spark核心概念
| Application | 基于Spark的用户程序。由群集上的 a driver program and executors 组成。=1 driver +多个executors |
| Application jar | 一个包含用户的Spark应用程序的jar。在某些情况下,用户将希望创建一个包含其应用程序及其依赖项的“超级jar”。用户的jar绝不能包含Hadoop或Spark库,但是这些库将在运行时添加。 |
| Driver program | 该进程运行应用程序的main()函数并创建SparkContext |
| Cluster manager | 用于获取群集上资源的外部服务(例如,standalone manager, Mesos, YARN) 像启动时设置的 spark-submit --master local[2]/spark://xxx:7077/yarn |
| Deploy mode | 部署模式,决定了你的driver跑在哪里。–deploy-mode “client” (本地)or “cluster”(集群) |
| Worker node | 可以在集群中运行应用程序代码的任何节点 (一个运行我们应用程序代码的节点 ,对于YARN来说就是nodemanager) |
| Executor | 为worker node上的应用程序启动的进程,该进程运行任务并将数据跨任务存储在内存或磁盘存储中。每个Application都有自己的Executor(执行者)。 |
| Task | (任务)一种工作单元,将发送给Executor上执行 |
| Job | (作业)这是一个并行的计算,一个计算里面包含了多个task,只要遇到一个action就是一个Job。 |
| Stage | 每个job都被分为一些smaller sets of tasks,这些任务集称为相互依赖的Stage(阶段)(类似于MapReduce中的map和reduce阶段);您会在driver的日志中看到该术语。 一个stage的边界往往是从某个地方取数据开始,到shuffle的结束 |
spark运行架构及注意事项
Spark application是运行在集群上的一组独立的进程,通过主程序(叫做driver program)里的sparkcontext对象协调。
具体来说,为了在集群上运行,SparkContext可以连接到集中Cluster manager (spark自己独立的集群管理器,或者是Mesos,或者是YARN),CM去申请资源,一旦申请并连接成功,spark会在集群上面executor,这些executor进程能够进行计算并存储我们的数据。然后,它(Driver programm)将你的应用程序的代码传到executor上面去。最终,SparkContext将你的tasks发送到executors上面去执行。
关于这种架构有几点有用的注意事项:
1、每一个application有它自己的executor进程,独立于其他application,这些进程存在于整个作业的生命周期并以多线程的形式运行我们的tasks(一个executor能够运行多个task)。这样可以在调度方(driver)(每个驱动程序调度自己的任务)和执行方(executor)(在不同JVM中运行的不同application中的tasks)之间隔离应用程序。然而,这意味着不同application之间无法分享数据,除非你将数据写在一个外部存储系统(alluxio框架,一个分布式内存的数据框架)
2、Spark与底层集群管理器(CM)无关。只要它可以获取执行executor进程,并且这些进程相互通信,即使在支持其他应用程序的集群管理器(例如Mesos / YARN)上运行它也相对容易。
3、drvier program必须在其生命周期内监听并接受来自其executor的传入连接。因此,驱动程序必须是来自工作节点的网络可寻址的。
4、因为driver在集群上调度任务,所以它应该靠近work节点运行,最好是在同一局域网上运行。如果您想远程向群集发送请求,最好向driver打开RPC并让它从附近提交操作,而不是远离工作节点运行驱动程序。
spark和hadoop重要概念区分

hadoop:
1)一个mr程序=一个job
2)一个job=1/n个task(map/reduce)
3)一个task对应于一个进程
4)task运行时开启进程,task执行完毕后摧毁进程,对于多个task来说,开销是比较大的(即使你能通JVM共享)
spark:
1)application=driver(main方法中创建sparkcontext)+executors
2)一个job=一个action
3)一个job=1/n个stage
4)一个stage=1/n个task
5)一个task对应一个线程,多个task可以以并行的方式运行在一个executor进程中
spark cache详解
cache的作用:如果一个RDD在后续的计算中可能会被使用到,那么建议cache(加入缓存之后就去读缓存,不去读磁盘了)
rdd.cache():StorageLevel-----》BlockManager
cache和transformation一样是lazy的,只有遇到action才会执行
rdd.py
def cache(self): """ Persist this RDD with the default storage level (C{MEMORY_ONLY}). """ self.is_cached = True self.persist(StorageLevel.MEMORY_ONLY) return self def persist(self, storageLevel=StorageLevel.MEMORY_ONLY): """ Set this RDD's storage level to persist its values across operations after the first time it is computed. This can only be used to assign a new storage level if the RDD does not have a storage level set yet. If no storage level is specified defaults to (C{MEMORY_ONLY}). >>> rdd = sc.parallelize(["b", "a", "c"]) >>> rdd.persist().is_cached True """ self.is_cached = True javaStorageLevel = self.ctx._getJavaStorageLevel(storageLevel) self._jrdd.persist(javaStorageLevel) return selfdef unpersist(self): """ Mark the RDD as non-persistent, and remove all blocks for it from memory and disk. """ self.is_cached = False self._jrdd.unpersist() return self
cache底层调用的是persist方法,传入的方法是StorageLevel.MEMORY_ONLY(只内存),但其实persist默认调用的也是StorageLevel.MEMORY_ONLY,所以cache()=persist()
在Python中,存储的对象将始终使用Pickle库进行序列化,因此,是否选择序列化级别都无关紧要。Python中的可用存储级别包括MEMORY_ONLY,MEMORY_ONLY_2, MEMORY_AND_DISK,MEMORY_AND_DISK_2,DISK_ONLY,和DISK_ONLY_2。
选择哪个存储级别?
Spark的存储级别旨在在内存使用率和CPU效率之间提供不同的权衡。我们建议通过以下过程选择一个:
-
如果您的RDD与默认的存储级别(
MEMORY_ONLY)相称,请保持这种状态。这是CPU效率最高的选项,允许RDD上的操作尽可能快地运行。 -
如果不是,请尝试使用
MEMORY_ONLY_SER并选择一个快速的序列化库,以使对象的空间效率更高,但仍可以快速访问。(Java和Scala) -
除非用于计算数据集的函数很昂贵,否则它们会过滤到磁盘上,否则它们会过滤大量数据。否则,重新计算分区可能与从磁盘读取分区一样快。(尽量不要选择磁盘)
-
如果要快速容错,请使用复制的存储级别(例如,如果使用Spark来处理来自Web应用程序的请求)。所有存储级别都通过重新计算丢失的数据来提供完全的容错能力,但是复制的存储级别使您可以继续在RDD上运行任务,而不必等待重新计算丢失的分区。
Spark自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)的方式丢弃旧的数据分区。如果要手动删除RDD而不是等待它脱离缓存,请使用该RDD.unpersist()方法。(unpersist()是立即执行的)
spark lineage详解
RDD数据集通过所谓的血统关系(Lineage)记住了它是如何从其它RDD中演变过来的。相比其它系统的细颗粒度的内存数据更新级别的备份或者LOG机制,RDD的Lineage记录的是粗颗粒度的特定数据转换(Transformation)操作(filter, map, join etc.)行为。当这个RDD的部分分区数据丢失时,它可以通过Lineage获取足够的信息来重新运算和恢复丢失的数据分区。
spark dependency详解
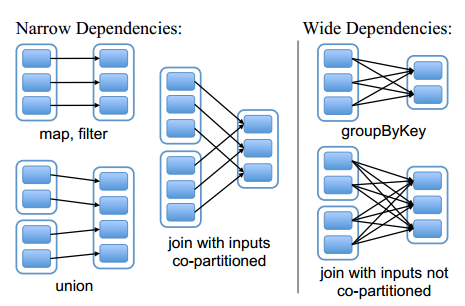
窄依赖:一个父RDD的partition最多会被子RDD的partition使用一次(pipline-able)
宽依赖:一个父RDD的partition会被子RDD的partition使用多次,有shuffle
宽依赖对于窄依赖容错机制,数据重算的时间会长一些
spark优化
监听,事后查看
$SPARK_HOME/conf/spark-env.shexport SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hdfs://pyspark-1.bigload.com:8020/directory
$SPARK_HOME/conf/spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://pyspark-1.bigload.com:8020/directory
./sbin/start-history-server.sh
http://<server-url>:18080默认情况下,这将创建一个Web界面,列出未完成和已完成的应用程序和尝试。
序列化
序列化的作用:将对象序列化为慢速格式或占用大量字节的格式将大大减慢计算速度。
序列化的选择:
Spark旨在在便利性(允许您在操作中使用任何Java类型)和性能之间取得平衡。它提供了两个序列化库:
- Java序列化:默认情况下,Spark使用Java的
ObjectOutputStream框架对对象进行序列化,并且可以与您创建的任何实现的类一起使用java.io.Serializable。您还可以通过扩展来更紧密地控制序列化的性能java.io.Externalizable。Java序列化很灵活,但是通常很慢,并且导致许多类的序列化格式很大。 - Kryo序列化:Spark还可以使用Kryo库(版本4)更快地序列化对象。与Java序列化(通常多达10倍)相比,Kryo显着更快,更紧凑,但是Kryo不支持所有
Serializable类型,并且要求您预先注册要在程序中使用的类,以实现最佳性能。最后,如果您不注册自定义类,Kryo仍然可以工作,但是必须将完整的类名与每个对象一起存储,这很浪费。
如果对象很大,则可能还需要增加spark.kryoserializer.bufferconfig。该值必须足够大以容纳要序列化的最大对象。 -
要使用Kryo注册您自己的自定义类,请使用
registerKryoClasses方法。val conf = new SparkConf().setMaster(...).setAppName(...) conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2])) val sc = new SparkContext(conf)
百度了一圈也没找到pyspark kryo序列化的文章,目前的想法是用pickle来做序列化
内存管理
Spark中的内存使用情况大体上属于以下两类之一:执行和存储。执行内存是指用于洗牌,联接,排序和聚合中的计算的内存,而存储内存是指用于在集群中缓存和传播内部数据的内存。在Spark中,执行和存储共享一个统一的区域(M)。当不使用执行内存时,存储可以获取所有可用内存,反之亦然。如果有必要,执行可能会驱逐存储,但只有在总存储内存使用率下降到某个阈值(R)以下时,该存储才会退出。换句话说,R描述了一个子区域,在该子区域M中永远不会清除缓存的块。由于实现的复杂性,存储可能无法退出执行。
这种设计确保了几种理想的性能。首先,不使用缓存的应用程序可以将整个空间用于执行,从而避免了不必要的磁盘溢出。其次,确实使用缓存的应用程序可以保留最小的存储空间(R),以免其数据块被逐出。最后,这种方法可为各种工作负载提供合理的即用即用性能,而无需用户了解如何在内部划分内存。
尽管有两种相关的配置,但典型用户无需调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction表示的大小M为(JVM堆空间-300MB)的一部分(默认值为0.6)。其余的空间(40%)保留用于用户数据结构,Spark中的内部元数据,并在记录稀疏和异常大的情况下防止OOM错误。spark.memory.storageFraction将的大小表示R为的一部分M(默认为0.5)。R是M其中的缓存块不受执行影响而退出的存储空间。
spark.memory.fraction应该设置的值,以便在JVM的旧版本或“长期使用的”一代中舒适地适应此堆空间量。
广播变量
广播变量使程序员可以在每台计算机上保留一个只读变量,而不用随任务一起发送它的副本。例如,可以使用它们以高效的方式为每个节点提供大型输入数据集的副本。Spark还尝试使用有效的广播算法分配广播变量,以降低通信成本。
spark action是通过一组阶段执行的,这些阶段由分布式“随机”操作分隔。Spark自动广播每个阶段中任务所需的通用数据。在运行每个任务之前,以这种方式广播的数据以序列化形式缓存并反序列化。这意味着仅当跨多个阶段的任务需要相同数据或以反序列化形式缓存数据非常重要时,显式创建广播变量才有用。
v通过调用从变量创建广播变量SparkContext.broadcast(v)。broadcast变量是的包装v,可以通过调用value 方法访问其值。下面的代码显示了这一点:
>>> broadcastVar = sc.broadcast([1, 2, 3])
<pyspark.broadcast.Broadcast object at 0x102789f10>
>>> broadcastVar.value
[1, 2, 3]广播大变量
使用中 可用的广播功能SparkContext可以极大地减少每个序列化任务的大小,以及在群集上启动作业的成本。如果您的任务使用驱动程序中的任何大对象(例如,静态查找表),请考虑将其转换为广播变量。Spark在主服务器上打印每个任务的序列化大小,因此您可以查看它来确定任务是否太大;通常,大约20 KB以上的任务可能值得优化。
数据本地性操作
数据局部性可能会对Spark作业的性能产生重大影响。如果数据和对其进行操作的代码在一起,则计算速度往往会很快。但是,如果代码和数据是分开的,那么一个必须移到另一个。通常,从一个地方到另一个地方传送序列化代码要比块数据更快,因为代码大小比数据小得多。Spark围绕此数据本地性一般原则构建调度。
数据局部性是数据与处理它的代码之间的接近程度。根据数据的当前位置,可分为多个级别。从最远到最远的顺序:
PROCESS_LOCAL数据与正在运行的代码位于同一JVM中。这是最好的位置NODE_LOCAL数据在同一节点上。示例可能在同一节点上的HDFS中,或者在同一节点上的另一执行程序中。这比PROCESS_LOCAL由于数据必须在进程之间传输而要慢一些NO_PREF可以从任何地方快速访问数据,并且不受位置限制RACK_LOCAL数据在同一服务器机架上。数据位于同一机架上的其他服务器上,因此通常需要通过单个交换机通过网络发送ANY数据在网络上的其他位置,而不是在同一机架中
Spark倾向于在最佳位置级别安排所有任务,但这并不总是可能的。在任何空闲执行器上没有未处理数据的情况下,Spark会切换到较低的本地级别。有两种选择:a)等待忙碌的CPU释放以在同一服务器上的数据上启动任务,或b)立即在需要将数据移动到更远的地方启动新任务。
Spark通常要做的是稍等一下,以期释放繁忙的CPU。一旦超时到期,它将开始将数据从很远的地方移到空闲的CPU中。每个级别之间的回退等待超时可以单独配置,也可以一起配置在一个参数中。有关详细信息,请参见配置页面spark.locality上的 参数。如果您的任务很长并且位置不佳,则应该增加这些设置,但是默认设置通常效果很好。