口罩识别,是指可以有效检测在密集人流区域中携带和未携戴口罩的所有人脸,同时判断该者是否佩戴口罩。通常由两个功能单元组成,可以分别完成口罩人脸的检测和口罩人脸的分类。
本次实践相比生产环境中口罩识别的问题,降低了难度,仅实现人脸口罩判断模型,可实现对人脸是否佩戴口罩的判定。本实践旨在通过一个口罩识别的案列,让大家理解和掌握如何使用飞桨动态图搭建一个经典的卷积神经网络
(此实践也可替换为其他类型的分类)
#加载需要的模型
import os
import zipfile
import random
import json
import paddle
import sys
import numpy as np
from PIL import Image
from PIL import ImageEnhance
import paddle.fluid as fluid
from multiprocessing import cpu_count
import matplotlib.pyplot as plt
from paddle.fluid.dygraph.base import to_variable
#飞桨安装:python -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
'''
参数配置
'''
train_parameters = {
"input_size": [3, 224, 224], #输入图片的shape
"class_dim": -1, #分类数,这里为两类,戴口罩不戴口罩
"src_path":"/home/aistudio/work/maskDetect.zip",#原始数据集路径
"target_path":"/home/aistudio/data/", #要解压的路径
"train_list_path": "/home/aistudio/data/train.txt", #train.txt路径
"eval_list_path": "/home/aistudio/data/eval.txt", #eval.txt路径
"readme_path": "/home/aistudio/data/readme.json", #readme.json路径
"label_dict":{}, #标签字典
"num_epochs":35, #训练轮数
"train_batch_size": 8, #训练时每个批次的大小
"learning_strategy": { #优化函数相关的配置
"lr": 0.001 #超参数学习率
}
}
一、数据准备
(1)解压原始数据集
(2)按照比例划分训练集与验证集
(3)乱序,生成数据列表
(4)构造训练数据集提供器和验证数据集提供器
#定义解压函数
def unzip_data(src_path,target_path):
'''
解压原始数据集,将src_path路径下的zip包解压至data目录下
'''
if(not os.path.isdir(target_path + "maskDetect")):
z = zipfile.ZipFile(src_path, 'r')
z.extractall(path=target_path)
z.close()
def get_data_list(target_path,train_list_path,eval_list_path):
'''
生成数据列表
'''
#存放所有类别的信息
class_detail = []
#获取所有类别保存的文件夹名称
data_list_path=target_path+"maskDetect/"
class_dirs = os.listdir(data_list_path)
#总的图像数量
all_class_images = 0
#存放类别标签
class_label=0
#存放类别数目
class_dim = 0
#存储要写进eval.txt和train.txt中的内容
trainer_list=[]
eval_list=[]
#读取每个类别,['maskimages', 'nomaskimages']
for class_dir in class_dirs:
if class_dir != ".DS_Store":
class_dim += 1
#每个类别的信息
class_detail_list = {}
eval_sum = 0
trainer_sum = 0
#统计每个类别有多少张图片
class_sum = 0
#获取类别路径
path = data_list_path + class_dir
# 获取所有图片
img_paths = os.listdir(path)
for img_path in img_paths: # 遍历文件夹下的每个图片
name_path = path + '/' + img_path # 每张图片的路径
if class_sum % 10 == 0: # 每10张图片取一个做验证数据
eval_sum += 1 # test_sum为测试数据的数目
eval_list.append(name_path + "\t%d" % class_label + "\n")
else:
trainer_sum += 1
trainer_list.append(name_path + "\t%d" % class_label + "\n")#trainer_sum测试数据的数目
class_sum += 1 #每类图片的数目
all_class_images += 1 #所有类图片的数目
# 说明的json文件的class_detail数据
class_detail_list['class_name'] = class_dir #类别名称,如jiangwen
class_detail_list['class_label'] = class_label #类别标签
class_detail_list['class_eval_images'] = eval_sum #该类数据的测试集数目
class_detail_list['class_trainer_images'] = trainer_sum #该类数据的训练集数目
class_detail.append(class_detail_list)
#初始化标签列表
train_parameters['label_dict'][str(class_label)] = class_dir
class_label += 1
#初始化分类数
train_parameters['class_dim'] = class_dim
#乱序
random.shuffle(eval_list)
with open(eval_list_path, 'a') as f:
for eval_image in eval_list:
f.write(eval_image)
random.shuffle(trainer_list)
with open(train_list_path, 'a') as f2:
for train_image in trainer_list:
f2.write(train_image)
# 说明的json文件信息
readjson = {}
readjson['all_class_name'] = data_list_path #文件父目录
readjson['all_class_images'] = all_class_images
readjson['class_detail'] = class_detail
jsons = json.dumps(readjson, sort_keys=True, indent=4, separators=(',', ': '))
with open(train_parameters['readme_path'],'w') as f:
f.write(jsons)
print ('生成数据列表完成!')
