什么是窗口函数?
在sql中有一类函数叫做聚合函数,例如sum()、avg()、max()等等,这类函数可以将多行数据按照规则聚集为一行,一般来讲聚集后的行数是要少于聚集前的行数的.但是有时我们想要既显示聚集前的数据,又要显示聚集后的数据,这时我们便引入了窗口函数.
作用
窗口函数是一组特殊函数
■扫描多个输入行来计算每个输出值,为每行数据生成一行结果
■可以通过窗口函数来实现复杂的计算和聚合
hive中的窗口函数和sql中的窗口函数相类似,都是用来做一些数据分析类的工作,一般用于olap分析(在线分析处理)。
语法
select 列名 over(partition by 列名 order by 列名) from 表;
说明
■PARTITION BY类似于GROUP BY,未指定则按整个结果集
■只有指定ORDER BY子句之后才能进行窗口定义
■可同时使用多个窗口函数
■过滤窗口函数计算结果必须在外面一层
■在SQL处理中,窗口函数都是最后一步执行,而且仅位于Order by字句之前。
窗口函数设定关键字 OVER
1.聚合函数+over 设定窗口
假如说我们想要查询名字叫李四出现总次数,我们便可以使用窗口函数去去实现
select name,count() as consum over() from test1 where name=‘lisi’;
执行过程
先执行from后面where判断筛选后 在设定窗口函数,把数据放到窗口函数里都显示,会有多行数据,不管重不重复,在去计算聚合函数count(),得到的最后结果去匹配分给每行,但是得到的结果不一定是每行中每个数据需要的结果
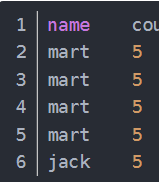
其实mart出现了4次,jack出现了1次.事实上,大多数情况下,我们是只看去重后的结果的.针对于这种情况,我们有两种实现方式
1.distinct(去重复)
select distinct name,count() as consum over() from test1 where name=‘lisi’;
2.group by(分组)
select name,count(*) as consum over() from test1 where name=‘lisi’ group by name;
结果:

这时要想把不同的名字放到不同的窗口单独计算,不让它加到一起怎么办?分窗口就出现了。
partition by 分窗口
语法:
over(partition by 列名)
定义
partition by子句放到窗口函数里面,也可以称为查询分区子句,非常类似于Group By,都是将数据按照边界值分组,而Over之前的函数在每一个分组之内进行,如果超出了分组,则函数会重新计算.
得到的结果想排序怎么办?order by 就可以使用了
order by 排序
语法:
over(partition by 列名 order by 列名)
没有排序之前,分窗口后得到的每个数值的总相加数,会匹配给每行数据

可以看到使用sum()函数后总相加数是一样的,那数据怎么排序呢

定义
写在窗口函数里面,分窗口后面,保证自己的窗口排序,排一个在加上聚合函数sum的运行结果,再去加下一个,一个个加完后排序,得到的结果很明显不是我们想要的,所以有order by 子句,那么Count(),Min(), Sum()函数就没有意义.
那么我们想得到按照我们所需要的某列排序怎么办呢?
row_number()
rank()
dense_rank()
这三个窗口函数会帮我们完成
row_ number()语法
select name ,date, price, row_ number() over(partition by month(date) order by price desc) from test1;
 定义:row_number() 没有并列,按顺序相加
定义:row_number() 没有并列,按顺序相加
以月份分窗口,按照price()降序排列后,从1开始,按照顺序,自动生成分组内记录的序列 排完序后自己加数字的升降序,没有并列的数。
rank()语法
select name ,date, price, rank() over(partition by month(date) order by price desc) from test1;

定义:rank() 有并列的换成一样的数字,然后顺序就少一位,留下一个数字的空位
从1开始,按照顺序,自动生成分组内记录的序列 排完序后自己加数字的升降序,排序的值有相同并列的换成一样的数字,然后下一个数字就少一位,留一个空位,并列第2后,不会显示第3。
dense_rank() 语法
select name ,date, price, dense_rank() over(partition by month(date) order by price desc) from test1;

