功能是搜索商品,并把搜到的商品信息一一爬取(多个页面):
爬取商品名称、店铺名称、销量、评论数量、地址等等,然后把信息存储为csv文件…
效果:
首先是程序运行
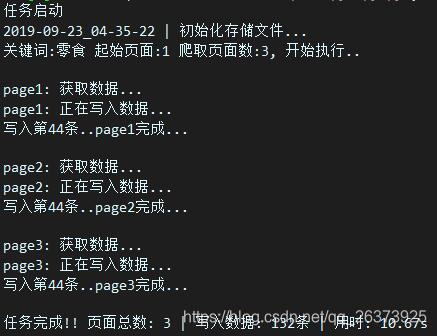
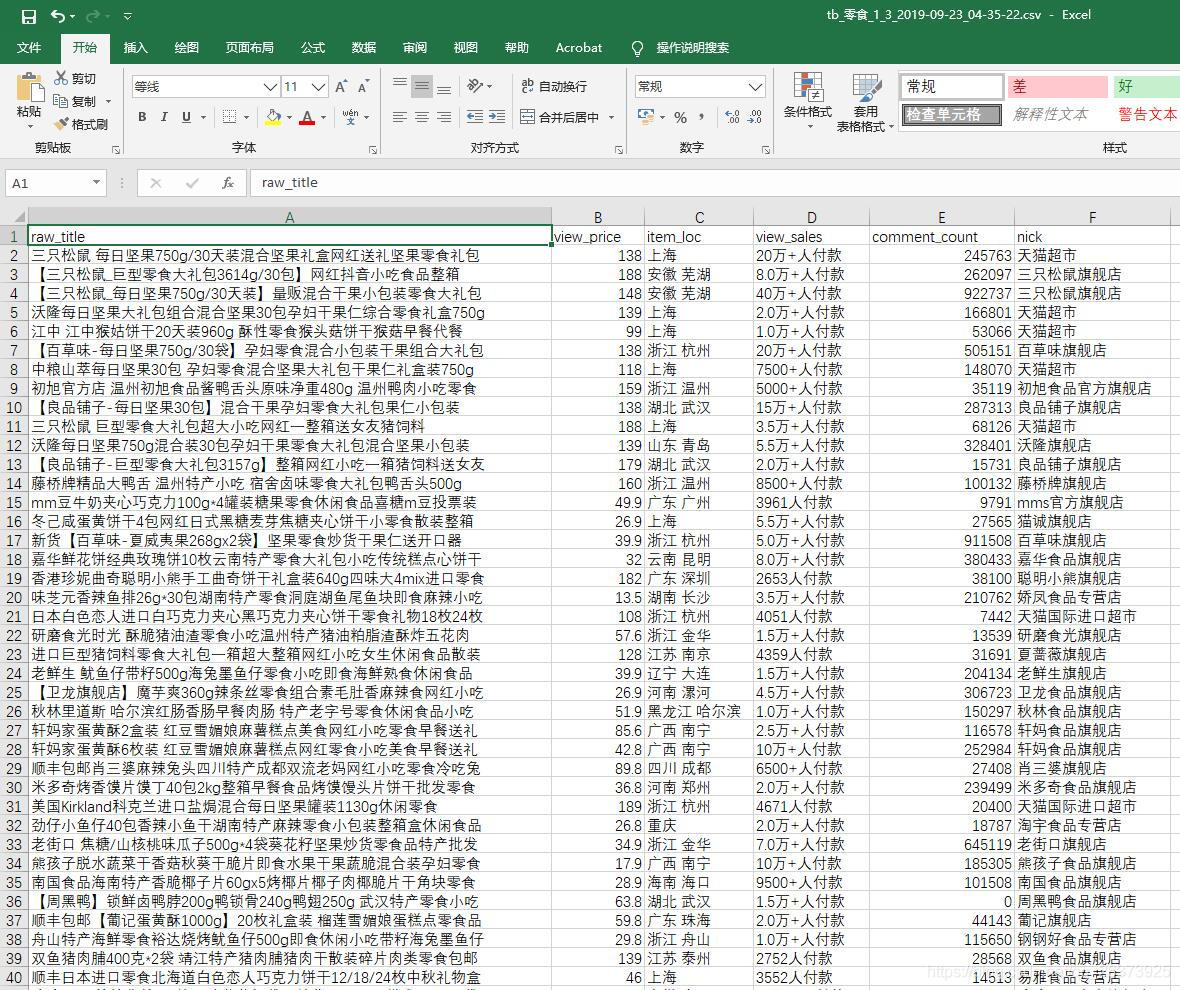
运行完后可以看到目录下出现了一个csv文件
打开看看,还不错
现在在淘宝搜索需要登录了,所以要把登录成功后得到的cookie塞进请求headers里才行;
我这代码里面的cookie是掏的某位老哥的。。不能保证一直有效,所以最好还是用自己的cookie…
若cookie无效,则可能导致搜索失败,文章尾部会介绍如何使用自己的cookie。
好了话不再多说,直接上代码
import re
import requests
import time
def getNowTime(form='%Y-%m-%d_%H-%M-%S'):
nowTime = time.strftime(form, time.localtime())
return nowTime
# 搜索关键字
searchKey = '零食'
# 输出文件编码(一般是utf-8,不过我用excel打开输出的csv文件发现会乱码,就用了ansi)
encode = 'ansi'
# keys是我要获取的宝贝信息属性
keys = ('raw_title','view_price','item_loc','view_sales','comment_count','nick')
url = 'https://s.taobao.com/search'
params = {'q':searchKey, 'ie':'utf8'}
header = {
"cookie":"cna=EYnEFeatJWUCAbfhIw4Sd0GO; x=__ll%3D-1%26_ato%3D0; hng=CN%7Czh-CN%7CCNY%7C156; uc1=cookie14=UoTaHYecARKhrA%3D%3D; uc3=vt3=F8dBy32hRyZzP%2FF7mzQ%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&nk2=1DsN4FjjwTp04g%3D%3D&id2=UondHPobpDVKHQ%3D%3D; t=ad1fbf51ece233cf3cf73d97af1b6a71; tracknick=%5Cu4F0F%5Cu6625%5Cu7EA22013; lid=%E4%BC%8F%E6%98%A5%E7%BA%A22013; uc4=nk4=0%401up5I07