先看效果图。
输入codeforces的用户名,可以查询用户的rating信息。以及参加比赛的信息(大星参数的不计算在内)。还有总的AC数。

一、需求分析
- 找到显示用户参加contest信息的url。
- 分析请求方式。
- 然后就可以分析页面元素,进行解析。
- 保存解析后的数据:控制台,文本,数据库都行,怎么高兴怎么来。
二、具体实现
还是以tourist大佬的contest信息为例
2.1 分析url链接
url链接:http://codeforces.com/contests/with/tourist
点击个人信息->contest

分析一下请求连接,可以看到规律
http://codeforces.com/contests/with/username
那么请求链接的python代码如下
import requests
# 设置一下请求头信息,虽然cf不反爬虫
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
name = input("请输入要查找的用户名:")
url = 'http://codeforces.com/contests/with/' + name
response = requests.get(url, headers=headers)
2.2 分析请求方式,网页源码,进行解析
我们所要解析的就是下面这部分的信息。

使用chrome浏览器,在提交记录上右击,选择检查。其他浏览器也类似。
查看网页源码可以看到该网页是通过同步加载方式获取的,那么我们只要对request的到的html代码进行解析即可

分析contest信息部分的内容可以看到,我们所要的信息就在这每个tr中。
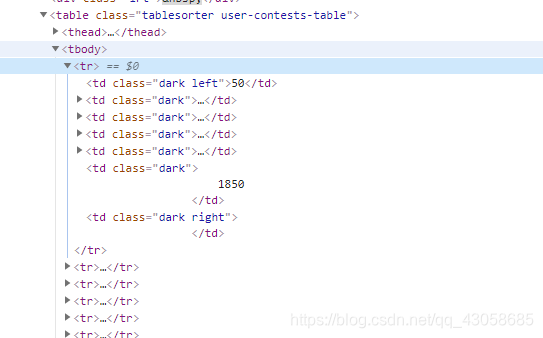
博主使用的是pyquery库进行解析。
这样就可以把每个td元素提取出来,生成一个迭代器
from pyquery import PyQuery as pq
doc = pq(response.text)
items = doc('#pageContent > div.datatable > div:nth-child(6) > table > tbody > tr').items()
通过css选择器定位元素。对这个还不熟悉的话,有个偷懒的小技巧。鼠标右击要定位元素,选择copy->copy selector

