_blank)[1].tofile(path_save+"/"+file_name) # 正确方法
导入数据集
划分完成后,导入数据集。
代码如下:
import keras
import os, shutil
train_havemask_dir="maskdata/train/mask/"
train_nomask_dir="maskdata/train/nomask/"
test_havemask_dir="maskdata/test/mask/"
test_nomask_dir="maskdata/test/nomask/"
validation_havemask_dir="maskdata/validation/mask/"
validation_nomask_dir="maskdata/validation/nomask/"
train_dir="maskdata/train/"
test_dir="maskdata/test/"
validation_dir="maskdata/validation/"
创建模型
代码如下:
#创建模型
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
查看模型:
model.summary()
运行结果如下:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
归一化处理
代码如下:
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
from keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
validation_datagen=ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 目标文件目录
train_dir,
#所有图片的size必须是150x150
target_size=(150, 150),
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(test_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
for data_batch, labels_batch in train_generator:
print('data batch shape:', data_batch.shape)
print('labels batch shape:', labels_batch)
break
运行结果如下:
data batch shape: (20, 150, 150, 3)
labels batch shape: [1. 0. 1. 1. 0. 0. 0. 1. 1. 1. 0. 1. 0. 1. 1. 1. 1. 1. 1. 1.]
训练模型
代码如下:
#耗时长
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=10,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/10
100/100 [==============================] - 193s - loss: 0.6154 - acc: 0.6549 - val_loss: 0.6509 - val_acc: 0.6232
Epoch 2/10
100/100 [==============================] - 200s - loss: 0.5477 - acc: 0.7081 - val_loss: 0.6028 - val_acc: 0.6909
Epoch 3/10
100/100 [==============================] - 196s - loss: 0.5202 - acc: 0.7367 - val_loss: 0.5616 - val_acc: 0.7091
Epoch 4/10
100/100 [==============================] - 193s - loss: 0.4634 - acc: 0.7823 - val_loss: 0.6193 - val_acc: 0.7081
Epoch 5/10
100/100 [==============================] - 196s - loss: 0.4220 - acc: 0.8102 - val_loss: 0.5991 - val_acc: 0.7283
Epoch 6/10
100/100 [==============================] - 195s - loss: 0.3705 - acc: 0.8356 - val_loss: 0.6040 - val_acc: 0.7350
Epoch 7/10
100/100 [==============================] - 195s - loss: 0.3219 - acc: 0.8683 - val_loss: 0.6424 - val_acc: 0.7000
Epoch 8/10
100/100 [==============================] - 195s - loss: 0.2609 - acc: 0.9069 - val_loss: 0.6127 - val_acc: 0.7273
Epoch 9/10
100/100 [==============================] - 195s - loss: 0.2125 - acc: 0.9285 - val_loss: 0.6427 - val_acc: 0.7434
Epoch 10/10
100/100 [==============================] - 200s - loss: 0.1617 - acc: 0.9514 - val_loss: 0.8757 - val_acc: 0.7354
保存模型:
#保存模型
model.save('maskAndNomask1.h5')
数据增强
代码如下:
#数据增强
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
数据增强前后对比:
import matplotlib.pyplot as plt
from keras.preprocessing import image
fnames = [os.path.join(train_havemask_dir, fname) for fname in os.listdir(train_havemask_dir)]
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150, 150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()
运行结果如下:

创建网络
代码如下:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
归一化处理,代码如下:
#归一化处理
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# This is the target directory
train_dir,
# All images will be resized to 150x150
target_size=(150, 150),
batch_size=32,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=60,
validation_data=validation_generator,
validation_steps=50)
运行结果如下:
Found 838 images belonging to 2 classes.
Found 455 images belonging to 2 classes.