xsWKbOPxFt%2BwuLaZ8XIpO&id4=0%40UOE3EhLY%2FlTwLmADBuTfmfBbGpHG; lgc=%5Cu4F0F%5Cu6625%5Cu7EA22013; enc=ieSqdE6T%2Fa5hYS%2FmKINH0mnUFINK5Fm1ZKC0431E%2BTA9eVjdMzX9GriCY%2FI2HzyyntvFQt66JXyZslcaz0kXgg%3D%3D; _tb_token_=536fb5e55481b; cookie2=157aab0a58189205dd5030a17d89ad52; _m_h5_tk=150df19a222f0e9b600697737515f233_1565931936244; _m_h5_tk_enc=909fba72db21ef8ca51c389f65d5446c; otherx=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0; l=cBa4gFrRqYHNUtVvBOfiquI8a17O4IJ51sPzw4_G2ICP9B5DeMDOWZezto8kCnGVL6mpR3RhSKO4BYTKIPaTlZXRFJXn9MpO.; isg=BI6ORhr9X6-NrOuY33d_XmZFy2SQp1Ju1qe4XLjXJRHsGyp1IJ9IG0kdUwfSA0oh",
"referer":"https://detail.tmall.com/item.htm",
"user-agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36"
}
startPage = 1 # 起始页面
pageTotal = 3 # 爬取多少页
waitTime = 2 # 等待时间(如果爬的速度太快可能会出事)
rowWrited = 0
startTime = time.time()
print('任务启动\n{} | 初始化存储文件...'.format(getNowTime()))
fileName = r'tb_{}_{}_{}_{}.csv'.format(searchKey, startPage, pageTotal, getNowTime())
with open(fileName, 'w', encoding=encode) as saveFile:
saveFile.write(','.join(keys) + '\n')
print('关键词:{} 起始页面:{} 爬取页面数:{}, 开始执行..'.format(searchKey, startPage, pageTotal))