对每个td元素进行解析,获取比赛名称,rank,solved,Rating change信息
def solvetd(doc):
items = doc('td').items()
res = []
for item in items:
res.append(item.text())
info = {}
info['contest'] = res[1]
info['rank'] = int(res[2])
info['solved'] = int(res[3])
info['rating'] = int(res[4])
return info
rank = []
for item in items:
tmp = solvetd(item)
rank.append(tmp)
2.3 统计contest信息
对获取的比赛信息进行处理,分别计算每个level参加的总场数,和rating变化情况。
def init():
"""
初始化contest字典信息
:return:
"""
dic = {}
dic['count'] = 0
dic['rank'] = 0
dic['solved'] = 0
dic['rating'] = 0
return dic
def change(dic, item):
"""
计算每个level的contests:
:param dic: 可能是div1 div2 div3 globals
:param item:
:return:
"""
dic['count'] = dic['count'] + 1
dic['rank'] = dic['rank'] + item['rank']
dic['rating'] = dic['rating'] + item['rating']
dic['solved'] = dic['solved'] + item['solved']
return dic
def solvecontest(infos):
"""
统计所有比赛信息:每个level的contest的参加次数,和rating总的变化,和解决题面的总数
:param infos:
:return:
"""
div1 = init()
div2 = init()
div3 = init()
globals = init()
for item in infos:
if 'Div. 3' in item['contest']:
div3 = change(div3, item)
elif 'Div. 2' in item['contest']:
div2 = change(div2, item)
elif 'Div. 1' in item['contest']:
div1 = change(div1, item)
else:
globals = change(globals, item)
info = {}
info['div1'] = div1
info['div2'] = div2
info['div3'] = div3
info['globals'] = globals
return info
contestinfo = []
cnt = 0
rating = 0
for key in info.keys():
if info[key]['count'] == 0:
continue
cnt = cnt + info[key]['count']
rating = rating + info[key]['rating']
contestinfo.append(key + '-参加场数:{:d}'.format(info[key]['count']))
contestinfo.append(key + '-均场解题数:{:.2f}'.format(info[key]['solved'] / info[key]['count']))
contestinfo.append(key + '-均场排名:{:.2f}'.format(info[key]['rank'] / info[key]['count']))
contestinfo.append('')
2.4 计算总过题数
计算总过题数,不论是否是在比赛中提交的。具体的获取方法参考博主上一篇博客【Python爬虫实战】统计OJ刷题记录(一) 统计Codeforces刷题记录
import codeforces
def getAC(name):
"""
获取总过题数
:param name:
:return:
"""
return codeforces.main(name)
userratingnfo = getUserRatinginfo(name)
2.5 输出查询到的信息
为了方便,就把查询到的信息输出到控制台好了
print("cf-ID:", name)
print('cf-rating:', userratingnfo['rating'])
print('cf最高rating:', userratingnfo['maxrating'])
print("比赛总数:", cnt)
print("过题总数:", acCount)
if cnt != 0:
print("每场平均加分:{:.2f}".format(rating / cnt))
else:
print("每场平均加分:0")
print('')
for i in contestinfo:
print(i)
三、完整源码
contestInfo.py
import requests
from pyquery import PyQuery as pq
import codeforces
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
def solvetd(doc):
items = doc('td').items()
res = []
for item in items:
res.append(item.text())
info = {}
info['contest'] = res[1]
info['rank'] = int(res[2])
info['solved'] = int(res[3])
info['rating'] = int(res[4])
return info
def init():
"""
初始化contest字典信息
:return:
"""
dic = {}
dic['count'] = 0
dic['rank'] = 0
dic['solved'] = 0
dic['rating'] = 0
return dic
def change(dic, item):
"""
计算每个level的contests:
:param dic: 可能是div1 div2 div3 globals
:param item:
:return:
"""
dic['count'] = dic['count'] + 1
dic['rank'] = dic['rank'] + item['rank']
dic['rating'] = dic['rating'] + item['rating']
dic['solved'] = dic['solved'] + item['solved']
return dic
def getAC(name):
"""
获取总过题数
:param name:
:return:
"""
return codeforces.main(name)
def solvecontest(infos):
"""
统计所有比赛信息
:param infos:
:return:
"""
div1 = init()
div2 = init()
div3 = init()
globals = init()
for item in infos:
if 'Div. 3' in item['contest']:
div3 = change(div3, item)
elif 'Div. 2' in item['contest']:
div2 = change(div2, item)
elif 'Div. 1' in item['contest']:
div1 = change(div1, item)
else:
globals = change(globals, item)
info = {}
info['div1'] = div1
info['div2'] = div2
info['div3'] = div3
info['globals'] = globals
return info
def getUserRatinginfo(name):
rating = {}
url = 'http://codeforces.com/profile/' + name
response = requests.get(url, headers=headers)
doc = pq(response.text)
nowrating = doc(
'#pageContent > div:nth-child(3) > div.userbox > div.info > ul > li:nth-child(1) > span.user-blue').text()
maxrating = doc(
'#pageContent > div:nth-child(3) > div.userbox > div.info > ul > li:nth-child(1) > span.smaller > span:nth-child(2)').text()
rating['rating'] = nowrating
rating['maxrating'] = maxrating
return rating
def main():
name = input("请输入要查找的用户名:")
url = 'http://codeforces.com/contests/with/' + name
response = requests.get(url, headers=headers)
doc = pq(response.text)
items = doc('#pageContent > div.datatable > div:nth-child(6) > table > tbody > tr').items()
rank = []
for item in items:
tmp = solvetd(item)
rank.append(tmp)
info = solvecontest(rank)
userratingnfo = getUserRatinginfo(name)
contestinfo = []
cnt = 0
rating = 0
for key in info.keys():
if info[key]['count'] == 0:
continue
cnt = cnt + info[key]['count']
rating = rating + info[key]['rating']
contestinfo.append(key + '-参加场数:{:d}'.format(info[key]['count']))
contestinfo.append(key + '-均场解题数:{:.2f}'.format(info[key]['solved'] / info[key]['count']))
contestinfo.append(key + '-均场排名:{:.2f}'.format(info[key]['rank'] / info[key]['count']))
contestinfo.append('')
acCount = getAC(name)
print("cf-ID:", name)
print('cf-rating:', userratingnfo['rating'])
print('cf最高rating:', userratingnfo['maxrating'])
print("比赛总数:", cnt)
print("过题总数:", acCount)
if cnt != 0:
print("每场平均加分:{:.2f}".format(rating / cnt))
else:
print("每场平均加分:0")
print('')
for i in contestinfo:
print(i)
if __name__ == '__main__':
main()
codeforces.py
from pyquery import PyQuery as pq
import requests
import time
def solve_tr(tr):
"""
解析我们所需要的内容
:param tr: tr元素
:return: dict
"""
problemName = tr.find('.status-small>a').text()
state = tr.find(':nth-child(6)').text()
it = {'problemName': problemName, 'state': state}
return it
def get_pages_num(doc):
"""
获取需要爬取的页码数量
:param doc: pyquery返回的解析器
:return: int,页码数量
"""
try:
length = doc.find('#pageContent>.pagination>ul>*').length
last_li = doc.find('#pageContent>.pagination>ul>li:nth-child(' + str(length - 1) + ')')
# print('length', length)
# print(last_li.text())
# for item in items:
# print(item)
return max(1, int(last_li.text()))
except Exception:
return None
def crawl_one_page(doc):
"""
爬取每一页中的内容
:param doc: pyquery返回的解析器
"""
items = doc.find('[data-submission-id]').items()
acCount = 0
sset = []
for item in items:
it = solve_tr(item)
if it['state'] == 'Accepted':
sset.append(it['problemName'])
# with open('../data.txt', 'a+', encoding='utf-8') as f:
# f.write(str(it) + '\n')
# print(it)
sset=set(sset)
return sset
def get_username():
"""
获取用户名
:return:
"""
username = input('请输入用户名:')
return username
def main(username=None):
base = 'https://codeforces.com/submissions/'
if username is None:
username = get_username()
url = base + username + '/page/1'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
doc = pq(response.text)
# 注释部分为测试代码
# crawl_one_page(doc)
# with open('index.html', 'w', encoding='utf-8') as f:
# f.write(doc.text())
num = get_pages_num(doc)
acCount = 0
if num is not None:
for i in range(1, num + 1):
url = base + username + '/page/' + str(i)
# print(url)
response = requests.get(url=url)
doc = pq(response.text)
tmp=crawl_one_page(doc)
acCount=acCount+len(tmp)
time.sleep(1)
else:
print('username is no exist or you are no submission')
# print(acCount)
return acCount
if __name__ == '__main__':
main()