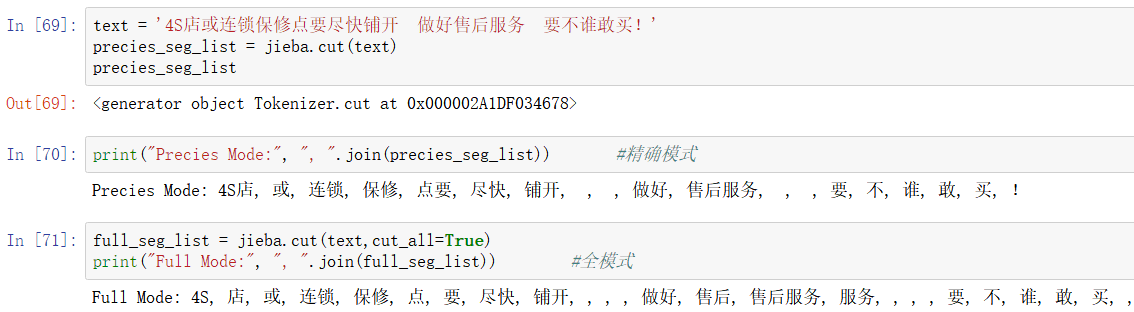
1. jieba.cut():返回的是一个迭代器。参数cut_all是bool类型,默认为False,即精确模式,当为True时,则为全模式
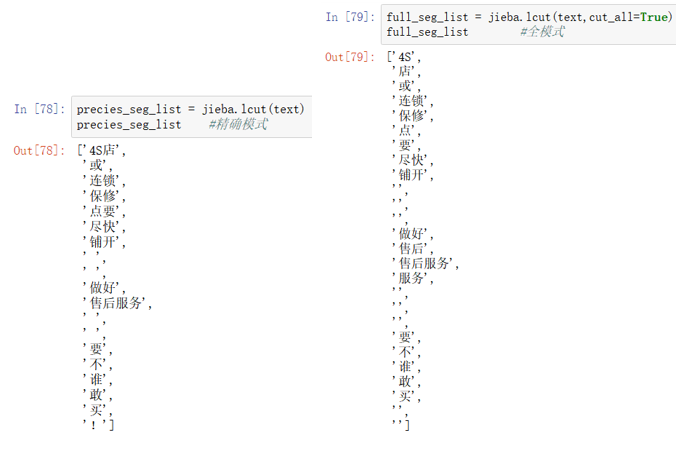
2. jieba.lcut(): 返回的是列表。
3. jieba.cut_for_search()是搜索引擎模式

使用默认字典时,一些新的词汇无法正确分词
#添加自定义词典
text1 = '无妻徒刑,厉害炸了,卷积神经网络'
seg_list1 = jieba.cut(text1, cut_all=False)
print("/ ".join(seg_list1))
无妻/ 徒刑/ ,/ 厉害/ 炸/ 了/ ,/ 卷积/ 神经网络
将这三个新词加入字典后
jieba.load_userdict('myDict.txt') # file_name为自定义词典的路径
seg_list1 = jieba.cut(text1, cut_all=False)
print("/ ".join(seg_list1))
无妻徒刑/ ,/ 厉害炸了/ ,/ 卷积神经网络
5. jieba.tokenize(): 返回词在原文的位置,下例中的result是一个迭代器。
result = jieba.tokenize(u'永和服装饰品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
word 永和 start: 0 end:2
word 服装 start: 2 end:4
word 饰品 start: 4 end:6
word 有限公司 start: 6 end:10