文章目录
一、HashMap和Hashtable历史叙旧
都知道JAVA中有三大集合List , Set, Map,前两个继承自Collection接口,Map是一个独立的接口,今天主要谈谈Map下的HashMap;Map有三个实现类HashMap、TreeMap和HashTable
Hashtable比HashMap出现的要早,在java一开始发布时就提供的键值映射的数据结构,也就是Key-Value模型;而HashMap产生于JDK1.2,早不代表好,现在主要用的还是HashMap。能被广泛使用还是有它的优势的,比如它查找的时间复杂度是O(1),是不是很牛,下来详细看
二、什么是HashMap
HashMap是一个key-value模型,具有映射关系,内部所用的数据结构是数组+链表/红黑树 ,通过key值可以找到value值,(把皇上当做key,它的那些妃子们就是很多个value,不太恰当,哈哈哈)并允许使用null值和null键,就是key和value的取值都可以为空,但key最多只能允许一个为空,多了的话就会覆盖;Hashtable的key就不允许为空。HashMap不保证映射的顺序,特别是它不保证该顺序恒久不变。
三、HashMa的常用方法
1、put( key,value):就是往里面添加元素,将键映射存放到Map集合中,key不允许重复,要不然会覆盖以前的值
2、get(Object key) :相当于查看,返回指定键所映射的值,没有该key对应的值则返回 null
3、size() :返回Map集合中数据数量,
4、clear() :清空Map集合
5、isEmpty () 判断Map集合中是否有数据,如果没有则返回true,否则返回false
6、remove(Object key) :删除Map集合中键为key的数据并返回其所对应value值。
7、values() :返回Map集合中所有value组成的以Collection数据类型格式数据。
8、containsKey(Object key) 判断集合中是否包含指定键,包含返回 true,否则返回false
9、containsValue(Object value) 判断集合中是否包含指定值,包含返回 true,否则返回false
10、keySet() 返回Map集合中所有key组成的Set集合
11、entrySet() 将Map集合每个key-value转换为一个Entry对象并返回由所有的Entry对象组成的Set集合
部分方法示例
import java.util.HashMap;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> map = new HashMap<>();//定义一个map
map.put("李白", "1");//存放键值对
System.out.println(map.containsKey("李白"));//键中是否包含这个数据,打印结果为true
System.out.println(map.containsKey("王维"));//打印结果为false
System.out.println(map.get("李白"));//通过键拿值,打印结果是1
System.out.println(map.get("王维"));//打印结果为null