def custom_reader(file_list):
'''
自定义reader
'''
#图像预处理
def reader():
with open(file_list, 'r') as f:
lines = [line.strip() for line in f]
for line in lines:
img_path, lab = line.strip().split('\t')
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
yield img, int(lab)
return reader
'''
参数初始化
'''
src_path=train_parameters['src_path']
target_path=train_parameters['target_path']
train_list_path=train_parameters['train_list_path']
eval_list_path=train_parameters['eval_list_path']
batch_size=train_parameters['train_batch_size']
'''
解压原始数据到指定路径
'''
unzip_data(src_path,target_path)
'''
划分训练集与验证集,乱序,生成数据列表
'''
#每次生成数据列表前,首先清空train.txt和eval.txt
with open(train_list_path, 'w') as f:
f.seek(0)
f.truncate()
with open(eval_list_path, 'w') as f:
f.seek(0)
f.truncate()
#生成数据列表
get_data_list(target_path,train_list_path,eval_list_path)
'''
构造数据提供器
'''
train_reader = paddle.batch(custom_reader(train_list_path),
batch_size=batch_size,
drop_last=True)
eval_reader = paddle.batch(custom_reader(eval_list_path),
batch_size=batch_size,
drop_last=True)
二、模型配置
VGG的核心是五组卷积操作,每两组之间做Max-Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。由于每组内卷积层的不同,有11、13、16、19层这几种模型,。
#此处定义的为一个新的层,卷积+池化层
class ConvPool(fluid.dygraph.Layer):
'''卷积+池化'''
def __init__(self,
num_channels,
num_filters,
filter_size,
pool_size,
pool_stride,
groups,
pool_padding=0,
pool_type='max',
conv_stride=1,
conv_padding=1,
act=None):
super(ConvPool, self).__init__()
self._conv2d_list = []
self.num_filters = num_filters
for i in range(groups):
conv2d = self.add_sublayer( #返回一个由所有子层组成的列表。
'bb_%d' % i,
fluid.dygraph.Conv2D(
num_channels=num_channels, #通道数
num_filters=num_filters, #卷积核个数
filter_size=filter_size, #卷积核大小
stride=conv_stride, #步长
padding=conv_padding, #padding大小,默认为0
act=act)
)
num_channels=num_filters
self._conv2d_list.append(conv2d)
self.batchnorm = fluid.BatchNorm(num_filters)
self._pool2d = fluid.dygraph.Pool2D(
pool_size=pool_size, #池化核大小
pool_type=pool_type, #池化类型,默认是最大池化
pool_stride=pool_stride, #池化步长
pool_padding=pool_padding #填充大小
)
def forward(self, inputs):
x = inputs
for conv in self._conv2d_list:
x = conv(x)
if self.num_filters == 256:
x = self.batchnorm(x)
x = self._pool2d(x)
return x
class VGGNet(fluid.dygraph.Layer):
'''
VGG网络
'''
def __init__(self):
super(VGGNet, self).__init__()
self.hidden1=ConvPool(3,64,3,2,2,2,act='relu')
self.hidden2=ConvPool(64,128,3,2,2,2,act='relu')
self.hidden3=ConvPool(128,256,3,2,2,3,act='relu')
self.hidden4=ConvPool(256,512,3,2,2,3,act='relu')
self.hidden5=ConvPool(512,512,3,2,2,3,act='relu')
#ConPool(num_channels,num_filters,filter_size,pool_size,pool_stride, groups, act='relu)
self.pool_5_shape = 512*7*7
self.fc1=fluid.dygraph.Linear(self.pool_5_shape,4096,act="relu")
self.fc2=fluid.dygraph.Linear(4096,4096,act="relu")
self.fc3=fluid.dygraph.Linear(4096,2,act="softmax")
def forward(self, inputs, label=None):
"""前向计算"""
x=self.hidden1(inputs)
x=self.hidden2(x)
x=self.hidden3(x)
x=self.hidden4(x)
x=self.hidden5(x)
x=fluid.layers.reshape(x,shape=[-1,512*7*7])
x=self.fc1(x)
x=self.fc2(x)
x=self.fc3(x)
if label is not None:
acc=fluid.layers.accuracy(input=x,label=label)
return x,acc
else:
return x
三、模型训练
all_train_iter=0
all_train_iters=[]
all_train_costs=[]
all_train_accs=[]
def draw_train_process(title,iters,costs,accs,label_cost,lable_acc):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel("cost/acc", fontsize=20)
plt.plot(iters, costs,color='red',label=label_cost)
