Hello, you will now learn about two major concepts of preprocessing. The first thing you’ll learn about is called stemming and the second thing you will learn about is called stop words, and specifically you will learn how to use stemming and stop words to preprocess your texts. Let’s take a look at how you can do this.
你好,现在你将学习预处理的两个概念。你要学习的第一件事叫做stemming(词干分析),第二件事叫做stop words(停用词),具体来说,你要学习如何使用词干分析和停用词来预处理你的文本。让我们看看如何做到这一点。
Let’s process this tweet. First I remove all the words that don’t significant meaning to the tweets, aka stop words and punctuation marks. In practice, you would have to compare your tweetagainst two lists. One with stop words in Englisth and another with punctuation. These lists are usually much larger, but for the purpose of this example, they will do just fine. Every word from the tweet that also appears on the list of stop words should be eliminated. So you’d have to eliminate the word “and”, the word “are”, the word “a”, and the word “at”. The tweet without stop words look like this. Note that the overall meaning of the sentence could be inferred without eny effort.
让我们处理下这条推特。首先我移除所有对推特没有重要意义的单词,又称停用词和标点符号。在实践中,你必须将推特与两个列表进行比较。一个带有英文的停用词,另一个带有标点符号。这些列表通常是比较大的,但对于本例的目的来说,它们就足够了。推特中的每个单词也出现在停用词的列表中应该被消除。所以必须要消除单词"and"、“are”、“a”、“at”。没有停用词的推特像这个。请注意,这个句子的整体意思可以毫不费力地推断出来。

Now, let’s eliminate every punctuation mark. In this example, there are only excalmation points. The tweet without stop words and punctuation looks like this. However, note that in some contexts you won’t have to eliminate punctuation. So you should think carefully about whether punctuation adds important information to your specific NLP task or not.
现在,让我们消除所有的标点符号。在这个例子中,仅仅只有感叹号。没有停用词和标点符号的推特像这样。然而,请注意在一些上下文你不必消除标点。所以你应该认真思考标点是否添加了重要的信息到你制定的NLP任务中。

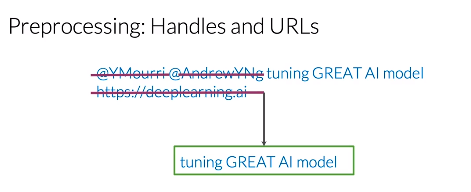
Tweets and other types of texts often have handles and URLs, but these don’t add any value for the task of sentiment analysis. Let’s eliminate these two handles and this URL. At the end of this process, the resulting tweets contains all the important information related to its sentiment. Tuning GREAT AI model is clearly a positive tweet and a sufficiently good model should be able to classify it.
推特和其他类型的文本经常有handle和url,但这对情感分析任务没有任何价值。让我们消除这两个@和这条url。在这个过程的最后,产生的推特包含所有与其情感相关的重要信息。"调整伟大的人工智能模型"显然是一个积极的推特,一个足够好的模型应该能够分类它。
Now that the tweet from example has only the necessary information, I will perform stemming for every word. Stemming in NLP is simply transforming any word to its base stem, which you could define as the set of characters that are used to construct the word and its derivatives. Let’s take the first word from the example. Its stem is done, because adding the letter “e”, it forms the word “tune”. Adding the suffix “ed”, forms the word “tuned”, and adding the suffix “ing”, it forms the word “tuning”. After you perform stemming on your corpus, the word “tune”, “tuned”, and “tuning” will be reduced to the stem “tun”. So your vocabulary would be significantly reduced when you perform this process for every word in the corpus. To reduce your vocabulary even further without losing valuable informatin, you’d have to lowercase every one of your words. So the word “GREAT”, “Great” and “great” would be treated as the same exact word. This is the final preprocess tweet as a list of words.
既然示例上的推特仅仅只有必要的信息,我将对每个单词进行词干提取。NLP中的词干提取只是将任何单词转换为它的基本词干,你可以将基本词干定位为用于构造词及其派生的一组字符。看下示例中的第一个词。它的词干已经完成了,因为添加一个字母"e",就组成了单词"tune"。添加后缀"ed",就组成单词"tuned",添加后缀"ing",就组成单词"tuning"。在你对语料库执行词干分析之后,单词"tune"、“tuned"和"tuning"会转化为"tun”。因此,当你对语料库中的每个单词执行这个过程时,你的词汇量将会显著减少。为了进一步减少你的词汇量而又不丢失有价值的信息,你必须把每个单词都小写。所以单词"GREAT","Great"和"great"将被视为完全相同的单词。这是最后的预处理推特作为单词列表。

Now that you’re familiar with stemming and stop words, you know the basics of texts processing.
现在你已经熟悉了词干提取和停用词,你也了解了文本处理的基础知识。