需求驱动
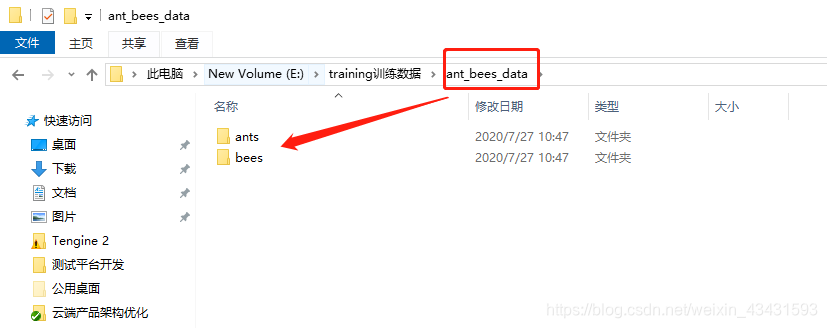 如图,我有2个数据集,但文件大小总共45M,我要测试如下新增:
如图,我有2个数据集,但文件大小总共45M,我要测试如下新增:
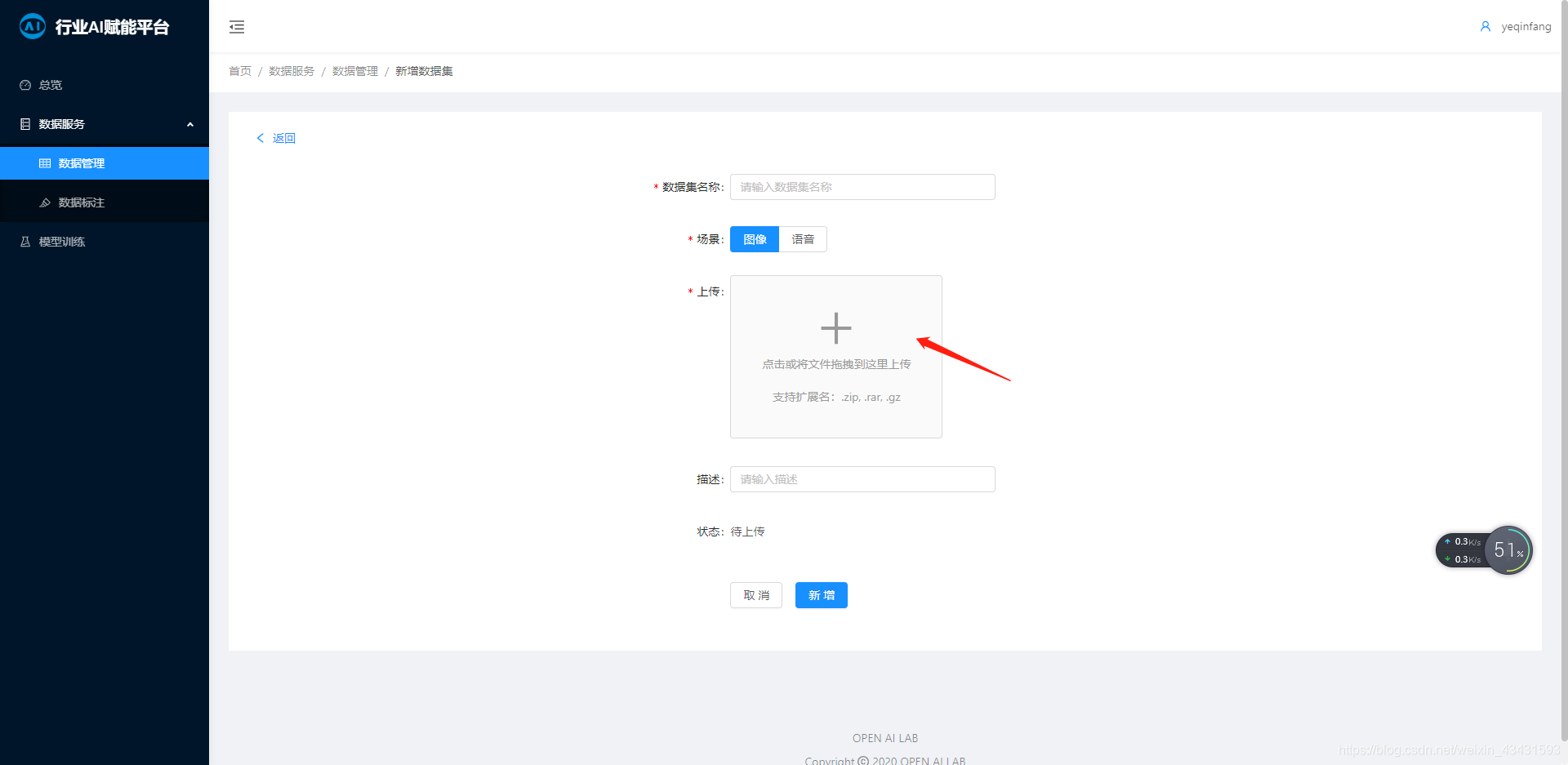 产品经理要求能够上传1T的文件,所以我要创建1T的文件上传。
产品经理要求能够上传1T的文件,所以我要创建1T的文件上传。
代码设计
1、思路
(1)先遍历文件名称,生成一个列表
(2)复制文件,文件夹末尾加上00000001,如果列表存在该文件,将跳过复制
(3)代码可以运行多次,每次在原有基础上递增
2、设计
import os
import shutil
def getFileInFolder(filepath):
pathDir = os.listdir(filepath) # 获取filepath文件夹下的所有的文件名
return pathDir
filepath = r"E:\training训练数据\ant_bees_data" # 源文件所在文件夹路径
for i in range(13):
oldants = os.path.join(filepath ,"ants") # 源文件路径
oldbees = os.path.join(filepath ,"bees")
antsName = "ants{}".format(str(i+1).zfill(8)) # 新文件名称:文件名添加后缀,如00000001
beesName = "bees{}".format(str(i+1).zfill(8))
if antsName not in getFileInFolder(filepath):
newants = os.path.join(filepath, antsName) # 新文件路径
shutil.copytree(oldants, newants) # 拷贝文件
if beesName not in getFileInFolder(filepath):
newbees = os.path.join(filepath, beesName) # 新文件路径
shutil.copytree(oldants, newbees) # 拷贝文件
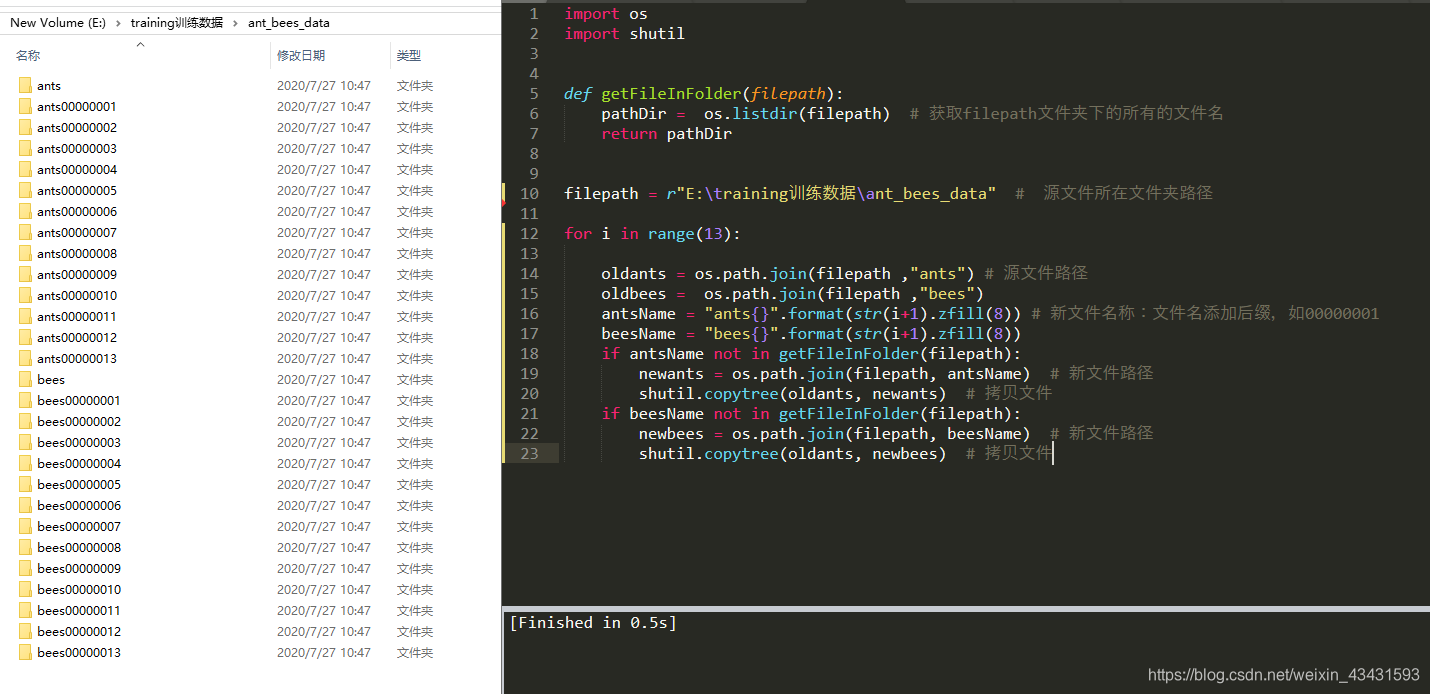
3、效果展示
4、代码优化
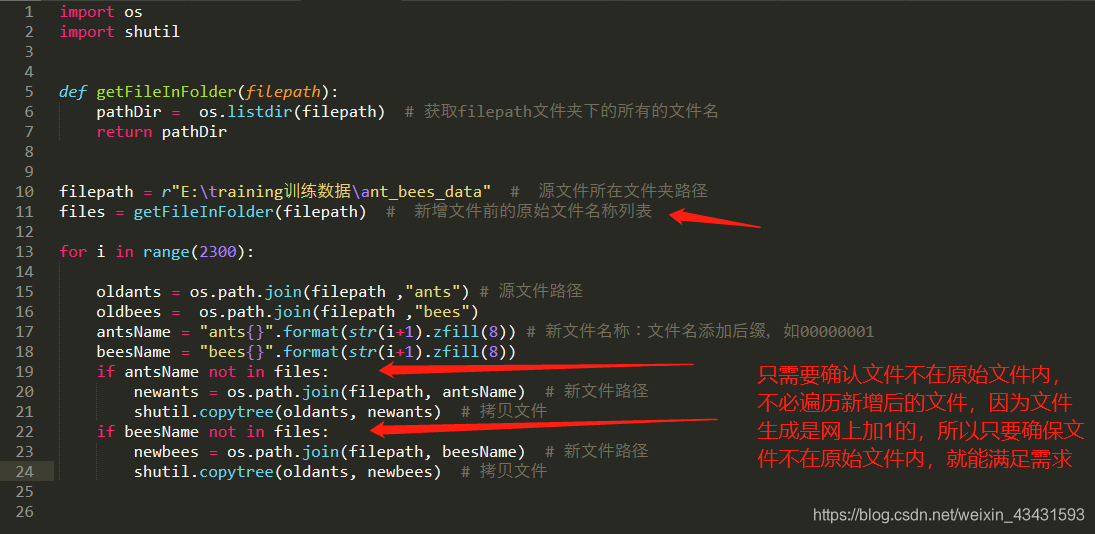 如上是优化后的代码,应该节省了一些时间,不过还可以进一步优化,聪明的你,是否挑战一下呢?(复制代码,修改路径,就能运行哦!)
如上是优化后的代码,应该节省了一些时间,不过还可以进一步优化,聪明的你,是否挑战一下呢?(复制代码,修改路径,就能运行哦!)