想法:源于本学期学校的一个课程,老师要求使用一门语言写一个程序,老师也不管你写的什么,反正就是自己学自己写一个小程序,作为二翅猿的我就想到了爬pixiv原图,省掉手一个个保存还能提交期末作业哈哈哈哈
部分思路参考CSDN另一篇文章,给我提供了很大帮助
从零开始实现pixiv爬虫
1:运行环境
Python3.8
selenium
requests
lxml
Selenium需要使用Chromedriver并设置路径
驱动下载链接:
Chromedriver
#executable_path为路径
bro = webdriver.Chrome(executable_path='该位置为chromedriver存放路径',
chrome_options=chrome_options, options=option)
2:写代码时碰到的难点
2.1 登陆问题
登陆需要处理四个参数
pixiv_id 和 password 就是自己的账号密码
重点就是 post_key 和 和 Racaptcha_v3_token 这两个参数
post_key很简单拿到,通过抓包可以看到,在登陆网页:
https://accounts.pixiv.net/loginreturn_to=https%3A%2F%2Fwww.pixiv.net%2Fen%2F&lang=en&source=pc&view_type=page
然后用etree xpath可以解析到post_key
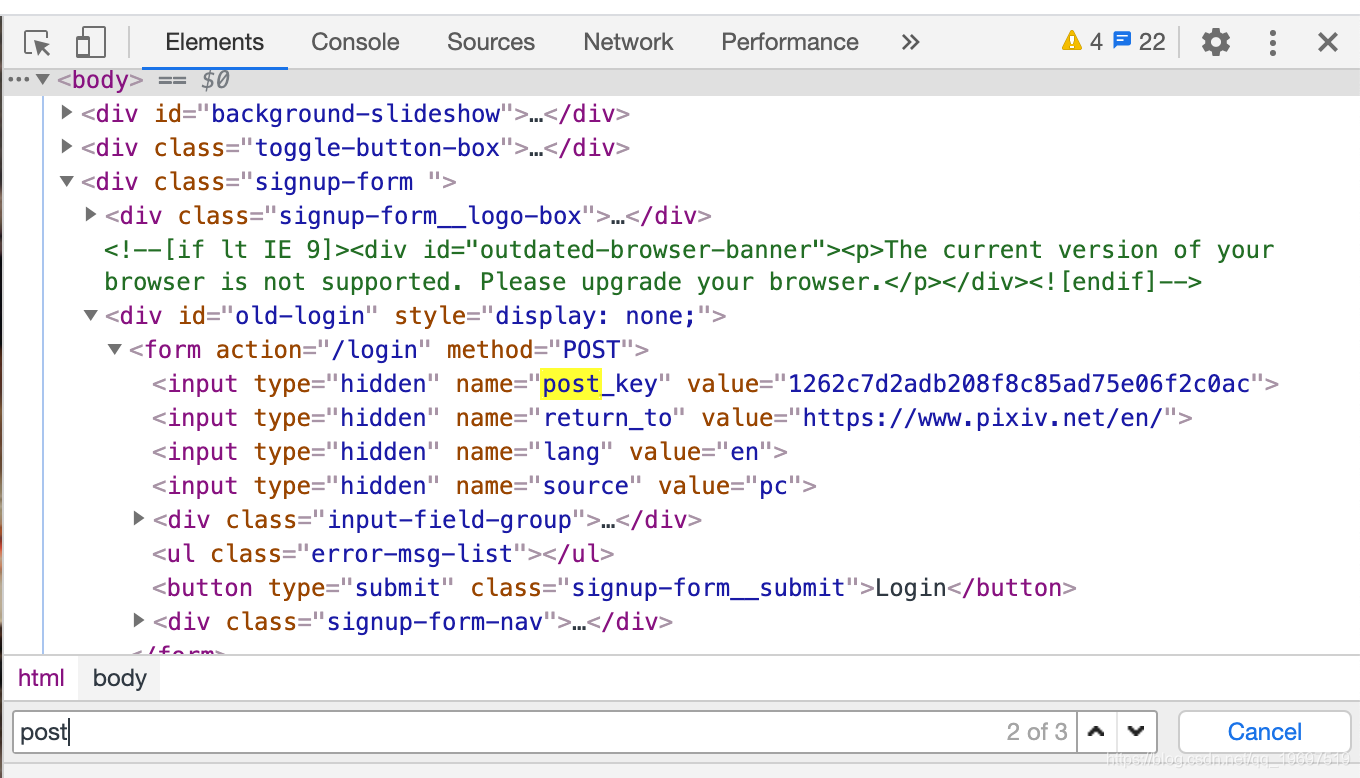
重点是这个Racaptcha_v3_token到底是什么
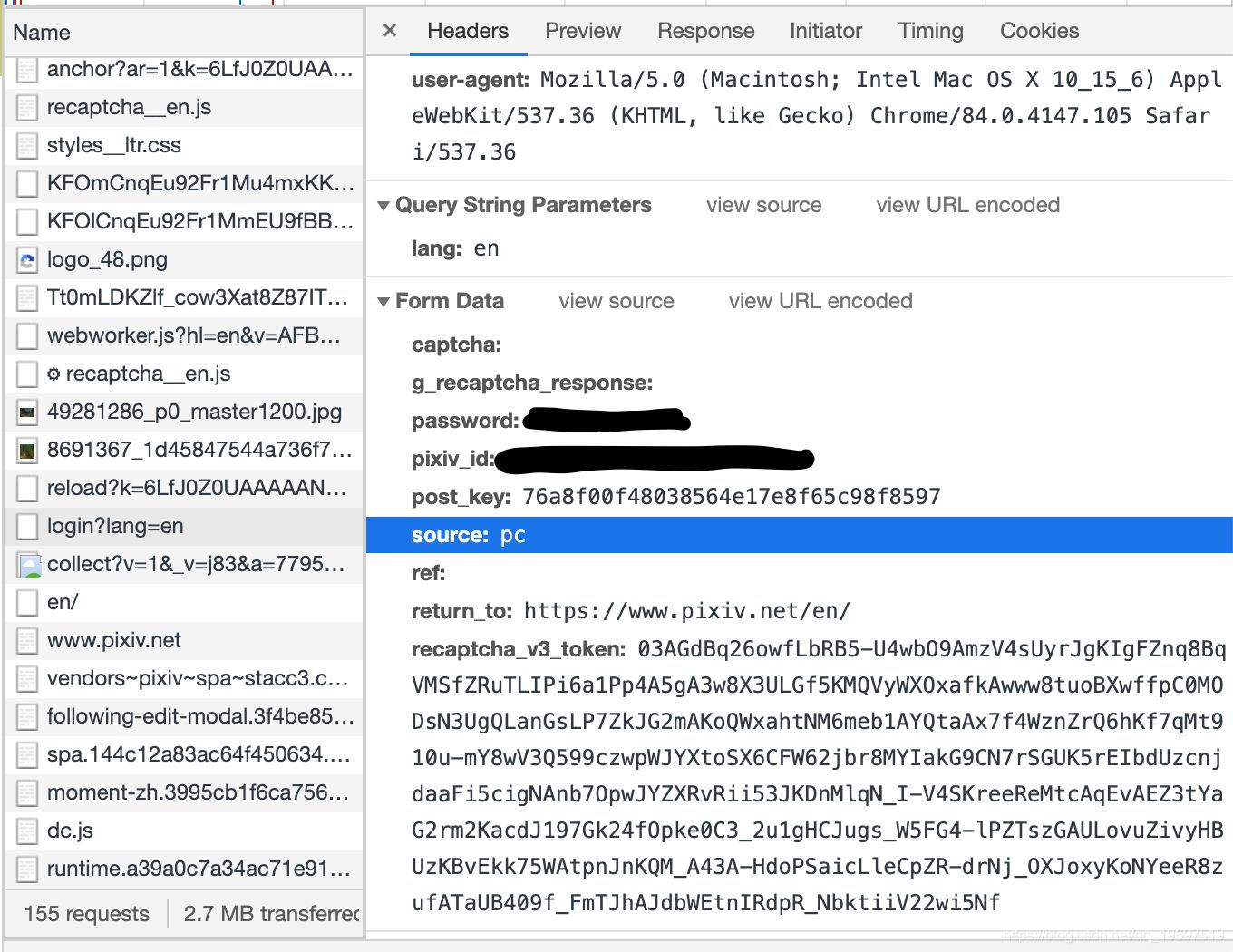
经过baidu baidu google google,发现这是google v3人机验证,这就没办法了
卡了一段时间
因为没有经验边学边查资料找方法,后来学到了selenium模块能够使用chromedriver进行模拟登陆获取cookie然后进行爬取。然后写写写。。。。
代码如下:
因为爬排行榜不需要登陆所以这里写的拿cookie拿的是画师id对应界面的cookie
代码为类里的片段,完整放在最后
def get_cookie(self, art_id): # 使用selenium模块进行模拟登陆
chrome_options = Options() # 切换无头浏览器
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
option = ChromeOptions() # 改参数反爬
option.add_experimental_option('excludeSwitches', ['enable-automation'])
bro = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver',
chrome_options=chrome_options, options=option)