定义:dense_rank() 有并列的换成一样的数字,然后顺序不变,按顺序相加,不会留下一个数字的空位
从1开始,按照顺序,自动生成分组内记录的序列 排完序后自己加数字的升降序,排序的值有相同并列的换成一样的数字,然后按顺序相加,不会留下一个数字的空位,并列第2后,按顺序显示第3。
window子句
使用partition by子句将数据进行了分组的处理.如果我们想要更细粒度的划分,我们就要引入window子句了.
我们首先要理解两个概念:
- 如果只使用partition by子句,未指定order by的话,我们的聚合是分组内的聚合.
- 使用了order by子句,未使用window子句的情况下,默认从起点到当前行.
当同一个select查询中存在多个窗口函数时,他们相互之间是没有影响的.每个窗口函数应用自己的规则.
语法
over(partition by … order by … )
window子句: 写在order by 后面 - PRECEDING:往前一行
- FOLLOWING:往后
- CURRENT ROW:当前行
- UNBOUNDED:起点
- UNBOUNDED PRECEDING 表示从前面的起点
- UNBOUNDED FOLLOWING:表示到后面的终点
游标
window子句划分其实是由游标来默默帮忙执行的,只是看不到比如:
UNBOUNDED PRECEDING (窗口首行)
UNBOUNDED FOLLOWING(窗口最后一行)
N PRECEDING(向前N行)
N FOLLOWING (向后N行)
CURRENT ROW(当前行)
LAG和LEAD函数
返回上下数据行的数据 不参与数值比较
LAG语法:向上取值
lag(date,1,‘1990-01-03’) over()
取给定的指定具体时间的上1行数据的值
lag(date,2) over()
取第一次时间的上面2行的数据的值,很显然是没有值的显示null,注意当lag函数未设置行数值时,默认为1行.设定取不到时的默认值时,取null值.
**LEAD语法:和LAG()相反,向下取值
lead(date,1,‘1990-01-03’) over()
取给定的指定具体时间的下1行数据的值
lead(date,2) over()
取第一次时间的下面2行的数据的值,注意当lag函数未设置行数值时,默认为1行.设定取不到时的默认值时,取null值.
first_value和last_value
取分组内排序后,截止到当前行,第一个值 和最后一个值
first_value()语法
first_value(列)over(partition by name order by price desc)
根据窗口的当前指针获取当前窗口的第一个值
last_value()语法
last_value(列)over(partition by name order by price desc)
根据窗口的当前指针获取当前窗口的最后一个值

扩展:
row_number的用途非常广泛,排序最好用它,它会为查询出来的每一行记录生成一个序号,依次排序且不会重复,注意使用row_number函数时必须要用over子句选择对某一列进行排序才能生成序号。
rank函数用于返回结果集的分区内每行的排名,行的排名是相关行之前的排名数加一。简单来说rank函数就是对查询出来的记录进行排名,与row_number函数不同的是,rank函数考虑到了over子句中排序字段值相同的情况,如果使用rank函数来生成序号,over子句中排序字段值相同的序号是一样的,后面字段值不相同的序号将跳过相同的排名号排下一个,也就是相关行之前的排名数加一,可以理解为根据当前的记录数生成序号,后面的记录依此类推。
dense_rank函数的功能与rank函数类似,dense_rank函数在生成序号时是连续的,而rank函数生成的序号有可能不连续。dense_rank函数出现相同排名时,将不跳过相同排名号,rank值紧接上一次的rank值。在各个分组内,rank()是跳跃排序,有两个第一名时接下来就是第四名,dense_rank()是连续排序,有两个第一名时仍然跟着第二名。
关于Parttion by:
Parttion by关键字是Oracle中分析性函数的一部分,用于给结果集进行分区。它和聚合函数Group by不同的地方在于它只是将原始数据进行名次排列,能够返回一个分组中的多条记录(记录数不变),而Group by是对原始数据进行聚合统计,一般只有一条反映统计值的结果(每组返回一条)。
TIPS:
使用rank over()的时候,空值是最大的,如果排序字段为null, 可能造成null字段排在最前面,影响排序结果。
可以这样: rank over(partition by course order by score desc nulls last)
总结:
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序。