System.out.println(map.isEmpty());//判空,打印结果为false
System.out.println(map.size());//输出map的大小,打印结果为1
System.out.println(map.remove("李白"));//从键值中删除.打印结果为1
System.out.println(map.containsKey("李白"));//删除了所以不包含了,输出false
System.out.println(map.isEmpty());//现在就为空是,输出true
map.put("杜甫", "2");
System.out.println(map.get("杜甫"));
map.put("陶渊明", "3");
System.out.println(map.get("陶渊明"));
map.put("杜甫", "4");
map.put("陶渊明", "6");
for (String key : map.keySet()) {
System.out.println(key);
}
System.out.println("====================");
for (String values : map.values()) {
System.out.println(values);
}
}
}
三、简述HashMap的工作原理
通过hash的方法,通过put和get存储和获取对象,put就是往里面放东西,get就相当于查看。存储对象时,我们将K/V传给put方法时,它调用K对象的hashCode计算hash从而得到bucket位置,进一步存储。
HashMap会根据当前bucket的占用情况自动调整容量,超过负载因子就扩容为原来的二倍,获取对象时,我们将K传给get,get调用K对象的hashCode计算hash从而得到bucket位置,并进一步调用K对象的equals()方法确定键值对。所以put和get方法特别的重要;如果发生碰撞的时候,Hashmap通过链表将产生碰撞冲突的元素组织起来,在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度 。
put方法的原理:
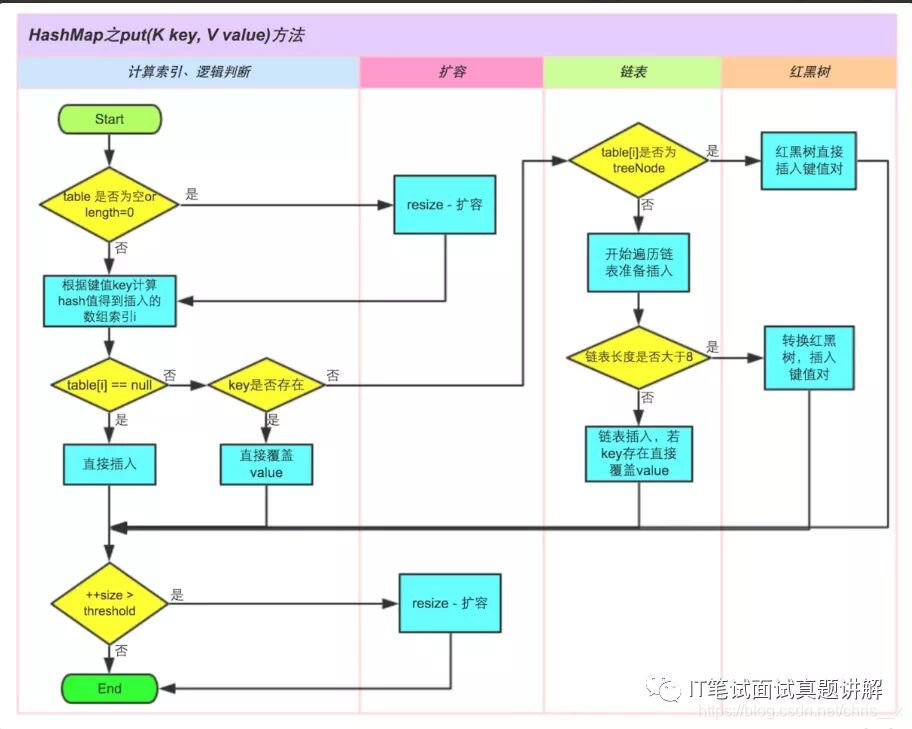
HashMap中的equals()和hashCode()的作用
通过对key的hashCode()做哈希,并计算下标,从而获得buckets的位置。如果产生碰撞,则利用key.equals()方法去链表或树中去查找对应的节点 ,另外也是为了保持数据一致性。
四、HashMap的冲突及负载因子
先来了解一下哈希函数,讲一下除留余数法
hash(key)=key%capacity;比如下面capacity=10;
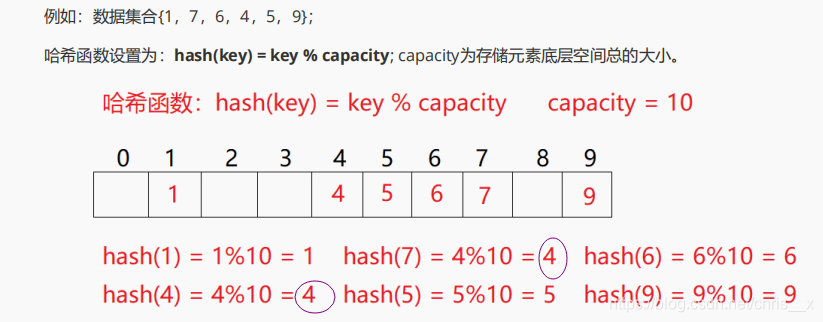
这样除留余数就会有两个相等的,这就是冲突;所以就引出了负载因子;HashMap的默认负载因子为0.75,如果超过0.75,会重新resize一个原来长度两倍的HashMap,并且重新调用hash方法 ,对原来的数据进行重新hash。
怎样解决冲突? 开散列 闭散列
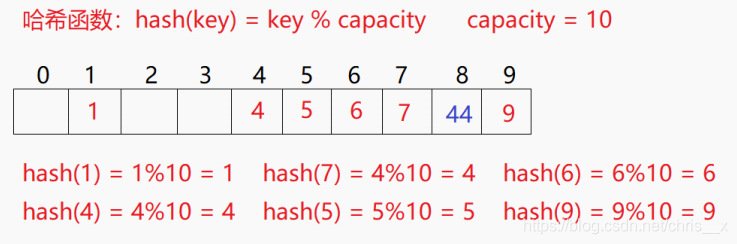
闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去。那如何寻找下一个空位置呢?H(key)=key%表的长度
1、线性探测:就是找从你求的余数的那个位置往后的第一个空比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该4位置,但是该位置已经放了值为4的元素,即发生哈希冲突。从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。那就找到8那儿了
2、二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法:
= (
+
)% m,或者:
= (
-
)% m。其中:i = 1,2,3…,
是通过散列函数Hash(x)对元素的关键码 key;公式有点蒙,看图上的计算过程就好懂多了
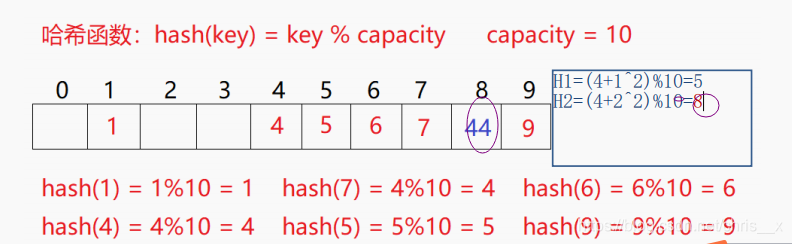
研究表明:当表的长度为质数且表装载因子a不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次。因此只要表中有一半的空位置,就不会存在表满的问题。在搜索时可以不考虑表装满的情况,但在插入时必须确保表的装载因子a不超过0.5,如果超出必须考虑增容。
因此:比散列最大的缺陷就是空间利用率比较低,这也是哈希的缺陷。
开散列法又叫==链地址法(开链法)==开散列法(哈希桶) :又名链地址法,先用哈希函数计算每个数据的散列地址,把具有相同地址的元素归于同一个集合之中,把该集合处理为一-个链表,链表的头节点存储于哈希表之中。例如:还是.上面闭散列中的例子,当使用开散列的方法后,其每个元素的存储为下图所示:
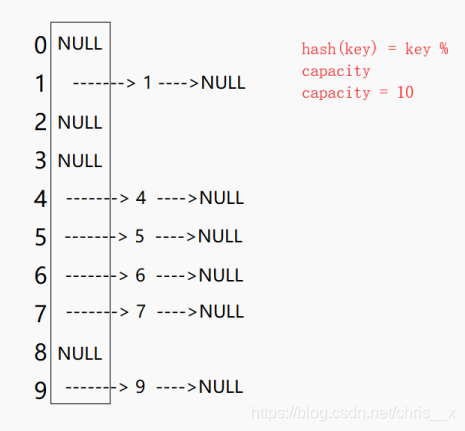
开散列的优点:有效的解决了数据溢出,不过需要增设链接指针,增加了存储的开销。但是,总体而言,效率还是快的多
五、HashMap和HashTable的区别有哪些?
1、Hashtable是线程安全,HashMap是非线程安全。
2、HashMap可以使用null作为key,不过建议还是尽量避免这样使用。HashMap以null作为key时,总是存储在table数组的第一个节点上。而Hashtable则不允许null作为key
3、HashMap的初始容量为16,Hashtable初始容量为11
4、Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模,HashMap计算hash对key的hashcode进行了二次hash,以获得更好的散列值,然后对table数组长度取模
5、非并发场景使用HashMap,并发场景可以使用Hashtable,但是推荐使用ConcurrentHashMap(锁粒度更低、效率更高)。
HashMap在1.8以后所做的改进
- 数组+链表改成了数组+链表或红黑树
- 链表的插入方式从头插法改成了尾插法
- 扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;
- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;