# bro = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver', options=option)
url = 'https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2Fen%2Fusers%2F' + art_id + '&lang=en&source=pc&view_type=page'
bro.get(url)
if self.username is None:
self.username = str(input("请输入用户名"))
if self.password is None:
self.password = str(input("请输入密码"))
user_tag = bro.find_element_by_xpath(
'//*[@id="LoginComponent"]/form/div[1]/div[1]/input') # 定位按钮
user_tag.send_keys(self.username)
time = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
sleep(random.choice(time))
pass_tag = bro.find_element_by_xpath('//*[@id="LoginComponent"]/form/div[1]/div[2]/input')
pass_tag.send_keys(self.password)
bro.find_element_by_xpath('//*[@id="LoginComponent"]/form/button').click()
sleep(3.5)
cookie_item = bro.get_cookies() # 获取cookie
cookie_str = ''
# page_text = bro.page_source
# print(page_text)
bro.quit()
for item_cookie in cookie_item: # 拼接cookie
item_str = item_cookie["name"] + "=" + item_cookie["value"] + ";"
cookie_str += item_str
return cookie_str
重点在sleep(3.5),如果不让程序停一会,获取cookie过快会导致获取的cookie不全,导致后面抓取画师id页面的时候会抓不全插画id。拿到cookie之后就可以进行下一步,爬取画师ID对应的所有插画id
2.2 反爬的几个参数设置
进入某画师的页面之后会,抓包工具里的XHR会抓到这些个东西。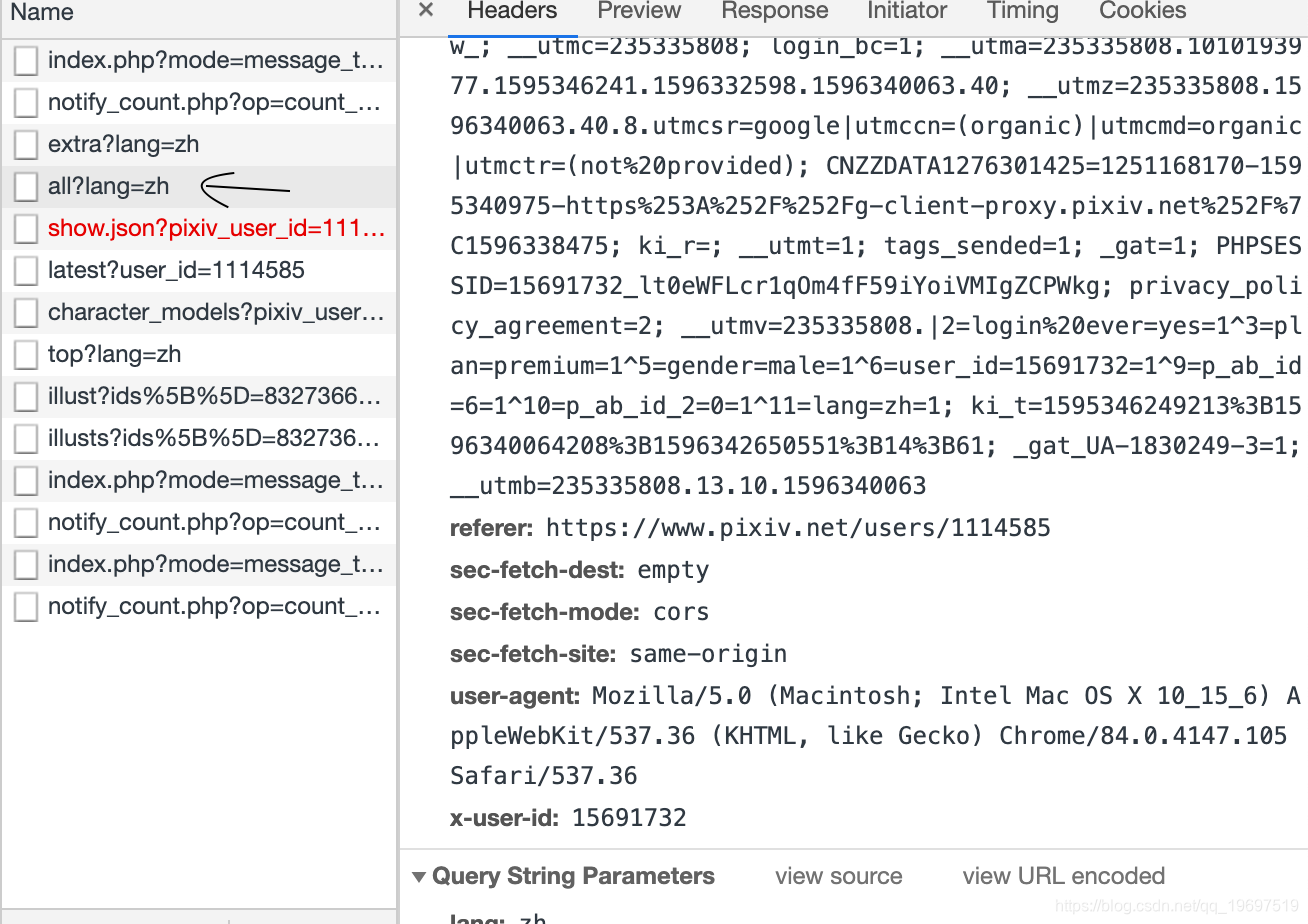
其中all?lang=zh的request url为https://www.pixiv.net/ajax/user/1114585/profile/all?lang=zh 其中1114585为画师id
重点是下面的referer参数和x-user-id参数再配合get_cookie拿到的该id页面的cookie,其中referer为上级请求页面
格式为https://www.pixiv.net/users/ + 画师ID。 x-user-id为自己登陆的账号的id
基于这几个参数又可以拿到画师ID页面的json数据,拿到json解析网站上可以发现里面含有该画师所有插画id

于是通过代码实现抓取所有的ID
代码如下:
def liked_user_illustlist(self, likedUser_id):
headers = self.headers.copy()
likedUser_id = str(likedUser_id)
illust_id_list = []
'''
需要登陆后的cookie和x-user-id以及referer防盗链
referer为上级页面
'''
headers['cookie'] = self.get_cookie(likedUser_id)
headers['x-user-id'] = '15691732'
headers['referer'] = 'https://www.pixiv.net/users/' + likedUser_id
# headers['sec-fetch-site']= 'same-origin'
# headers['sec-fetch-mode'] = 'cors'
# headers['sec-fetch-dest'] = 'empty'
json_url = 'https://www.pixiv.net/ajax/user/' + likedUser_id + '/profile/all?lang=en'
try:
json_load = requests.get(url=json_url, headers=headers, proxies=random.choice(self.proxy))
except:
print('Get user illust list Error')
else:
if json_load.status_code == 200:
print("Get liked user illust list successful")
json_text = json.loads(json_load.text)
for value in json_text['body']['illusts']:
illust_id_list.append(value)
self.img_path = self.img_path + 'user/' + likedUser_id + '/'
if os.path.exists(self.img_path):
os.mkdir(self.img_path)
return illust_id_list # 返回id的列表
else:
print("Get liked user illust list Error")
走到这里拿到插画id就已经差不多了,最后就是把插画id里的图片全部解析出来就可以来下载了。
因为有些插画id页面有多个图片,所以这里需要单独对每张页面进行解析,来得到原图url。因为有防盗链机制直接在浏览器进入原图url会显示404。所以得对参数进行设置,总之先解析到再说。
进入画师的页面对页面进行抓包然后可以找到在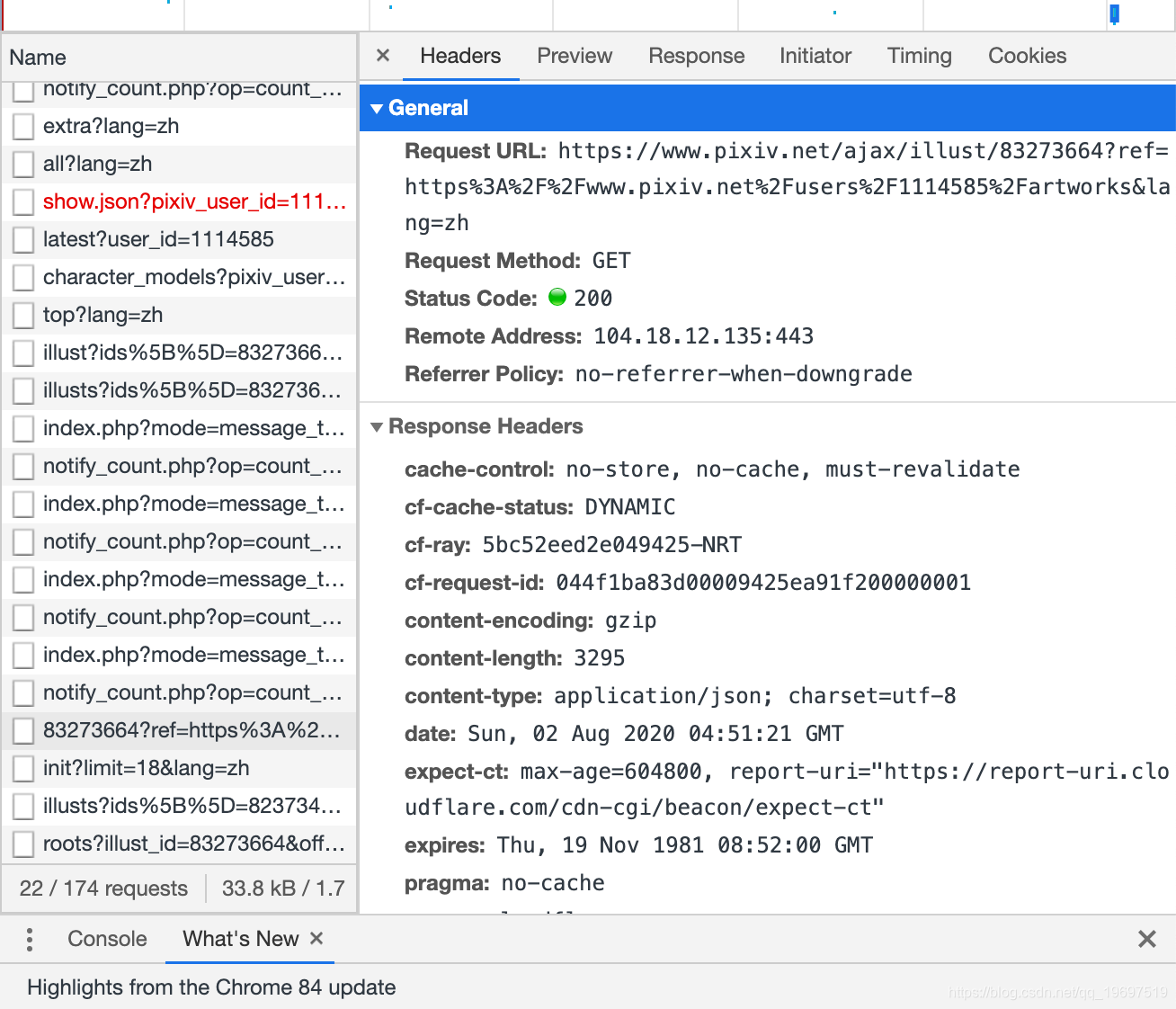
以插画id为首的XHR请求里找到请求url和相关参数,然后看到响应数据为json数据之后在response里复制响应数据,然后丢到json解析,结果为下图
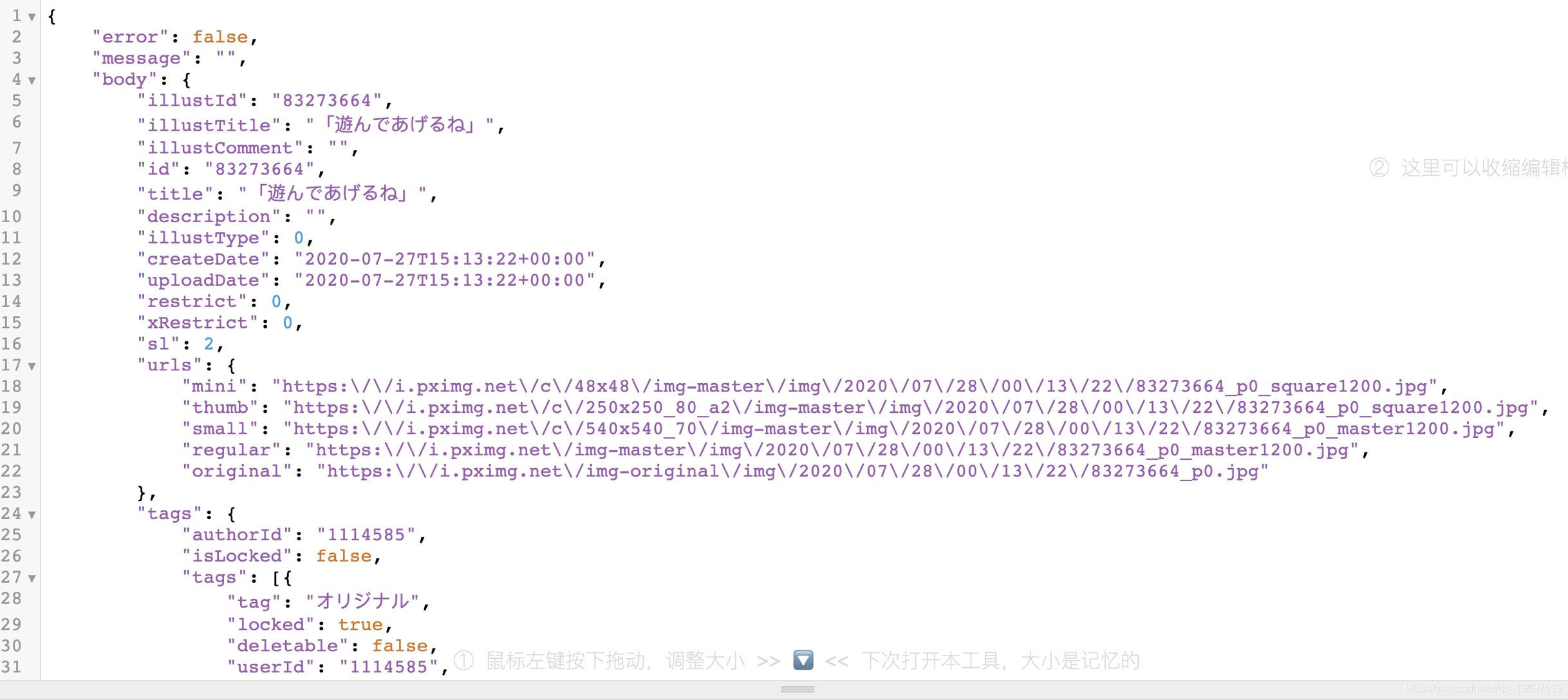
可以发现original里的链接就是原图对应的链接
直接用json模块对id页面的原图链接进行爬取
def get_original_url(self, illust_id): # 参数为单个插画id
headers = self.headers.copy()
original_url_list = []
the_original_url = 'https://www.pixiv.net/ajax/illust/' + str(illust_id) + '/pages?lang=zh' # json requests url
try: # request json data to get real pixiv_img url
url_get = requests.get(url=the_original_url, headers=headers, proxies=random.choice(self.proxy),
timeout=1000)
except:
print("Get illust original_url json Error")
else:
if url_get.status_code == 200:
url_get = url_get.text
original_json = json.loads(url_get)
for dict_urls in original_json['body']:
original_url = dict_urls['urls']['original']
original_url_list.append(original_url)
else:
print("Get illust original_url json load Error")
return original_url_list # 返回原图片链接的列表(可能有多个链接
返回的原图链接的列表
接下来到了下载,下载很简单只需要设置referer参数就可以request到图片数据
代码如下:
def download_pic(self, url): # 根据原图片链接进行下载
title = url.split('/')[-1] # 获取图片名称
headers = self.headers.copy()
headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=monthly'
path = self.img_path + '/' + title
try:
pic_get = requests.get(url=url, headers=headers,
proxies=random.choice(self.proxy))
except:
print(f"Original img.content download error")
else:
if not os.path.exists(self.img_path):
os.mkdir(self.img_path)
with open(path, 'wb') as fp:
try:
fp.write(pic_get.content)
print(f"{title} saved")
sleep(0.3)
except:
print(f'Img {title} save error')
最后是排行榜的爬取,这个是最简单的不需要登陆就能进行爬取
def get_rank_id_list(self, date, number, mode, content=None): # 获取排行榜插画id
# 设置动态参数
self.params_rank = { # 排行榜参数
'mode': 'daily',
'content': 'illust',
'date': '',
'p': '1',
'format': 'json',
}
headers = self.headers.copy()
headers['referer'] = 'https://www.pixiv.net/ranking.php'
self.params_rank['mode'] = mode
if content == None:
del self.params_rank['mode']
else:
self.params_rank['content'] = content
self.params_rank['date'] = date
page = math.ceil(number / 50) # 计算需要爬取的json页面 1page有50个插画
illust_id_list = []
for i in range(1, int(page) + 1):
self.params_rank['p'] = str(page)
try:
url_get = requests.get(url=self.url_rank, headers=headers, proxies=random.choice(self.proxy),
params=self.params_rank)
except:
print(f"Get {date} json_page {i} timeout")
else:
if url_get.status_code == 200:
print(f"Get {date} json_page {i} successful")
url_get = url_get.text
url_json = json.loads(url_get)
json_list = url_json['contents']
for dict in json_list:
user_id = dict['illust_id']
number = int(number) - 1
illust_id_list.append(user_id)
self.img_path = self.img_path + 'rank/' + date
if not os.path.exists(self.img_path):
os.mkdir(self.img_path)
# if not os.path.exists(self.img_path):
# os.mkdir(self.img_path)
return illust_id_list[0:number]
else:
print(f"Get {date} json_page {i} Error")
页面参数params是根据排行榜类型进行分析的
https://www.pixiv.net/ranking.phpmode=daily&content=illust&date=20200731
比如上面页面mode daily就是日榜
content=illust是插画排行 date是日期
然后综合排行榜没有content参数

最后的总结和所有代码
目前写了排行榜以及画师id 两个功能
可以选择综合排行榜和插画排行榜以及下面的筛选功能
最后完整代码的项目也放到了github
链接:P站爬虫
最后放完整代码
#作者:毛毛鱼iiiii
import json
import os
import requests
import random
import math
from multiprocessing.dummy import Pool
from lxml import etree
import re
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver import ChromeOptions
from time import sleep
# 部分思路学习 https://blog.csdn.net/weixin_44127580/article/details/106874830
# bro = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver',options=option)
class Pixiv(object):
headers_list = [
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.2 Safari/605.1.15',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:21.0) Gecko/20100101 Firefox/21.0',
'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'
]
referer_url = 'https://www.pixiv.net'
img_path = ''
username = None
password = None
# session = requests.Session()
def __init__(self):
self.headers = {
'User-Agent': random.choice(self.headers_list),
'referer': self.referer_url,
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"Accept-Encoding": "gzip, deflate, br",
# 'cookie': get_cookie(), #排行榜不需要cookie所以注释掉
}
self.user_id = ''
self.url_rank = 'https://www.pixiv.net/ranking.php?'
# 使用代理进行爬取
self.proxy = []
self.ips = get_ips()# 这里爬的某免费代理 建议自己写一个爬代理的模块
#源码就不放这里了
for ip in self.ips: # 将ip地址转化为http的字典
self.ip_dict = {
'http': ip
}
self.proxy.append(self.ip_dict)
def get_cookie(self, art_id): # 使用selenium模块进行模拟登陆
chrome_options = Options() # 切换无头浏览器
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
option = ChromeOptions() # 改参数反爬
option.add_experimental_option('excludeSwitches', ['enable-automation'])
bro = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver',
chrome_options=chrome_options, options=option)
# bro = webdriver.Chrome(executable_path='/usr/local/bin/chromedriver', options=option)
url = 'https://accounts.pixiv.net/login?return_to=https%3A%2F%2Fwww.pixiv.net%2Fen%2Fusers%2F' + art_id + '&lang=en&source=pc&view_type=page'
bro.get(url)
if self.username is None:
self.username = str(input("请输入用户名"))
if self.password is None:
self.password = str(input("请输入密码"))
user_tag = bro.find_element_by_xpath(
'//*[@id="LoginComponent"]/form/div[1]/div[1]/input') # 定位按钮
user_tag.send_keys(self.username)
time = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6]
sleep(random.choice(time))
pass_tag = bro.find_element_by_xpath('//*[@id="LoginComponent"]/form/div[1]/div[2]/input')
pass_tag.send_keys(self.password)
bro.find_element_by_xpath('//*[@id="LoginComponent"]/form/button').click()
sleep(3.5)
cookie_item = bro.get_cookies() # 获取cookie
cookie_str = ''
# page_text = bro.page_source
# print(page_text)
bro.quit()
for item_cookie in cookie_item: # 拼接cookie
item_str = item_cookie["name"] + "=" + item_cookie["value"] + ";"
cookie_str += item_str
return cookie_str
def get_rank_id_list(self, date, number, mode, content=None): # 获取排行榜插画id
# 设置动态参数
self.params_rank = { # 排行榜参数
'mode': 'daily',
'content': 'illust',
'date': '',
'p': '1',
'format': 'json',
}
headers = self.headers.copy()
headers['referer'] = 'https://www.pixiv.net/ranking.php'
self.params_rank['mode'] = mode
if content == None:
del self.params_rank['mode']
else:
self.params_rank['content'] = content
self.params_rank['date'] = date
page = math.ceil(number / 50) # 计算需要爬取的json页面 1page有50个插画
illust_id_list = []
for i in range(1, int(page) + 1):
self.params_rank['p'] = str(page)
try:
url_get = requests.get(url=self.url_rank, headers=headers, proxies=random.choice(self.proxy),
params=self.params_rank)
except:
print(f"Get {date} json_page {i} timeout")
else:
if url_get.status_code == 200:
print(f"Get {date} json_page {i} successful")
url_get = url_get.text
url_json = json.loads(url_get)
json_list = url_json['contents']
for dict in json_list:
user_id = dict['illust_id']
number = int(number) - 1
illust_id_list.append(user_id)
self.img_path = self.img_path + 'rank/' + date
if not os.path.exists(self.img_path):
os.mkdir(self.img_path)
# if not os.path.exists(self.img_path):
# os.mkdir(self.img_path)
return illust_id_list[0:number]
else:
print(f"Get {date} json_page {i} Error")
def liked_user_illustlist(self, likedUser_id):
headers = self.headers.copy()
likedUser_id = str(likedUser_id)
illust_id_list = []
'''
需要登陆后的cookie和x-user-id以及防盗链链接
referer为上级html页面
'''
headers['cookie'] = self.get_cookie(likedUser_id)
headers['x-user-id'] = '15691732'
headers['referer'] = 'https://www.pixiv.net/users/' + likedUser_id
# headers['sec-fetch-site']= 'same-origin'
# headers['sec-fetch-mode'] = 'cors'
# headers['sec-fetch-dest'] = 'empty'
json_url = 'https://www.pixiv.net/ajax/user/' + likedUser_id + '/profile/all?lang=en'
try:
json_load = requests.get(url=json_url, headers=headers, proxies=random.choice(self.proxy))
except:
print('Get user illust list Error')
else:
if json_load.status_code == 200:
print("Get liked user illust list successful")
json_text = json.loads(json_load.text)
for value in json_text['body']['illusts']:
illust_id_list.append(value)
self.img_path = self.img_path + 'user/' + likedUser_id + '/'
if os.path.exists(self.img_path):
os.mkdir(self.img_path)
return illust_id_list # 返回id的列表
else:
print("Get liked user illust list Error")
def get_original_url(self, illust_id): # 参数为单个插画id
headers = self.headers.copy()
original_url_list = []
the_original_url = 'https://www.pixiv.net/ajax/illust/' + str(illust_id) + '/pages?lang=zh' # json requests url
try: # request json data to get real pixiv_img url
url_get = requests.get(url=the_original_url, headers=headers, proxies=random.choice(self.proxy),
timeout=1000)
except:
print("Get illust original_url json Error")
else:
if url_get.status_code == 200:
url_get = url_get.text
original_json = json.loads(url_get)
for dict_urls in original_json['body']:
original_url = dict_urls['urls']['original']
original_url_list.append(original_url)
else:
print("Get illust original_url json load Error")
return original_url_list # 返回原图片链接的列表(可能有多个链接
def download_pic(self, url): # 根据原图片链接进行下载
title = url.split('/')[-1] # 获取图片名称
headers = self.headers.copy()
headers['referer'] = 'https://www.pixiv.net/ranking.php?mode=monthly'
path = self.img_path + '/' + title
try:
pic_get = requests.get(url=url, headers=headers,
proxies=random.choice(self.proxy))
except:
print(f"Original img.content download error")
else:
if not os.path.exists(self.img_path):
os.mkdir(self.img_path)
with open(path, 'wb') as fp:
try:
fp.write(pic_get.content)
print(f"{title} saved")
sleep(0.3)
except:
print(f'Img {title} save error')
def mode_1_list(self):
def check_dict(dict):
for key, value in dict.items():
print(key, value)
while True:
mode_input = input("---->").strip()
if mode_input in mode_dict.keys():
mode_c = mode_dict[mode_input]
break
else:
print('输入错误,应为对应编号')
date_c = input("请输入排行榜日期: ")
pic_num_c = int(input("请输入要下载前多少名: "))
return mode_c, date_c, pic_num_c
while True:
model = str(input('请选择综合排行榜或者插画排行榜: \n1 : all \n2 : illust\n或输入0退出\n---->').strip())
if model == '2':
content = 'illust'
mode_dict = {
'1': 'daily',
'2': 'weekly',
'3': 'monthly',
'4': 'rookie',
}
print("请选择请选择插画排行榜的模式 :")
mode, date, pic_num = check_dict(mode_dict)
id_list = self.get_rank_id_list(date, pic_num, mode, content)
return id_list
elif model == '1':
mode_dict = {
'1': 'daily',
'2': 'weekly',
'3': 'monthly',
'4': 'rookie',
'5': 'male',
'6': 'female',
}
print("请选择请选择综合排行榜的模式 :")
mode, date, pic_num = check_dict(mode_dict)
id_list = self.get_rank_id_list(date, pic_num, mode)
return id_list
elif model == '0':
exit('程序已退出')
else:
print("输入错误,应为对应编号")
def mode_2_list(self):
user_id = input('请输入喜欢的画师ID\n----> ')
print("将下载该画师所有插画")
return self.liked_user_illustlist(user_id)
def run(self):
count = 0
while count < 3:
select = int(input("请选择需要下载的模式: \n1:排行榜模式 \n2:画师ID模式\n----> ").strip())
if select == 1:
url_list = self.mode_1_list()
self.download(url_list)
break
elif select == 2:
url_list = self.mode_2_list()
self.download(url_list)
break
else:
print('请输入数字1或2')
count += 1
if count == 3:
print('瞎输入,程序已退出')
def download(self, id_list): # 下载 ,参数为ID列表
pool_num = 8
pool = Pool(pool_num) # 开启线程池
original_list = pool.map(self.get_original_url, id_list) # 多线程获取图片原地址
the_original_list = []
max_num = int(input('请输入单页插画数量来跳过该id\n---->'))
for id_url_list in original_list: # 循环列表提取列表里的列表,将列表中的列表链接转变为一个大的列表
if len(id_url_list) > max_num: # 如果列表中原图片链接大于指定输入值则跳过该id
continue
else:
for ori_url in id_url_list: # 循环列表里的图片地址
the_original_list.append(ori_url)
pool.map(self.download_pic, the_original_list) # 多线程下载
print(f"下载图片结束,共{len(the_original_list)}张图片")
pool.close() # Close pool
pool.join()
if __name__ == '__main__':
'''实例化Pixiv对象
然后调用函数的run'''
p = Pixiv()
p.img_path = './pixiv_img/' # 修改此项更改文件存储路径 最后以斜杠结尾 如果不存在将会创建路径
# 使用喜欢的画师模式需要输入下面三个参数
p.username = '' # 输入用户名
p.password = '' # 输入密码
p.user_id = '' # 输入自己登陆后的账户ID,在自己的页面
p.run()
PS:
get_ips这个功能被我删掉了,可以自己写一个爬取代理ip的函数然后调用就行了
如果不使用proxy的话要将每个方法里的requests.get里的proxies参数删掉
仅学习目的和自用
不要大量爬取干扰网站正常运作
欢迎指出bug和优化方案
github将不断优化更新增加新功能