Epoch 1/60
100/100 [==============================] - 297s - loss: 0.6391 - acc: 0.6322 - val_loss: 0.6658 - val_acc: 0.6079
Epoch 2/60
100/100 [==============================] - 283s - loss: 0.5988 - acc: 0.6793 - val_loss: 0.6506 - val_acc: 0.6203
Epoch 3/60
100/100 [==============================] - 282s - loss: 0.5931 - acc: 0.6762 - val_loss: 0.5824 - val_acc: 0.6675
……
Epoch 57/60
100/100 [==============================] - 291s - loss: 0.3750 - acc: 0.8291 - val_loss: 0.4794 - val_acc: 0.7751
Epoch 58/60
100/100 [==============================] - 291s - loss: 0.3761 - acc: 0.8281 - val_loss: 0.4979 - val_acc: 0.8007
Epoch 59/60
100/100 [==============================] - 287s - loss: 0.3793 - acc: 0.8331 - val_loss: 0.5010 - val_acc: 0.7934
Epoch 60/60
100/100 [==============================] - 285s - loss: 0.3772 - acc: 0.8321 - val_loss: 0.5664 - val_acc: 0.7370
保存模型:
model.save('maskAndNomask2.h5')
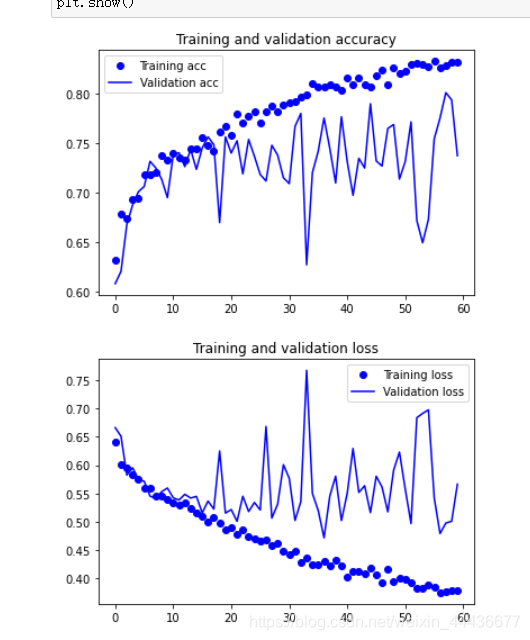
绘制训练集与验证集的准确度与损失率的图像
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
运行结果如下:
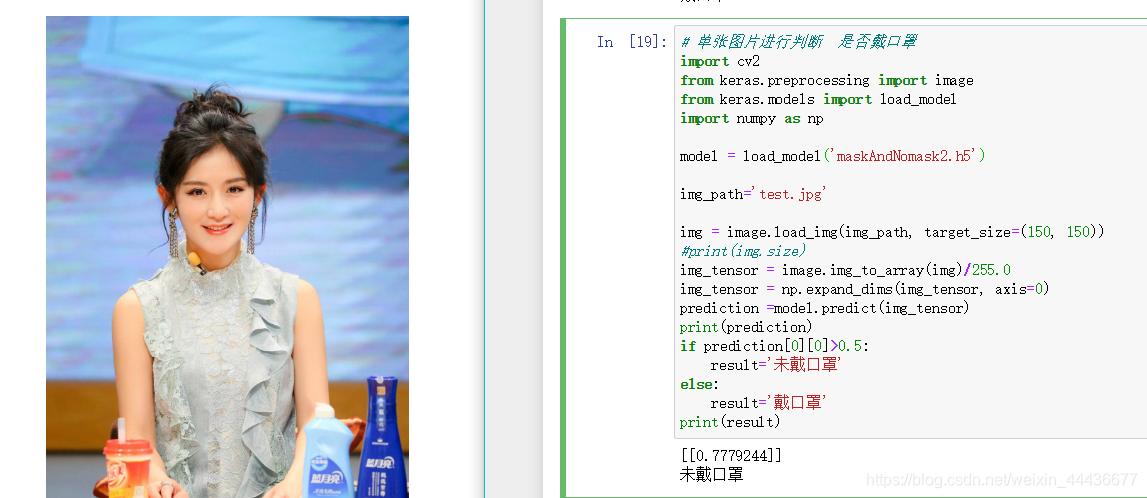
单张图片测试
# 单张图片进行判断 是否戴口罩
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
model = load_model('maskAndNomask2.h5')
img_path='masktest.jpg'
img = image.load_img(img_path, target_size=(150, 150))
#print(img.size)
img_tensor = image.img_to_array(img)/255.0
img_tensor = np.expand_dims(img_tensor, axis=0)
prediction =model.predict(img_tensor)