for page in range(startPage, pageTotal+1):
print('\npage{}: 获取数据...'.format(page))
time.sleep(waitTime)
params['s'] = str(page * 44) if page > 1 else '1'
resp = requests.get(url, params, headers=header)
results = [re.findall(r'"{}":"([^"]+)"'.format(key), resp.text.replace('\n','').replace('\r','').replace(',','').strip(), re.I) for key in keys]
print('page{}: 正在写入数据...'.format(page))
with open(fileName, 'a', encoding=encode) as saveFile:
for row in range(len(results[0])):
print('\r写入第{}条..'.format(row+1), end='')
rowWrited += 1
for key in range(len(results)):
try:
saveFile.write('{}{}'.format(results[key][row], ',' if key+1<len(results) else '\n'))
except:
saveFile.write('null{}'.format(',' if key+1<len(results) else '\n'))
print('page{}完成...'.format(page, len(results[0])))
print('\n任务完成!! 页面总数: {} | 写入数据: {}条 | 用时: {:.2f}s'.format(pageTotal, rowWrited, time.time()-startTime))
结束
这里介绍如何在代码中使用自己的cookie:
根据我的测试(2019年9月25日),发现需要在请求cookie中加入 enc 字段才可以进行搜索。
1、用浏览器登录淘宝后,开启浏览器开发者工具(F12)
2、访问 https://s.taobao.com/search,然后按下图所示找到 enc 字段:
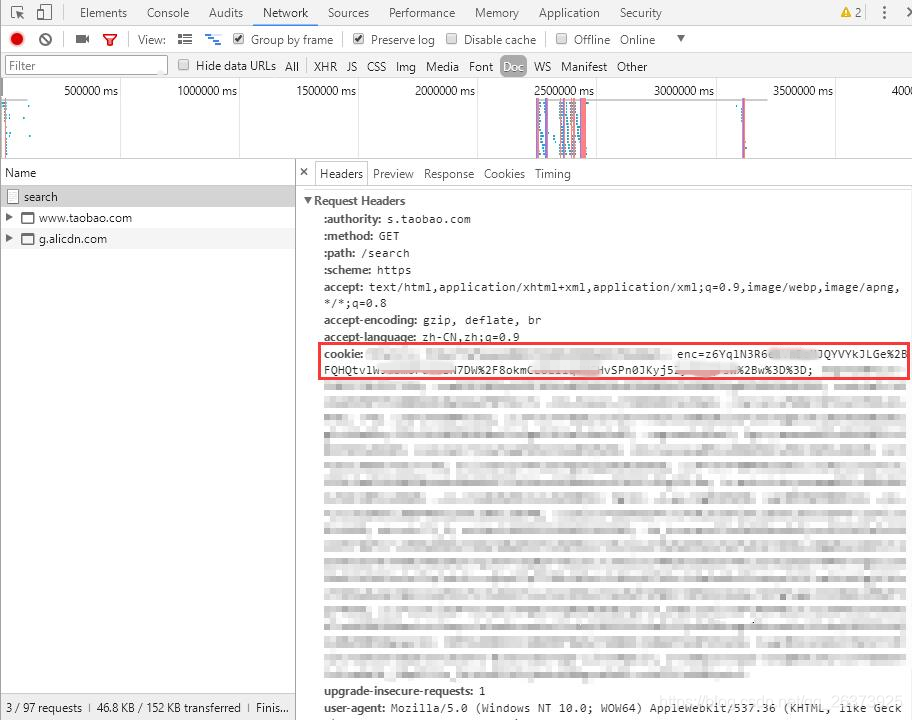
3、回到py文件,将其加入header字典中的cookie里即可。
不过,由于淘宝经常更新,此方法时效未知。如果不行,就试着把cookie整个丢进去吧…)
结束