plt.plot(iters, accs,color='green',label=lable_acc)
plt.legend()
plt.grid()
plt.show()
def draw_process(title,color,iters,data,label):
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=20)
plt.ylabel(label, fontsize=20)
plt.plot(iters, data,color=color,label=label)
plt.legend()
plt.grid()
plt.show()
'''
模型训练
'''
#with fluid.dygraph.guard(place = fluid.CUDAPlace(0)):
with fluid.dygraph.guard():
print(train_parameters['class_dim'])
print(train_parameters['label_dict'])
vgg = VGGNet()
stdall = 0
meanall = 0
optimizer=fluid.optimizer.MomentumOptimizer(momentum = 0.9,learning_rate=train_parameters['learning_strategy']['lr'],parameter_list=vgg.parameters(),regularization=fluid.regularizer.L2DecayRegularizer(regularization_coeff=0.1))
for epoch_num in range(train_parameters['num_epochs']):
for batch_id, data in enumerate(train_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int64')
y_data = y_data[:, np.newaxis]
#将Numpy转换为DyGraph接收的输入
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out,acc = vgg(img,label)
loss = fluid.layers.cross_entropy(out, label)
avg_loss = fluid.layers.mean(loss)
#使用backward()方法可以执行反向网络
avg_loss.backward()
optimizer.minimize(avg_loss)
#将参数梯度清零以保证下一轮训练的正确性
vgg.clear_gradients()
all_train_iter=all_train_iter+train_parameters['train_batch_size']
all_train_iters.append(all_train_iter)
all_train_costs.append(loss.numpy()[0])
all_train_accs.append(acc.numpy()[0])
if batch_id % 1 == 0:
print("Loss at epoch {} step {}: {}, acc: {}".format(epoch_num, batch_id, avg_loss.numpy(), acc.numpy()))
draw_train_process("training",all_train_iters,all_train_costs,all_train_accs,"trainning cost","trainning acc")
draw_process("trainning loss","red",all_train_iters,all_train_costs,"trainning loss")
draw_process("trainning acc","green",all_train_iters,all_train_accs,"trainning acc")
#保存模型参数
fluid.save_dygraph(vgg.state_dict(), "vgg")
print("Final loss: {}".format(avg_loss.numpy()))
四、模型评估
'''
模型校验
'''
with fluid.dygraph.guard():
model, _ = fluid.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
accs = []
for batch_id, data in enumerate(eval_reader()):
dy_x_data = np.array([x[0] for x in data]).astype('float32')
y_data = np.array([x[1] for x in data]).astype('int')
y_data = y_data[:, np.newaxis]
img = fluid.dygraph.to_variable(dy_x_data)
label = fluid.dygraph.to_variable(y_data)
out, acc = vgg(img, label)
lab = np.argsort(out.numpy())
accs.append(acc.numpy()[0])
print(np.mean(accs))
五、模型预测
def load_image(img_path):
'''
预测图片预处理
'''
img = Image.open(img_path)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize((224, 224), Image.BILINEAR)
img = np.array(img).astype('float32')
img = img.transpose((2, 0, 1)) # HWC to CHW
img = img/255 # 像素值归一化
return img
label_dic = train_parameters['label_dict']
'''
模型预测
'''
with fluid.dygraph.guard():
model, _ = fluid.dygraph.load_dygraph("vgg")
vgg = VGGNet()
vgg.load_dict(model)
vgg.eval()
#展示预测图片
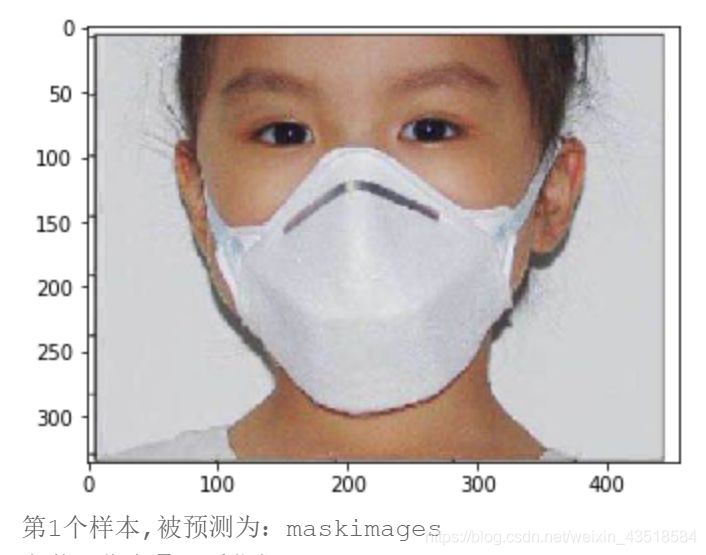
infer_path='/home/aistudio/data/111.jpg'
img = Image.open(infer_path)
plt.imshow(img) #根据数组绘制图像
plt.show() #显示图像
#对预测图片进行预处理
infer_imgs = []
infer_imgs.append(load_image(infer_path))
infer_imgs = np.array(infer_imgs)
for i in range(len(infer_imgs)):
data = infer_imgs[i]
dy_x_data = np.array(data).astype('float32')
dy_x_data=dy_x_data[np.newaxis,:, : ,:]
img = fluid.dygraph.to_variable(dy_x_data)
out = vgg(img)
lab = np.argmax(out.numpy()) #argmax():返回最大数的索引
print("第{}个样本,被预测为:{}".format(i+1,label_dic[str(lab)]))