print(prediction)
if prediction[0][0]>0.5:
result='未戴口罩'
else:
result='戴口罩'
print(result)
运行结果如下:
我测试了两张图片,记得改为自己的模型文件和测试图片哦。

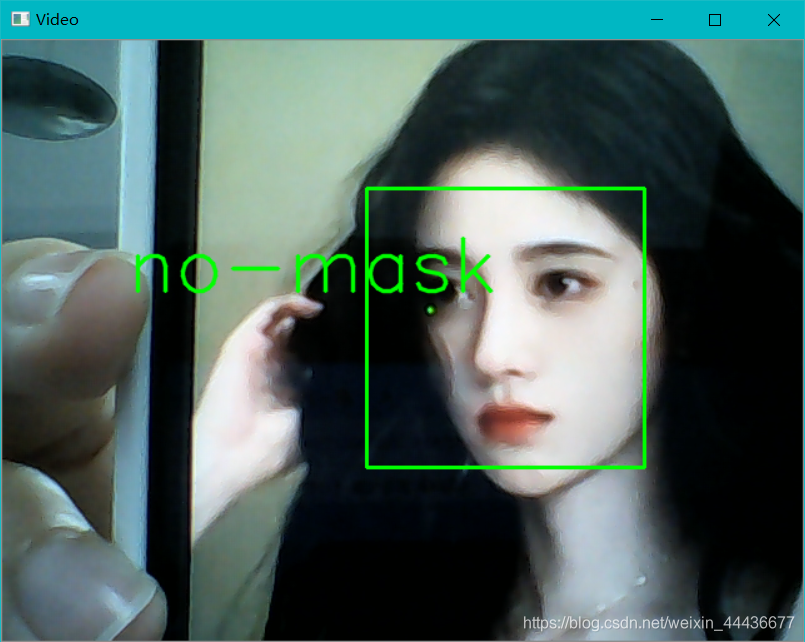
摄像头实时测试
代码如下:
import cv2
from keras.preprocessing import image
from keras.models import load_model
import numpy as np
import dlib
from PIL import Image
model = load_model('maskAndNomask2.h5')
detector = dlib.get_frontal_face_detector()
# video=cv2.VideoCapture('media/video.mp4')
# video=cv2.VideoCapture('data/face_recognition.mp4')
video=cv2.VideoCapture(0)
font = cv2.FONT_HERSHEY_SIMPLEX
def rec(img):
gray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
dets=detector(gray,1)
if dets is not None:
for face in dets:
left=face.left()
top=face.top()
right=face.right()
bottom=face.bottom()
cv2.rectangle(img,(left,top),(right,bottom),(0,255,0),2)
def mask(img):
img1=cv2.resize(img,dsize=(150,150))
img1=cv2.cvtColor(img1,cv2.COLOR_BGR2RGB)
img1 = np.array(img1)/255.
img_tensor = img1.reshape(-1,150,150,3)
prediction =model.predict(img_tensor)
if prediction[0][0]>0.5:
result='no-mask'
else:
result='have-mask'
cv2.putText(img, result, (100,200), font, 2, (0, 255, 0), 2, cv2.LINE_AA)
cv2.imshow('Video', img)
while video.isOpened():
res, img_rd = video.read()
if not res:
break
#将视频每一帧传入两个函数,分别用于圈出人脸与判断是否带口罩
rec(img_rd)
mask(img_rd)
#q关闭窗口
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video.release()
cv2.destroyAllWindows()
运行结果如下: