前言
是的,没错,就是标题党,最近装修噪音太吵了打算搬家,所以我又来了(疯狂暗示),我觉得你们可能有需要,所以我又搬运了验证码爬虫框架以及正确的样本采集方法。
分类展示


约一千五百多万高质量样本,说不定有一种就是你正遇到的。
分类示例:
链接:https://pan.baidu.com/s/1rXUmaxP9hTi_pIJbXBj3aA
提取码:qdts
如何采集呢
1. 首先采集使用了【自研简易验证码爬虫框架】
一般的验证码获取流程分为三大步骤
- 前置请求, 获取验证码相关参数
- 验证码请求, 获取验证码
- 校验请求, 通过官网判定验证码是否正确
通过继承 Project 类实现具体的流程 utils.Project
def before_process()-> dict, 返回其他流程需要的参数字典, 通过self.before_params访问def captcha_process() -> Tuple[bytes, str], 返回验证码图片bytes和识别后的内容def feedback_process() -> bool, 返回验证码反馈情况,是否正确
在 const.json 文件中补充自己的 联众账号 和 百度API 以及样本保存的路径
{
"baidu": {
"app_id": "app_id",
"api_key": "api_key",
"secret_key": "secret_key"
},
"lianzhong": {
"username": "username",
"password": "password"
},
"target_dir": "D:/Samples"
}
编写流程:
- 补充const.json
- 在spiders包下面新建自己的爬虫可以参考demo.py
- 在app.py中执行
其中spiders/demo.py是采集某度贴吧的验证码例子:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Author: kerlomz <[email protected]>
import json
from typing import Tuple
from utils import Project, ServiceType, ProxyType
class Baidu(Project):
"""
定义自己的类
"""
def __init__(self):
super().__init__()
# 选择识别服务 [MuggleOCR, BaiduOCR, LianZhong]
self.service_type = ServiceType.MuggleOCR
# 联众的验证码类型
self.captcha_type = "1105"
# 前置页面 (验证码出现的页面,用于获取相关参数)
self.before_url = "https://tieba.baidu.com/f/commit/commonapi/getVcode"
# 验证码页面 用于获取验证码
self.captcha_url = "https://tieba.baidu.com/cgi-bin/genimg"
# 提交页面 用于校验验证码是否准确
self.feedback_url = "https://tieba.baidu.com/f/commit/commonapi/checkVcode"
def before_process(self, retry=0) -> dict:
"""
前置页面,获取验证码需要 captcha_vcode_str 参数,return 参数字典提供后面流程调用
:param retry: 重试计数
:return: 参数字典
"""
payload = {
"content": "1",
"tid": "6716233397",
"lm": "2539781",
"word": "\u5b9d\u9a6cx3",
"rs10": "0",
"rs1": "0",
"t": "0.8048427376809806"
}
r = self.session.post("https://tieba.baidu.com/f/commit/commonapi/getVcode", data=payload)
resp = r.text
resp_json: dict = json.loads(resp)
if 'captcha_vcode_str' in resp_json.keys():
captcha_vcode_str = resp_json.get('captcha_vcode_str')
return {"captcha_vcode_str": captcha_vcode_str}
else:
print(resp_json)
return {}
def captcha_process(self) -> Tuple[bytes, str]:
"""
:return: 返回两个参数:验证码bytes内容, 返回验证码标签
"""
if not self.before_params.get('captcha_vcode_str'):
raise ValueError('captcha_vcode_str is miss')
captcha_bytes = self.session.get(
self.captcha_url + "?{}".format(self.before_params['captcha_vcode_str'])
).content
captcha_text = self.platform.request(captcha_bytes)
return captcha_bytes, captcha_text
def feedback_process(self, captcha_text: str) -> bool:
"""
:param captcha_text: 验证码识别结果
:return: 返回验证状态 [验证码正确, 验证码错误]
"""
if not captcha_text:
return False
if len(captcha_text) != 4:
return False
if not self.before_params['captcha_vcode_str']:
raise ValueError('miss captcha_vcode_str')
payload = {
"captcha_vcode_str": self.before_params['captcha_vcode_str'],
"captcha_code_type": "1",
"captcha_input_str": captcha_text,
"fid": "2539781"
}
r = self.session.post(self.feedback_url, data=payload)
if '{"anti_valve_err_no":0}' in r.text:
return True
else:
r.encoding = "gbk"
print(r.text)
return False
if __name__ == '__main__':
pass
上面的采集框架源码:https://github.com/kerlomz/captcha_spider
填充完三大步骤之后,使用百度OCR识别即可采集hhhhh,但是吧,这个api字符集不多,需要结合其他的api,可以在service.py中自行添加,采集了验证码图片之后如图:

2. 其次使用Captcha Trainer框架训练
笔者采集了19w,轻松训练到97.8%识别率,使用的训练框架是:
https://www.jiqizhixin.com/articles/2020-06-11-13 介绍的框架。
名为【captcha_trainer】算是业内比较成熟的企业级框架了。
GitHub地址:https://github.com/kerlomz/captcha_trainer
使用到的采集框架的源码:https://github.com/kerlomz/captcha_spider
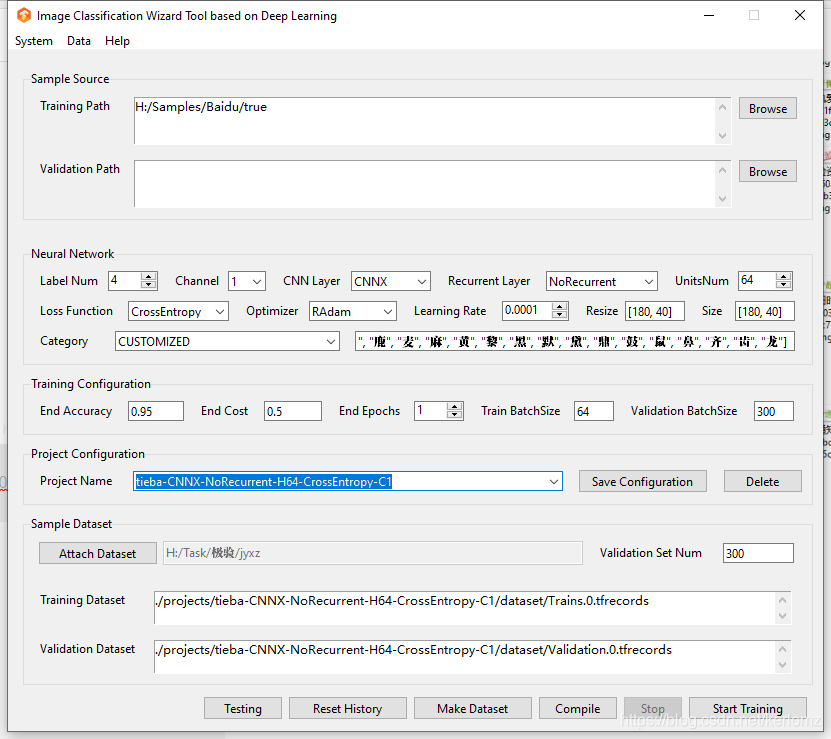
配置的参数如图:
有问题可以联系作者:27009583