ZooKeeper概念和基础
之前看过不少关于ZooKeeper的博客,文章,然后今天看了《ZooKeeper分布式过程协同技术详解》(PS:不知道是不是我的书是盗版的,里面有些错别字)的写一篇博客记录下
不然下次面试 又 被问懵逼就很尬(简历写了了解ZooKeeper,结果一问被问懵,属实尴尬)
有些是书上的内容,有些是我自己的理解。有疑问或者认为有错,欢迎指出
这篇不涉及具体安装使用,仅介绍原理。要晓得这个程序才2.3M,不会有太难的东西。 要从心里上藐视他,要是一开始就预设这个东西很难,你还学个锤子
下载链接:清华大学的镜像站下载 应该比去官网下载快点
脑图
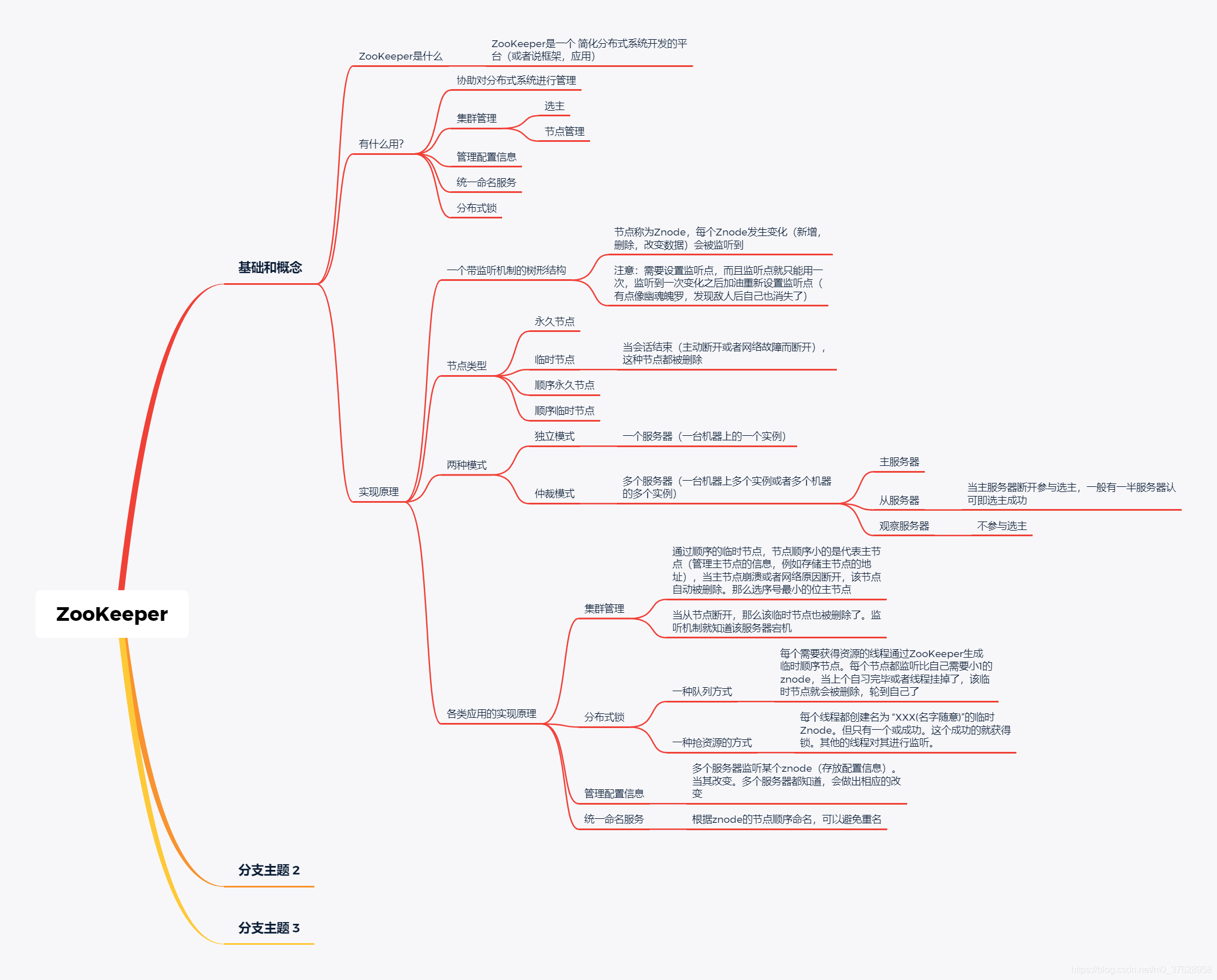
1. ZooKeeper是什么
面试官:“我看你简历写了了解ZooKeeper,ZooKeeper是什么”
我:“ZooKeeper是一个程序”
我上次有个面试其中一个问题我就这样答的,我以为我挂了,虽然最后面试还是过了。但是最终没有去
每次这种 是什么的问题就很懵,也不知道什么说
百度百科:ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
2. ZooKeeper有什么用
ZooKeeper是一个 协助分布式系统开发的 应用程序,主要用来处理协同数据。 其可以用来 集群管理,统一命名服务,管理配置信息,分布式锁
3. ZooKeeper原理
3.1 原理
ZooKeeper就是由树监听器实现的
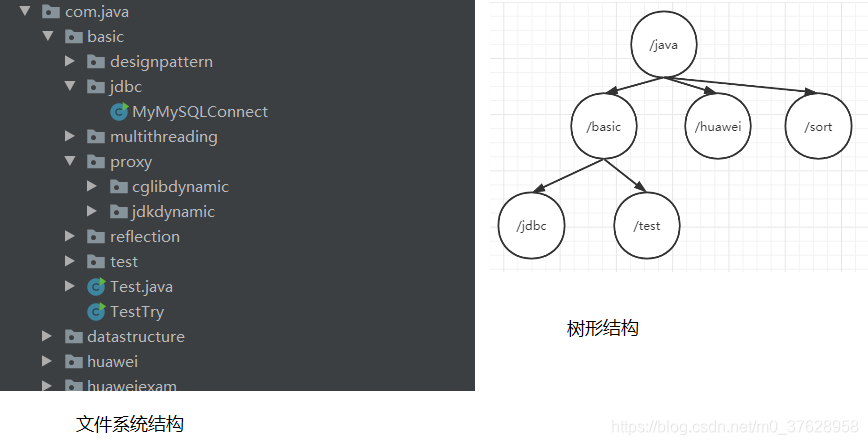
3.1.1 树形结构 Znode
就是与文件系统结构差不多的树形结构
每个节点称为Znode,可以有子节点,每个节点自身也可以存储信息
Znode有4种类型:
- 永久节点
- 临时节点 (会话session结束(正常结束,或者节点崩溃断开连接)就被删除)
- 顺序永久节点 (就是带序号)
- 顺序临时节点
session一次连接从开始到结束是一个session
基本一样:你不能在/java/basic 下建立两个jdbc文件夹
3.1.2 监听器
每一个Znode可以被监听,Znode的改变(新建,删除,修改)监听者都可以收到通知(前提是你先要监听)
PS:按我书上的说法(2016年出版的书,应该不至于过时),监听器只能用一次。就是说我坚挺到第一次变化后,如果我不重新注册监听器,就收不到第二次变化的通知
补救:收到通知后,再次设置监听前查下内容,这样不至于丢掉我第二次监听器之前的变化(但是这里会涉及到ABA问题)。但是ZooKeeper可不是用于高并发的,人家承诺的是高性能与高可用。
3.2 两种模式
ZooKeeper有独立模式和仲裁模式两种
独立单台机器单个实例
仲裁模式:单个机器多个实例或者多个机器多个实例
