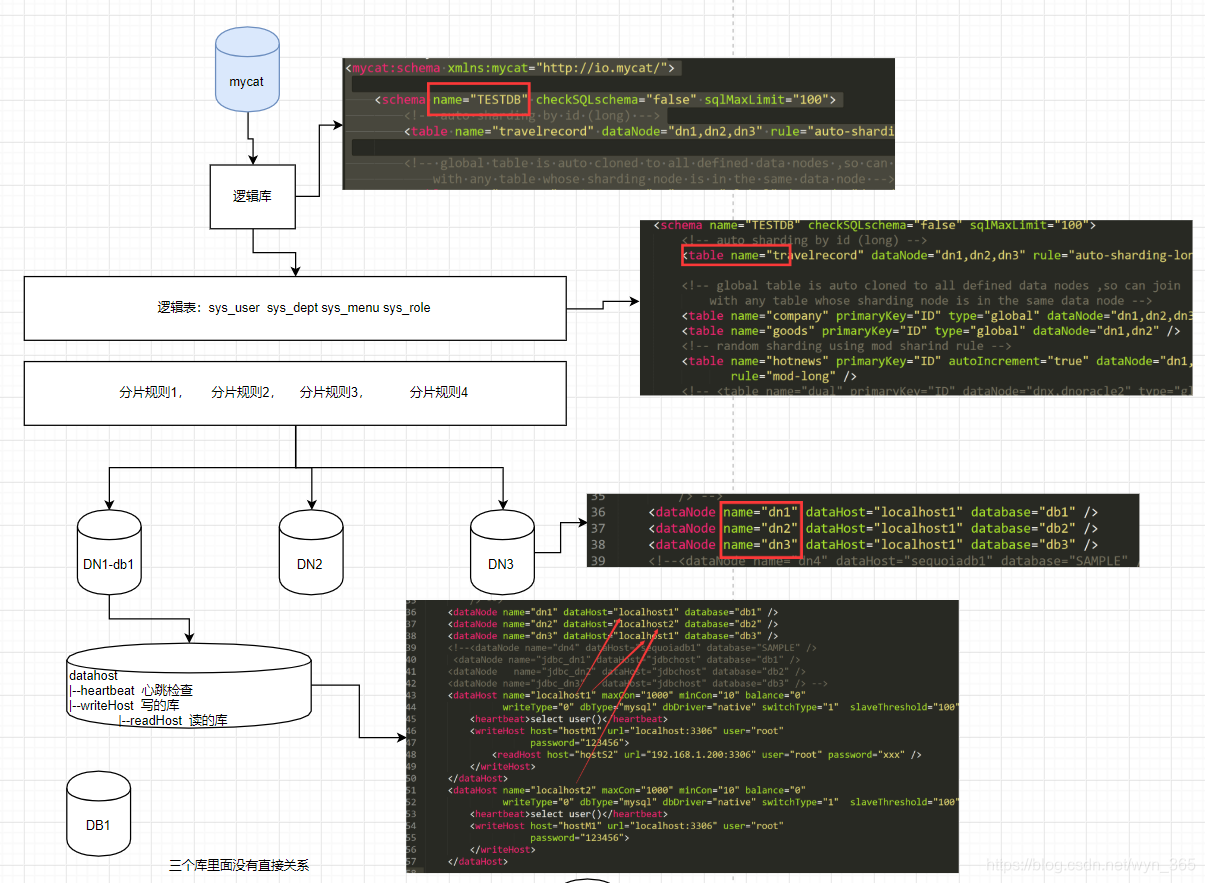
1,逻辑库
对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
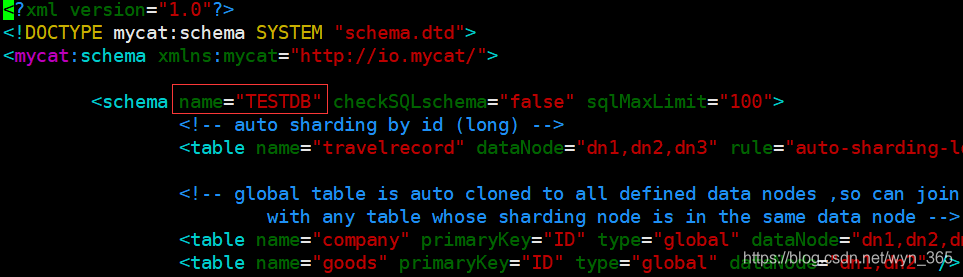
如图一中,在MYCAT服务区中的TESTDB库,只是逻辑上存在的数据库,真正的数据来源还是来源MYSQL服务区中的两台实际的Mysql db实例。
在Mycat中逻辑库在{MYCAT_HOME}/conf/schema.xml 用 标签定义。如图:
2,逻辑表
既然有逻辑库,肯定将会存在逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。
逻辑表的数据来源,可以是数据进行切分后,分布在一个或多个分片库中,针对不同的数据分布和管理特点,我们将逻辑表又分为分片表、全局表、全局表、ER表、非分片表五种逻辑表类型。在schema.xml使用
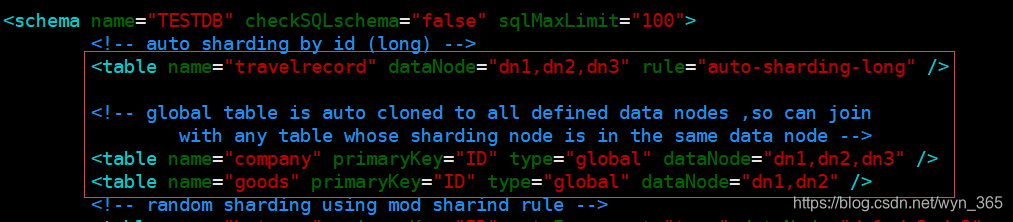
3,分片表
是指那些原有的很大数据的表,需要切分到多个表,这样,每个分片都有表的一部分数据,所有分片数据的合集构成了完整的表数据,如图一种中MYCAT服务区的users表即是分片表,通过userID字段取模的方式进行数据的水平切分。
如图中用户(company)表:

4,分片规则
将大数据的表,切分到多个数据分片的策略。如图三中rule=“mod-userID-long”,名字为mod-userID-long引用的详细规则,将在MYCAT的rule.xml中({MYCAT_HOME}/conf/rule.xml)中进行定义,具体定义规则如图:
分片规则Mycat中内置了很多种,比如按时间、按自定义数字范围、十进制取模、程序指定,字符串Hash,一致性Hash等等,总体可将这些分片规则分为离散型和连续型两种分片规则。
离散型分片规则数据分布均衡,对数据的处理并发能力强,但是对于分片的扩缩容存在较大的挑战。连续性分片数据分布较集中,更符合业务特性,但是对数据的处理并发能力受限数据的分布,分片的扩缩容有更好的支持。
5,全局表
一个真实的业务系统中,往往存在大量的类似数据字典表的表,数据字典表具有以下几个特性:
• 数据变动不频繁;
• 数据规模不大,数据量在十万以内;
• 存在跟其他表(特别是分片表)有一点的关联查询要求。
为了解决表与表的join查询,Mycat提倡大家将具有上诉特点的表通过数据冗余的方式(全局表的定义)进行解决,即所有的分片都有一份数据的拷贝。通过MYCAT对这样的表进行数据的操作时,数据的修改,新增,删除时,所有的分片数据都将受到影响。
设置方式非常简单如下图

6,ER表(一对多,多对一)
关系型数据库是基于实体关系模型(Entity-Relationship Model)之上,通过其描述了真实世界中事物与关系,Mycat 中的 ER 表即是来源于此。
根据这一思路,提出了基于 E-R 关系的数据分片策略,子表的记录与所关联的父表记录存放在同一个数据分片上,即子表依赖于父表,通过表分组(Table Group)保证数据 Join 不会跨库操作。
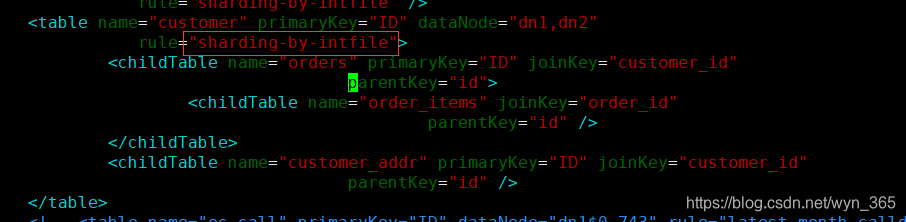
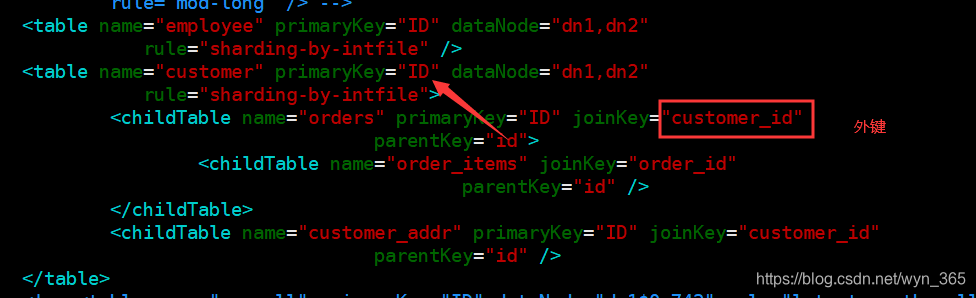
这样一种表分组的设计方式是解决跨分片数据 join 的一种很好的思路,也是数据切分规划的重要一条规则。ER表中在schema.xml中使用标签进行描述和定义
如图
7,非分片表
一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。在schema.xml中具体的定义,可参见图七:

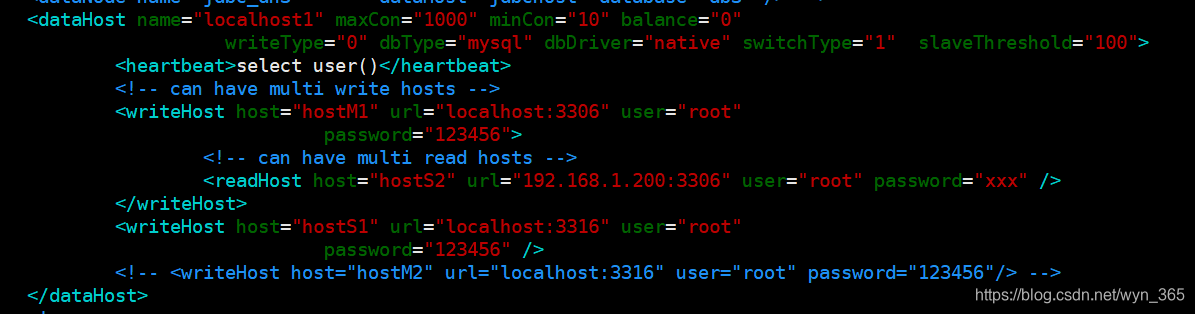
8,分片节点
大数据表进行数据切分后,每个表分片所在的数据库就是分片节点,狭义的理解可以认为一个DB实例就是一个节点,在schema.xml中使用进行分片节点的定义如图八:

9,节点主机
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机,为了规避单节点主机并发数限制。
尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机,在schema.xml中使用进行分片节点的定义如图