仲裁模式主要是用于选主,当主节点挂掉,选择一个新的主节点。超过一半(与少数服从多数有区别)认可,即成为新的主
3.3 原理在实际应用的体现
3.3.1 集群管理
选主:
每个节点用顺序临时Znode表示。例如:Znode0,Znode1,···,Znode8
其中Znode0是主节点,当其断开时,节点被删除,这个时候还连接的Znode1-8选最小的为主节点,也就是Znode1为主节点
等等!!!!,刚才说的仲裁呢?
情节1:如果生效的Znode1-8是互相连接的,Znode1节点得到8票,大于4.5自然是主节点。
**情节2:**如果生效的节点分层两部分呢(也就是脑裂):Znode1-2互相连接,Znode3-8互相连接。按照仲裁的规定,现在Znode1得两票,Znode3得6票,Znode3才是主(Master)。这个时候相当于是0.1.2断开连接,之后其序号就是9,10,11了
情节3: 如果剩下的节点分层两部分: Znode1-4组团,Znode5-8抱团
这个时候Znode1得4票小于4.5,Znode5得4票小于4.5,选谁为主节点。都不是,这个时候系统将不提供服务,也就是不可用了,请运维去排查原因。(没有主是因为两个得到的票数小于一半,而不是因为票数相同)
从节点管理:
就是都是临时节点,当从节点宕机,session结束,该节点被删除,其他 节点能够知晓。去做相应的处理
3.3.2 管理配置信息
在分布式系统中,每修改一个配置,多台机器都要同时修改。现在交给ZooKeeper管理,其他机器订阅这个节点信息。只要被修改,都能收到通知,做出相应的处理
3.3.4 统一命名服务
就像上面说的你不能在/java/basic 下建立两个jdbc文件夹。从根节点一直到子节点,每一条路径的名字都是独一无二不重复的。
3.3.5 分布式锁
这个我想来有两种实现方式:
抢占式:需要竞争资源的线程,在同一个Znode下创建一个名为 “Znode名字”的临时Znode。因为一个Znode下,每个节点名字不能重复,所以只有一个能够创建成功,这个成功的就能拿到锁,执行完毕后,或者被迫宕机。该创建的节点就会被删除(相当于释放锁),其他节点又有机会的 【题外话:与Redis做分布锁相比,节点完成或宕机后删除节点将释放锁,然而Redis就无法控制释放锁的时机】
队列式竞争资源的线程在同一个节点下创建顺序临时节点,每个节点小的先执行
4. 小结
- 仅通过属性结构,4类节点,监听机制。就能玩出各种花样,设计的人真TM厉害
- 而且Zk本身做的是也不多,无非就是创建节点,删除节点,监听,修改节点,以至于程序自身也比较小(毕竟功能少)。而且还给了应用的人自己很大的发挥空间,可以自己弄各种协作原语
- 总之一句话:设计者NB!
总目录:Java进阶之路-目录
“不宜妄自菲薄,引喻失义”
《出师表》
博主:五更依旧朝花落
首次发布时间:2020年5月23日22:29:18
末次更新时间: