文章目录
GLMP
ABSTRACT
面向任务的端到端对话,因为知识库通常很大,动态性强,很难融入学习框架而具有挑战性。
在我们的模型中,我们提出了一个全局记忆编码器和一个局部记忆解码器来共享外部知识。
编码器对对话历史记录进行编码,修改全局上下文表示,并生成全局记忆指针。
解码器首先生成一个带有未填充槽的回复草图,之后传递全局记忆指针来过滤相关信息的外部知识,然后通过本地记忆指针插入插槽。
GLMP可以提高复制精度,并减轻常见的未登录词(out-of-vocabulary)问题。
1.INTRODUCTION
传统的流水线解决方案由自然语言理解、对话管理和自然语言生成三部分组成。
端到端的优点在于对话状态是隐藏的,不需要手工制作标签,并且无需对模块之间的依赖关系建模和手工解释知识库。
但端到端系统通常无法有效地将外部知识合并到系统中,动态的大型KB等同于噪声输入,难以编解码,这使得生成不稳定。不同于闲聊,这对于任务型对话有很大的影响,因为KB信息通常是回复中预期的实体。
因此,指针网络(pointer network)或复制机制(copy mechanis)对于成功生成系统回复至关重要,因为直接将关键字从输入源复制到输出端不仅降低了生成难度,同时也因为如此更符合人类习惯。
我们提出了全局到本地记忆指针(GLMP)网络,它由一个全局记忆编码器、一个本地记忆解码器和一个共享的外部知识库组成。
不同于现有的复制方法:唯一传递给解码器的信息是编码器的隐藏状态,我们的模型共享外部知识,并利用编码器和外部知识来学习全局记忆指针和全局上下文表示。
- 全局记忆指针通过软过滤不需要复制的单词来修改外部知识。
- 本地存储解码器不再直接生成系统响应,而是首先使用sketch RNN获得没有插槽值但有草图标签的草图回复。这里可以被认为是学习一个潜在的对话管理生成对话行为模板。
- 解码器生成本地记忆指针,以从外部知识复制单词并实例化草图标记。
2.GLMP MODEL
我们的模型由三部分组成:全局记忆编码器、外部知识和本地记忆解码器。

- 全局记忆编码器使用context RNN对对话历史进行编码,并将其隐藏状态写入外部知识。
- 使用最后一个隐藏状态读取外部知识,同时生成全局记忆指针。
- 解码阶段,本地存储器解码器首先通过一个sketch RNN生成草图回复。
- 将全局记忆指针和sketch RNN隐藏状态作为一个 filter 和一个 query 传递给外部知识。
从外部知识返回的本地记忆指针可以从外部知识中复制文本来替换sketch标记,并获得最终的系统回复。
2.1 EXTERNAL KNOWLEDGE
我们的外部知识包含与编码器和解码器共享的全局上下文表示。
为了将外部知识整合到学习框架中,端到端记忆网络(MN)用于存储结构知识库(KB memory)和与临时的对话历史(dialogue memory)的单词级信息。MN以其多跳推理能力(multiple hop reasoning ability)而闻名。这似乎是为了加强复制机制。
全局上下文表示
在KB记忆模块中,每个元素
以
结构的三元组表示。
对话记忆模块中,对话上下文
表示为
对于这两个记忆模块,使用一个词袋表示作为记忆嵌入。在推理期间,一旦指向某个记忆位置,我们就复制指向的对象单词,例如,如果选择了triplet
,就会复制
。
函数的作用是:从三元组中获取目标词。
知识读和写
我们的外部知识是由一系列可训练的嵌入矩阵组成的
, 其中
,
是MN最大的memory hop,
为词汇量,
为嵌入维数。我们把外部知识中的记忆表示为
其中
是所提到的三元组成分之一。要读取记忆,外部知识需要一个初始查询向量
。此外,它可以循环遍历
并用下方公式计算每个
的注意权值
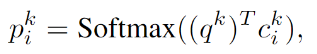
其中
是 用嵌入矩阵
查找到的第
个记忆位置,
是第
个
的查询向量,而
是词袋函数。注意
是一种软记忆注意,它决定了与查询向量的记忆相关度。然后模型通过对
加权求和读取出记忆
并更新查询向量
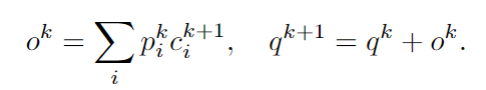

2.2 GLOBALMEMORY ENCODER
context RNN用于建立顺序依赖关系,并对上下文
进行编码。之后将隐藏状态写入外部知识。最后一个编码器隐藏状态作为查询,读取外部知识,得到两个输出:全局记忆指针和记忆读取器。直观地说,MN结构很难对记忆之间的依赖关系进行建模,这是一个严重的缺陷,尤其是在与会话相关的任务中,将隐藏状态写入外部知识可以提供顺序和融合了上下文的信息。通过有意义的表示,我们的指针可以正确地从外部知识中复制单词,并且可以减轻常见的OOV挑战。此外,使用已编码的对话上下文作为查询可以鼓励我们的外部知识读取与隐藏对话状态或用户意图相关的记忆信息。此外,学习全局记忆分布的全局记忆指针与编码的对话历史和KB信息一起传递给解码器。
Context RNN
用于将对话历史记录编码到隐藏状态的双向GRU,最后一个隐藏状态将作为编码的对话历史来对外部知识进行查询。此外,通过将原记忆表示与对应的隐藏状态相加,将隐藏状态重新写入外部知识的对话记忆模块中。
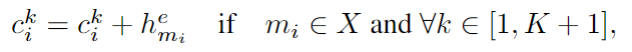
Global memory pointer
全局记忆指针
是一个包含0到1之间的实数的向量。不同于传统的注意机制,所有的权重加起来等于一,每个元素的概率都是独立的。
我们首先使用
查询外部知识,直到最后一跳(hop),我们执行一个内积
Sigmoid函数而不是Softmax函数。我们得到的记忆分布是全局记忆指针G,它被传递给解码器。为了进一步增强全局指向能力,我们增加了一个辅助损失,将全局内存指针训练成一个多标签分类任务。我们在消融研究中发现,增加这种额外的监护确实能提高性能。最后,使用记忆读出器
作为已编码的KB信息。
在辅助任务中,我们通过检查记忆中的目标实体单词是否存在于预期的系统回复
中,来定义标签
之后全局记忆指针通过
和
的二分类交叉熵来训练。
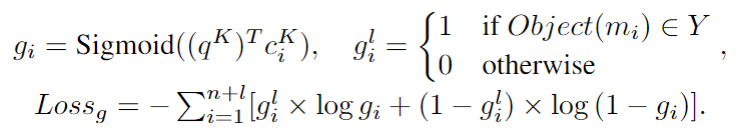
2.3 LOCAL MEMORY DECODER
给定已编码的对话历史 、已编码的KB信息 和全局记忆指针 ,我们的本地记忆解码器首先链接 和 来初始化它的草图RNN,生成一个排除槽值但包含草图标记的草图回复。比如, sketch RNN 将生成 “@poi is @distance away”, 而非 “Starbucks is 1 mile away.”在每个解码时间步,草图RNN的隐藏状态用于两个目的:
- 预测词汇表中的下一个token,它与标准的Seq2Seq相同
- 作为查询外部知识的向量
如果生成了一个草图标记,全局记忆指针将传递给外部知识,预期的输出单词将从本地记忆指针获得。否则,输出单词就是草图RNN生成的单词。
Sketch RNN
我们使用GRU生成没有真正槽值的草图回复
Sketch RNN学习生成一个基于对话编码
和KB信息
的动态对话行为模板,在每个解码时间步,Sketch RNN隐藏状态
及其输出分布
定义为
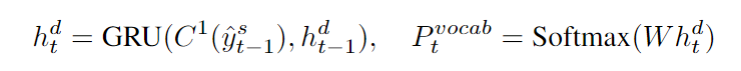
我们使用标准的交叉熵损失来训练Sketch RNN
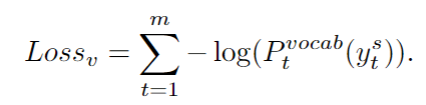
Local memory pointer
本地记忆指针
包含一个指针序列。每个时间步
,全局记忆指针首先使用其注意力权重修改全局上下文表示
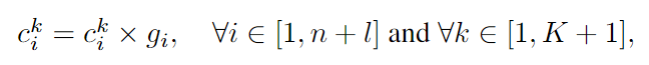
然后Sketch RNN隐藏状态
对外部知识进行查询。最后一跳中的记忆注意对应于本地记忆指针
,表示为时间步
的记忆分布。为了训练本地记忆指针,在最后一跳记忆注意的外部知识上增加一个监督。我们首先定义解码时间步的本地记忆指针
的位置标签
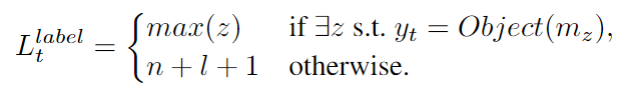
位置
是记忆中的一个空标记,它允许我们在即使外部知识中不存在该函数时也可以计算损失函数。

此外,我们利用
来防止相同实体被复制多次,所有在
中的元素在开始时都初始化为1。在解码阶段,如果一个记忆位置被指向,它在
中的相应位置将被屏蔽。在推理阶段:
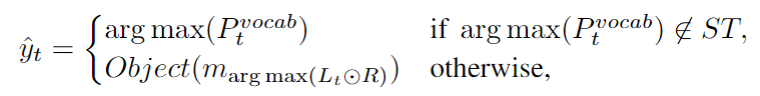
其中
是元素对应相乘。最后,通过对三个损失的加权和进行最小化,对所有参数进行联合训练。
是超参数。
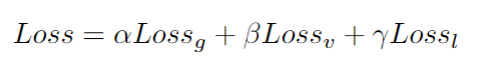
3. EXPERIMENTS
3.1 DATASETS
bAbI dialogue
bAbI dialogue包括五个餐厅领域的模拟任务。任务1到4分别是关于调用API调用、修改API调用、推荐选项和提供附加信息。Task 5是Task 1-4的并集。每个任务有两个测试集:一个遵循与训练集相同的分布,另一个具有OOV实体值。
SMD
一个人-人多领域对话数据集。它有三个不同的领域:日历调度、天气信息检索和兴趣点导航。这两个数据集的关键区别在于,前者的对话周期较长,但用户和系统的行为是常规的,后者只有很少的会话转折,但是有不同的响应,而且知识库信息要复杂得多。
3.2 TRAINING DETAILS
- Adam lr 1e-3 ~ 1e-4
- hop K 1,3,6
- summing up the three losses are set to 1
- embeddings 随机初始化
- 在解调阶段,仅采用了一种简单的贪婪策略,没有进行beam-search。
- 超参数如hidden size和dropout是基于开发集(bAbI对话的每回复准确度和SMD的BLEU得分)通过网格搜索来调整的
- 为了增强模型泛化和模拟OOV设置,我们将少量输入源token随机屏蔽为未知token。
3.3 RESULTS
bAbI Dialogue

根据每个回复的准确率和任务完成率来衡量表现。
值得注意的是,对于检索式模型,如QRN、MN、GMN等,不能正确地推荐选项(T3)和提供附加信息(T4),并且在OOV设置中泛化能力较差,在Task 5中存在约30%的性能差异。尽管以前的基于生成的方法(Ptr-Unk,Mem2Seq)通过加入复制机制来减少这种差距,但是最简单的情况,比如生成和修改API调用(T1, T2),仍然面临着6-17%的OOV性能下降。另一方面,GLMP在所有对话任务中实现了最高的92.0%的任务完成率,并以较大的优势超过了其他基线,特别是在OOV设置中。仅使用单跳,每个回复的精度在T1、T2、T4上没有损失,在task 5中仅下降7-9%。
Stanford Multi-domain Dialogue
我们遵循之前的对话工作用两个自动评价指标:BLEU和entity F1评分来评价我们的系统

glmp取得了最高的14.79 BLEU和59.97% entity F1的分数,BLEU增加不多,但在entity F1上是一个巨大的进步。事实上,对于面向任务的对话中的非监督评估指标,我们认为entity F1可能是比每个回复的准确率或BLEU更全面的评估指标。Eric等人(2017)的研究表明,人类能够选择正确的实体,但有非常多样化的反应。注意,基于规则和KVR的结果并不是直接可比较的,因为它们通过使用命名实体识别和链接将实体的表达式映射到标准形式,从而简化了任务。
此外,还报告了人类对产生的反应的评价。我们将我们的工作与先前的最先进的模型mem2seq以及原始数据集的响应进行了比较。我们随机从测试集中选择200个不同的对话场景来评估三种不同的反应。Amazon-Mechanical-Turk用于评估系统的适当性和人类的相似性,范围从1到5。我们可以看到GLMP在这两个方面都优于Mem2Seq,这与之前的观察是一致的。我们还看到,人类在该评估中的表现设置了分数的上限,这与预期一致。关于人体评估的更多细节在附录中有报道。
Ablation Study
全局记忆指针 G 和 历史对话记忆 H 的贡献如图所示。

我们比较了使用GLMP
在bAbIOOV和SMD的结果。
GLMP w/o H 表示context RNN在全局记忆编码器中不把隐藏状态写入外部知识。
GLMP w/o G 意味着我们不使用全局记忆指针来修改外部知识。
注意,在task 5中可以观察到0.4%的增长,这表明使用全局记忆指针可能会施加太大的先验实体概率。即使我们只在表中报告一个实验,这个OOV泛化问题也可以通过在训练过程中增加dropout率来缓解。
Visualization and Qualitative Evaluation
分析注意力的权重是解释深度学习模型的常用方法。在下图中,我们显示了每一生成时间步的最后一跳的注意向量。Y轴是我们可以复制的外部知识,包括KB信息和对话历史。根据:“what is the address?”在最后一轮中司机的问题,最佳答案和我们生成的回答在顶部,全局记忆指针 G 显示在左边一栏。可以看到,在右栏中,最后的记忆指针成功地在step 0复制了实体 chevron 及step 3复制了地址783 Arcadia Pl,以填充草稿回复。另一方面,没有全局加权的记忆注意在中间一栏中报告。你会发现,即使注意力集中在step 0和step 3中的多个兴趣点和地址上时,全局记忆指针仍可以像预期的那样缓解这个问题。

4 RELATED WORKS
Task-oriented dialogue systems
基于机器学习的对话系统主要采用模块化和端到端两种不同的方法进行研究。对于模块化系统, 用到了自然语言理解,对话状态跟踪,对话管理,自然语言生成等一系列模块集。这些方法通过结合领域特定的知识和插槽填充技术来实现良好的稳定性,但是还需要附加的人工标签。另一方面,端到端方法近年来也表现出良好的效果。一些学者把任务看作是下一个话语的检索问题,例如,recurrent entity networks在RNN之间共享参数,query reduction networks修改层间查询,memory net-works通过多跳设计,增强推理能力。此外,一些方法将任务视为一个序列生成问题, Lei et al. (2018) 将显式对话状态跟踪到去模块化序列生成中, Serban et al. (2016); Zhao et al. (2017) 利用RNN生成最终回复,取得了良好的效果。尽管它可能会增加搜索空间,这些方法可以通过token-by-token生成回答的传递机制来鼓励更灵活和更多样的系统响应。
Pointer network
使用注意力作为一个指针,选择输入语句的一个成员作为输出。这种复制机制也被用于其他自然语言处理任务中,比如问答系统,机器翻译,语言模型,文本摘要等。在以任务为导向的对话任务中首先展示了增加复制的Seq2Seq模型的潜力,这表明基于生成的方法与简单的复制策略可以超越基于检索的方法。之后,通过连接知识库注意力来扩展词汇表分布,同时将输出维度添加进来。最近,合并端到端记忆网络生成序列,这表明多跳机制可以用来提高复制注意。这些模型通过从KB中复制相关信息来超越检索方法。
Others
Zhao et al. (2017) 提出实体索引, Wu et al. (2018) i引入了recorded delexicalization,通过手动记录实体表来简化问题。此外,记忆增强神经网络(MANN)中我们利用RNN结构来查询外部记忆的方法可以看作是记忆控制器。类似地,记忆编码器也被用于神经机器翻译和元学习应用。然而,与其他使用单个矩阵表示进行读写的模型不同,GLMP利用端到端内存网络执行多跳注意,这类似于Transformer中的堆叠自我注意策略。
代码阅读及调试
惯例:数字仅代表逻辑层次,方便看清函数进入到了第几层。
myTrain.py
from utils.config import *
标准的argparse定义各项输入参数,本次调试中的设置如下:
{'dataset': 'babi', 'task': '1', 'decoder': 'GLMP', 'hidden': '128', 'batch': '8', 'learn': '0.001', 'drop': '0.2', 'unk_mask': 1, 'layer': '1', 'limit': -10000, 'path': None, 'clip': 10, 'teacher_forcing_ratio': 0.5, 'sample': None, 'evalp': 1, 'addName': '', 'genSample': 0, 'earlyStop': 'BLEU', 'ablationG': 0, 'ablationH': 0, 'record': 0}
USE_CUDA: True
额外参数设置
early_stop = args['earlyStop']
if args['dataset']=='kvr':
from utils.utils_Ent_kvr import *
early_stop = 'BLEU' / 判断提前停止的训练的指标
elif args['dataset']=='babi': / 训练数据集
from utils.utils_Ent_babi import *
early_stop = None
if args["task"] not in ['1','2','3','4','5']: / 训练任务(数据集选择)
print("[ERROR] You need to provide the correct --task information")
exit(1)
else:
print("[ERROR] You need to provide the --dataset information")
# Configure models and load data
avg_best, cnt, acc = 0.0, 0, 0.0
train, dev, test, testOOV, lang, max_resp_len = prepare_data_seq(args['task'], batch_size=int(args['batch']))
def prepare_data_seq(task, batch_size=100):
data_path = 'data/dialog-bAbI-tasks/dialog-babi'
file_train = '{}-task{}trn.txt'.format(data_path, task)
file_dev = '{}-task{}dev.txt'.format(data_path, task)
file_test = '{}-task{}tst.txt'.format(data_path, task)
kb_path = data_path+'-kb-all.txt'
file_test_OOV = '{}-task{}tst-OOV.txt'.format(data_path, task)
type_dict = get_type_dict(kb_path, dstc2=False) / <--
global_ent = entityList('data/dialog-bAbI-tasks/dialog-babi-kb-all.txt',int(task))
...
...
def get_type_dict(kb_path, dstc2=False):
"""
Specifically, we augment the vocabulary with some special words, one for each of the KB entity types
For each type, the corresponding type word is added to the candidate representation if a word is found that appears
1) as a KB entity of that type,
"""
type_dict = {'R_restaurant':[]}
kb_path_temp = kb_path
fd = open(kb_path_temp,'r')
for line in fd:
if dstc2: / 本次调试为Fasle,显然是与数据集格式相关的设置
x = line.replace('\n','').split(' ')
rest_name = x[1]
entity = x[2]
entity_value = x[3]
else:
x = line.split('\t')[0].split(' ')
rest_name = x[1]
entity = x[2]
entity_value = line.split('\t')[1].replace('\n','')
if rest_name not in type_dict['R_restaurant']:
type_dict['R_restaurant'].append(rest_name)
if entity not in type_dict.keys():
type_dict[entity] = []
if entity_value not in type_dict[entity]:
type_dict[entity].append(entity_value)
return type_dict
来看几条 的数据
1 resto_seoul_cheap_korean_1stars R_cuisine korean
1 resto_seoul_cheap_korean_1stars R_location seoul
1 resto_seoul_cheap_korean_1stars R_price cheap
- 1:可能是对应任务序号?但整个数据集该属性均为1,且这部分并未读取
- resto_seoul_cheap_korean_1stars:餐厅名称 三元组中的实体
- R_cuisine :餐厅属性 三元组中的属性
- korean:对应值 三元组中的值
x = line.split('\t')[0].split(' ')
rest_name = x[1]
entity = x[2]
entity_value = line.split('\t')[1].replace('\n','')
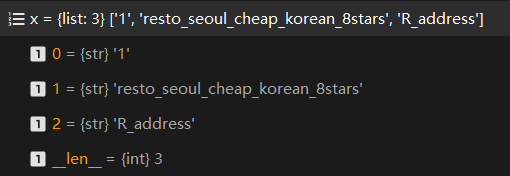


即生成了KB词表
def prepare_data_seq(task, batch_size=100):
...
...
type_dict = get_type_dict(kb_path, dstc2=False) / -->
global_ent = entityList('data/dialog-bAbI-tasks/dialog-babi-kb-all.txt',int(task))
...
...
def entityList(kb_path, task_id):
type_dict = get_type_dict(kb_path, dstc2=(task_id==6)) / 就是上面生成KB词表的函数哦
entity_list = []
for key in type_dict.keys():
for value in type_dict[key]:
entity_list.append(value) / 将词表中的所有实体(值)加入entity_list
return entity_list

pair_train, train_max_len = read_langs(file_train, global_ent, type_dict)
pair_dev, dev_max_len = read_langs(file_dev, global_ent, type_dict)
pair_test, test_max_len = read_langs(file_test, global_ent, type_dict)
pair_testoov, testoov_max_len = read_langs(file_test_OOV, global_ent, type_dict)
max_resp_len = max(train_max_len, dev_max_len, test_max_len, testoov_max_len) + 1
def read_langs(file_name, global_entity, type_dict, max_line = None):
# print(("Reading lines from {}".format(file_name)))
data, context_arr, conv_arr, kb_arr = [], [], [], []
max_resp_len, sample_counter = 0, 0
with open(file_name) as fin:
cnt_lin = 1
for line in fin:
line = line.strip()
if line:
nid, line = line.split(' ', 1) / 对话轮数 ,对话信息
# print("line", line)
if '\t' in line:
u, r = line.split('\t') / User,SystemResponse
gen_u = generate_memory(u, "$u", str(nid)) / <--
context_arr += gen_u
conv_arr += gen_u
ptr_index, ent_words = [], []
1 hi hello what can i help you with today
2 can you book a table i'm on it
3 <SILENCE> any preference on a type of cuisine
4 i love italian food where should it be
5 in paris how many people would be in your party
6 we will be two which price range are looking for
7 in a cheap price range please ok let me look into some options for you
8 <SILENCE> api_call italian paris two cheap
1 hello hello what can i help you with today
2 can you book a table i'm on it
3 <SILENCE> any preference on a type of cuisine
4 i love italian food where should it be
5 in london how many people would be in your party
6 we will be eight which price range are looking for
7 i am looking for a cheap restaurant ok let me look into some options for you
8 <SILENCE> api_call italian london eight cheap
...
...
处理一个单句:
def generate_memory(sent, speaker, time):
sent_new = []
sent_token = sent.split(' ')
if speaker=="$u" or speaker=="$s":
for idx, word in enumerate(sent_token):
temp = [word, speaker, 'turn'+str(time), 'word'+str(idx)] + ["PAD"]*(MEM_TOKEN_SIZE-4)
sent_new.append(temp)
else:
if sent_token[1]=="R_rating":
sent_token = sent_token + ["PAD"]*(MEM_TOKEN_SIZE-len(sent_token))
else:
sent_token = sent_token[::-1] + ["PAD"]*(MEM_TOKEN_SIZE-len(sent_token))
sent_new.append(sent_token)
return sent_new
看个例子就明白了


for line in fin:
line = line.strip()
if line:
nid, line = line.split(' ', 1)
# print("line", line)
if '\t' in line:
u, r = line.split('\t')
gen_u = generate_memory(u, "$u", str(nid))
context_arr += gen_u
conv_arr += gen_u
ptr_index, ent_words = [], []
# Get local pointer position for each word in system response
for key in r.split():
if key in global_entity and key not in ent_words:
ent_words.append(key) / 将存在于全局实体列表中的单词加入ent_words
/ 若系统回复中的单词在用户问句中出现,获取其index,否则为空
index = [loc for loc, val in enumerate(context_arr) if (val[0] == key and key in global_entity)]
/ 如果存在这样的index则取序号最大值,否则取长度(超出索引,即没有)
index = max(index) if (index) else len(context_arr)
ptr_index.append(index) / 添加为局部指针
如这一条,user句仅一个“hi”,系统回复中没有出现问句中的单词,即所有的单词指针指向1(问句词数)

# Get global pointer labels for words in system response, the 1 in the end is for the NULL token
selector_index = [1 if (word_arr[0] in ent_words or word_arr[0] in r.split()) else 0 for word_arr in context_arr] + [1]
如果(用户)问句中的单词包含于ent_words答句(系统回复)中的知识实体词表,则selector_index对应位置未1,否则为0。最后多加一个[1]则是为了处理没有内容的情况。
sketch_response = generate_template(global_entity, r, type_dict)
这里是十分有趣的一个处理,简单讲就是把系统回复中存在于global_entity的单词替换为 的形式,即之后做槽位填充的预处理。
def generate_template(global_entity, sentence, type_dict):
sketch_response = []
for word in sentence.split():
if word in global_entity:
ent_type = None
for kb_item in type_dict.keys():
if word in type_dict[kb_item]:
ent_type = kb_item
break
sketch_response.append('@'+ent_type)
else:
sketch_response.append(word)
sketch_response = " ".join(sketch_response)
return sketch_response

data_detail = {
'context_arr':list(context_arr+[['$$$$']*MEM_TOKEN_SIZE]), # $$$$ is NULL token / 和 conv_arr差别目前仅在末尾是否存在 $$$$
'response':r, / 系统回复 str形式
'sketch_response':sketch_response, / 系统回复槽位处理结果 str形式
'ptr_index':ptr_index+[len(context_arr)], / 指针索引
'selector_index':selector_index, / 选择是否从问句中选择实体
'ent_index':ent_words, / 回复中出现的实体词
'ent_idx_cal':[], / 暂未出现
'ent_idx_nav':[],
'ent_idx_wet':[],
'conv_arr':list(conv_arr), / 处理后的对话list
'kb_arr':list(kb_arr),
'id':int(sample_counter), / 轮数
'ID':int(cnt_lin), / 第几段信息,两段中间用空行隔开
'domain':""}
data.append(data_detail)

由于第一条数据User问句仅一个单词,不具代表性,再来看下第二次到达此处的情况,此时包含的是【问1,答1,问2】处理后的数据。

最后再看一眼处理完第一段对话之后得到的data_detail

gen_r = generate_memory(r, "$s", str(nid)) / 同样处理对系统回复语句
context_arr += gen_r
conv_arr += gen_r
if max_resp_len < len(r.split()): / 获取回复最大长度
max_resp_len = len(r.split())
sample_counter += 1
else: / 对应其他模式的数据输入格式的情况
r = line
kb_info = generate_memory(r, "", str(nid))
context_arr = kb_info + context_arr
kb_arr += kb_info
else: / line 为空格的情况
cnt_lin += 1 / 下一段多轮对话
context_arr, conv_arr, kb_arr = [], [], [] / 清空
if(max_line and cnt_lin>=max_line): /是否限制输入数据量
break
return data, max_resp_len / 最后返回所有处理后的数据及最大回复长度
对四份数据集做同样处理,获取最大回复长度,此次调试中为10
pair_train, train_max_len = read_langs(file_train, global_ent, type_dict)
pair_dev, dev_max_len = read_langs(file_dev, global_ent, type_dict)
pair_test, test_max_len = read_langs(file_test, global_ent, type_dict)
pair_testoov, testoov_max_len = read_langs(file_test_OOV, global_ent, type_dict)
max_resp_len = max(train_max_len, dev_max_len, test_max_len, testoov_max_len) + 1
lang = Lang()
自定义词表对象,很基础,不多做解释。
class Lang:
def __init__(self):
self.word2index = {}
self.index2word = {PAD_token: "PAD", SOS_token: "SOS", EOS_token: "EOS", UNK_token: 'UNK'}
self.n_words = len(self.index2word) # Count default tokens
self.word2index = dict([(v, k) for k, v in self.index2word.items()])
def index_words(self, story, trg=False):
if trg:
for word in story.split(' '):
self.index_word(word)
else:
for word_triple in story:
for word in word_triple:
self.index_word(word)
def index_word(self, word):
if word not in self.word2index:
self.word2index[word] = self.n_words
self.index2word[self.n_words] = word
self.n_words += 1
其中:
PAD_token = 1
SOS_token = 3
EOS_token = 2
UNK_token = 0
train = get_seq(pair_train, lang, batch_size, True)
dev = get_seq(pair_dev, lang, 100, False)
test = get_seq(pair_test, lang, batch_size, False)
testoov = get_seq(pair_testoov, lang, batch_size, False)
def get_seq(pairs, lang, batch_size, type):
data_info = {}
for k in pairs[0].keys():
data_info[k] = []
for pair in pairs:
for k in pair.keys():
data_info[k].append(pair[k])
if(type): / 从训练集生成词表
lang.index_words(pair['context_arr'])
lang.index_words(pair['response'], trg=True)
lang.index_words(pair['sketch_response'], trg=True)
dataset = Dataset(data_info, lang.word2index, lang.word2index) / 自定义的数据加载类
data_loader = torch.utils.data.DataLoader(dataset = dataset,
batch_size = batch_size,
shuffle = type,
collate_fn = dataset.collate_fn) / 自定义处理方式
return data_loader
def index_words(self, story, trg=False):
if trg: / 适应两种输入格式,生成词表
for word in story.split(' '):
self.index_word(word)
else:
for word_triple in story:
for word in word_triple:
self.index_word(word)
def index_word(self, word): / 加入词表
if word not in self.word2index:
self.word2index[word] = self.n_words
self.index2word[self.n_words] = word
self.n_words += 1
class Dataset(data.Dataset):
"""Custom data.Dataset compatible with data.DataLoader."""
def __init__(self, data_info, src_word2id, trg_word2id):
"""Reads source and target sequences from txt files."""
self.data_info = {}
for k in data_info.keys():
self.data_info[k] = data_info[k]
self.num_total_seqs = len(data_info['context_arr'])
self.src_word2id = src_word2id
self.trg_word2id = trg_word2id
def collate_fn(self, data):
def merge(sequences,story_dim): / 是把tensor list合并为tensor
lengths = [len(seq) for seq in sequences]
max_len = 1 if max(lengths)==0 else max(lengths)
if (story_dim):
padded_seqs = torch.ones(len(sequences), max_len, MEM_TOKEN_SIZE).long()
for i, seq in enumerate(sequences):
end = lengths[i]
if len(seq) != 0:
padded_seqs[i,:end,:] = seq[:end]
else:
padded_seqs = torch.ones(len(sequences), max_len).long()
for i, seq in enumerate(sequences):
end = lengths[i]
padded_seqs[i, :end] = seq[:end]
return padded_seqs, lengths
def merge_index(sequences):
lengths = [len(seq) for seq in sequences]
padded_seqs = torch.zeros(len(sequences), max(lengths)).float()
for i, seq in enumerate(sequences):
end = lengths[i]
padded_seqs[i, :end] = seq[:end]
return padded_seqs, lengths
# sort a list by sequence length (descending order) to use pack_padded_sequence
data.sort(key=lambda x: len(x['conv_arr']), reverse=True)
item_info = {}
for key in data[0].keys():
item_info[key] = [d[key] for d in data]
# merge sequences
context_arr, context_arr_lengths = merge(item_info['context_arr'], True)
response, response_lengths = merge(item_info['response'], False)
selector_index, _ = merge_index(item_info['selector_index'])
ptr_index, _ = merge(item_info['ptr_index'], False)
conv_arr, conv_arr_lengths = merge(item_info['conv_arr'], True)
sketch_response, _ = merge(item_info['sketch_response'], False)
kb_arr, kb_arr_lengths = merge(item_info['kb_arr'], True)
# convert to contiguous and cuda
context_arr = _cuda(context_arr.contiguous())
response = _cuda(response.contiguous())
selector_index = _cuda(selector_index.contiguous())
ptr_index = _cuda(ptr_index.contiguous())
conv_arr = _cuda(conv_arr.transpose(0,1).contiguous()) / 注意这里的维度转换
sketch_response = _cuda(sketch_response.contiguous())
if(len(list(kb_arr.size()))>1): kb_arr = _cuda(kb_arr.transpose(0,1).contiguous())
# processed information
data_info = {}
for k in item_info.keys():
try:
data_info[k] = locals()[k]
except:
data_info[k] = item_info[k]
# additional plain information
data_info['context_arr_lengths'] = context_arr_lengths
data_info['response_lengths'] = response_lengths
data_info['conv_arr_lengths'] = conv_arr_lengths
data_info['kb_arr_lengths'] = kb_arr_lengths
return data_info
return train, dev, test, testoov, lang, max_resp_len
model = globals()[args['decoder']](
int(args['hidden']),
lang,
max_resp_len,
args['path'],
args['task'],
lr=float(args['learn']),
n_layers=int(args['layer']),
dropout=float(args['drop']))
class GLMP(nn.Module):
def __init__(self, hidden_size, lang, max_resp_len, path, task, lr, n_layers, dropout):
super(GLMP, self).__init__()
self.name = "GLMP"
self.task = task
self.input_size = lang.n_words
self.output_size = lang.n_words
self.hidden_size = hidden_size
self.lang = lang
self.lr = lr
self.n_layers = n_layers
self.dropout = dropout
self.max_resp_len = max_resp_len
self.decoder_hop = n_layers
self.softmax = nn.Softmax(dim=0)
if path:
if USE_CUDA:
print("MODEL {} LOADED".format(str(path)))
self.encoder = torch.load(str(path)+'/enc.th')
self.extKnow = torch.load(str(path)+'/enc_kb.th')
self.decoder = torch.load(str(path)+'/dec.th')
else:
print("MODEL {} LOADED".format(str(path)))
self.encoder = torch.load(str(path)+'/enc.th',lambda storage, loc: storage)
self.extKnow = torch.load(str(path)+'/enc_kb.th',lambda storage, loc: storage)
self.decoder = torch.load(str(path)+'/dec.th',lambda storage, loc: storage)
else:
self.encoder = ContextRNN(lang.n_words, hidden_size, dropout)
self.extKnow = ExternalKnowledge(lang.n_words, hidden_size, n_layers, dropout)
self.decoder = LocalMemoryDecoder(self.encoder.embedding, lang, hidden_size, self.decoder_hop, dropout) #Generator(lang, hidden_size, dropout)
# Initialize optimizers and criterion
self.encoder_optimizer = optim.Adam(self.encoder.parameters(), lr=lr)
self.extKnow_optimizer = optim.Adam(self.extKnow.parameters(), lr=lr)
self.decoder_optimizer = optim.Adam(self.decoder.parameters(), lr=lr)
self.scheduler = lr_scheduler.ReduceLROnPlateau(self.decoder_optimizer, mode='max', factor=0.5, patience=1, min_lr=0.0001, verbose=True)
self.criterion_bce = nn.BCELoss()
self.reset()
if USE_CUDA:
self.encoder.cuda()
self.extKnow.cuda()
self.decoder.cuda()
def reset(self):
self.loss, self.print_every, self.loss_g, self.loss_v, self.loss_l = 0, 1, 0, 0, 0
class ContextRNN(nn.Module):
def __init__(self, input_size, hidden_size, dropout, n_layers=1):
super(ContextRNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.n_layers = n_layers
self.dropout = dropout
self.dropout_layer = nn.Dropout(dropout)
self.embedding = nn.Embedding(input_size, hidden_size, padding_idx=PAD_token)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=dropout, bidirectional=True)
self.W = nn.Linear(2*hidden_size, hidden_size)
class ExternalKnowledge(nn.Module):
def __init__(self, vocab, embedding_dim, hop, dropout):
super(ExternalKnowledge, self).__init__()
self.max_hops = hop
self.embedding_dim = embedding_dim
self.dropout = dropout
self.dropout_layer = nn.Dropout(dropout)
for hop in range(self.max_hops+1):
C = nn.Embedding(vocab, embedding_dim, padding_idx=PAD_token)
C.weight.data.normal_(0, 0.1)
self.add_module("C_{}".format(hop), C)
self.C = AttrProxy(self, "C_")
self.softmax = nn.Softmax(dim=1)
self.sigmoid = nn.Sigmoid()
self.conv_layer = nn.Conv1d(embedding_dim, embedding_dim, 5, padding=2)
class LocalMemoryDecoder(nn.Module):
def __init__(self, shared_emb, lang, embedding_dim, hop, dropout):
super(LocalMemoryDecoder, self).__init__()
self.num_vocab = lang.n_words
self.lang = lang
self.max_hops = hop
self.embedding_dim = embedding_dim
self.dropout = dropout
self.dropout_layer = nn.Dropout(dropout)
self.C = shared_emb
self.softmax = nn.Softmax(dim=1)
self.sketch_rnn = nn.GRU(embedding_dim, embedding_dim, dropout=dropout)
self.relu = nn.ReLU()
self.projector = nn.Linear(2*embedding_dim, embedding_dim)
self.conv_layer = nn.Conv1d(embedding_dim, embedding_dim, 5, padding=2)
self.softmax = nn.Softmax(dim = 1)
for epoch in range(200):
print("Epoch:{}".format(epoch))
# Run the train function
pbar = tqdm(enumerate(train),total=len(train))
for i, data in pbar:
model.train_batch(data, int(args['clip']), reset=(i==0)) / <--
pbar.set_description(model.print_loss())
# break
...
...
def train_batch(self, data, clip, reset=0):
if reset: self.reset()
# Zero gradients of both optimizers
self.encoder_optimizer.zero_grad()
self.extKnow_optimizer.zero_grad()
self.decoder_optimizer.zero_grad()
# Encode and Decode
/ Teacher forcing:以一定概率使用真正的目标输出作为下一个输入,而不是使用解码器的猜测作为下一个输入。可以加快收敛,但训练好的网络可能会表现出不稳定性。
use_teacher_forcing = random.random() < args['teacher_forcing_ratio']
max_target_length = max(data['response_lengths'])
all_decoder_outputs_vocab, all_decoder_outputs_ptr, _, _, global_pointer = self.encode_and_decode(data, max_target_length, use_teacher_forcing, False)
根据dropout设置mask
def encode_and_decode(self, data, max_target_length, use_teacher_forcing, get_decoded_words):
# Build unknown mask for memory
if args['unk_mask'] and self.decoder.training:
story_size = data['context_arr'].size()
rand_mask = np.ones(story_size)
bi_mask = np.random.binomial([np.ones((story_size[0],story_size[1]))], 1-self.dropout)[0]
rand_mask[:,:,0] = rand_mask[:,:,0] * bi_mask
conv_rand_mask = np.ones(data['conv_arr'].size())
for bi in range(story_size[0]):
start, end = data['kb_arr_lengths'][bi], data['kb_arr_lengths'][bi] + data['conv_arr_lengths'][bi]
/ 维度不一样所以循环赋值
conv_rand_mask[:end-start,bi,:] = rand_mask[bi,start:end,:]
rand_mask = self._cuda(rand_mask)
conv_rand_mask = self._cuda(conv_rand_mask)
conv_story = data['conv_arr'] * conv_rand_mask.long()
story = data['context_arr'] * rand_mask.long()
else:
story, conv_story = data['context_arr'], data['conv_arr']
# Encode dialog history and KB to vectors
dh_outputs, dh_hidden = self.encoder(conv_story, data['conv_arr_lengths'])
global_pointer, kb_readout = self.extKnow.load_memory(story, data['kb_arr_lengths'], data['conv_arr_lengths'], dh_hidden, dh_outputs)
encoded_hidden = torch.cat((dh_hidden.squeeze(0), kb_readout), dim=1)
将历史对话处理出来的四元组(0,1维经转置)取Embedding相加后通过Bi-GRU编码。
输入:
- conv_story:历史对话序列
输出:
- dh_outputs:历史对话信息的编码结果
- dh_hidden:编码历史对话信息后的隐藏状态
def forward(self, input_seqs, input_lengths, hidden=None):
# Note: we run this all at once (over multiple batches of multiple sequences)
/ (max_len, batch_size, memory_size) -> (max_len, batch_size * memory_size, embedding_size)
embedded = self.embedding(input_seqs.contiguous().view(input_seqs.size(0), -1).long())
/ (max_len, batch_size * memory_size, embedding_size) -> (max_len, batch_size, memory_size, embedding_size)
embedded = embedded.view(input_seqs.size()+(embedded.size(-1),))
/ 对数据处理后得到的四元组的Embedding相加
embedded = torch.sum(embedded, 2).squeeze(2)
embedded = self.dropout_layer(embedded)
/ 初始化 hidden, 全0
hidden = self.get_state(input_seqs.size(1))
if input_lengths: / 打包,RNN基本操作,这里不详解
embedded = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths, batch_first=False)
outputs, hidden = self.gru(embedded, hidden)
if input_lengths: / 解包
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs, batch_first=False)
/ 双向的hidden state,拼接后线性映射
hidden = self.W(torch.cat((hidden[0], hidden[1]), dim=1)).unsqueeze(0)
outputs = self.W(outputs)
return outputs.transpose(0,1), hidden
def get_state(self, bsz):
"""Get cell states and hidden states."""
return _cuda(torch.zeros(2, bsz, self.hidden_size))
- 将历史对话处理出来的四元组取hop k 的Embedding相加得到embed_A
- embed_A即 与查询向量 点乘后对每个词的当前嵌入求和得到prob_logit
- 对prob_logit 求Softmax得到查询向量和记忆信息的相关度prob_
- 将历史对话处理出来的四元组取hop k+1 的Embedding相加得到embed_C
- embed_C 与查询向量和记忆信息的相关度 prob_ 点乘后加权求和得到记忆信息o_k
- 查询向量 与记忆信息o_k 相加得到下一跳的查询向量
- 查询向量 和记忆信息 点乘取sigmoid的指针值作为global_pointer
- 最后一跳的查询向量作为kb_readout
输入:
- story:历史对话序列 加的1是"$$$$"
输出:
- global_pointer:查询向量 和记忆信息 点乘取sigmoid的指针值,来表示记忆中的目标实体单词是否存在于预期的系统回复 Y 中
- kb_readout:经过多跳最后的查询向量
(1)
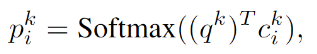
(2)
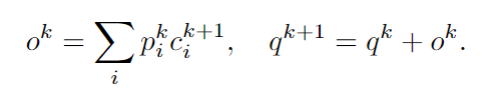
(3)
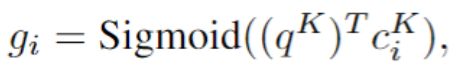
def load_memory(self, story, kb_len, conv_len, hidden, dh_outputs):
# Forward multiple hop mechanism
u = [hidden.squeeze(0)] / 即文中的q,即输入的隐藏状态作为查询向量
story_size = story.size()
self.m_story = []
for hop in range(self.max_hops):
embed_A = self.C[hop](story.contiguous().view(story_size[0], -1))#.long()) # b * (m * s) * e
embed_A = embed_A.view(story_size+(embed_A.size(-1),)) # b * m * s * e
embed_A = torch.sum(embed_A, 2).squeeze(2) # b * m * e
if not args["ablationH"]:
embed_A = self.add_lm_embedding(embed_A, kb_len, conv_len, dh_outputs) / story的embedding和hidden相加
embed_A = self.dropout_layer(embed_A)
if(len(list(u[-1].size()))==1):
u[-1] = u[-1].unsqueeze(0) ## used for bsz = 1.
u_temp = u[-1].unsqueeze(1).expand_as(embed_A)
/ embed_A 与对应的查询向量点乘后对每个词的当前嵌入求和,对应公式(1)
prob_logit = torch.sum(embed_A*u_temp, 2)
/ 求取的是查询向量和记忆信息的相关度
prob_ = self.softmax(prob_logit)
embed_C = self.C[hop+1](story.contiguous().view(story_size[0], -1).long())
embed_C = embed_C.view(story_size+(embed_C.size(-1),))
embed_C = torch.sum(embed_C, 2).squeeze(2)
if not args["ablationH"]:
embed_C = self.add_lm_embedding(embed_C, kb_len, conv_len, dh_outputs)
/ 对应公式(2),加权求出记忆o_k
prob = prob_.unsqueeze(2).expand_as(embed_C)
o_k = torch.sum(embed_C*prob, 1)
u_k = u[-1] + o_k / u_k对应下一跳的查询向量
u.append(u_k) / 加入查询向量列表
self.m_story.append(embed_A)
self.m_story.append(embed_C) / 只加入最后一跳的记忆信息
/ 注意这里返回的是查询向量q^k和记忆信息c^k点乘取sigmoid的指针值和最后的查询向量,对应公式(3)
return self.sigmoid(prob_logit), u[-1]
用隐藏状态来更新全局记忆信息
输入:
- full_memory:对话记忆模块
- dh_outputs: Context RNN 对历史对话信息的编码结果
输出:
- full_memory:更新后的对话记忆模块
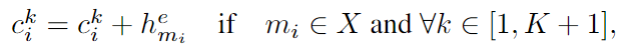
def add_lm_embedding(self, full_memory, kb_len, conv_len, hiddens):
for bi in range(full_memory.size(0)):
start, end = kb_len[bi], kb_len[bi]+conv_len[bi]
full_memory[bi, start:end, :] = full_memory[bi, start:end, :] + hiddens[bi, :conv_len[bi], :]
return full_memory
将 Context RNN 对历史对话信息的编码结果和经过多跳求取的查询向量链接。
# Encode dialog history and KB to vectors
dh_outputs, dh_hidden = self.encoder(conv_story, data['conv_arr_lengths'])
global_pointer, kb_readout = self.extKnow.load_memory(story, data['kb_arr_lengths'], data['conv_arr_lengths'], dh_hidden, dh_outputs) / -->
encoded_hidden = torch.cat((dh_hidden.squeeze(0), kb_readout), dim=1)
将历史对话中的所有单词加入self.copy_list
# Get the words that can be copy from the memory
batch_size = len(data['context_arr_lengths'])
self.copy_list = []
for elm in data['context_arr_plain']:
elm_temp = [ word_arr[0] for word_arr in elm ]
self.copy_list.append(elm_temp)
输入:
- self.copy_list:历史对话中的所有单词
- encoded_hidden:Encode流程最终的编码结果
- data[‘sketch_response’]:草图回复序列
- global_pointer:表示记忆中的目标实体单词是否存在于预期的系统回复 Y 中的0/1指针
输出:
- outputs_vocab:生成结果的词表概率分布
- outputs_ptr:查询向量对记忆信息的软注意
- decoded_fine:暂时为空,验证时使用,见下文。保存经过copy后生成的token。
- decoded_coarse:暂时为空,验证时使用,见下文。保存未使用copy机制时生成的token。
def forward(self, extKnow, story_size, story_lengths, copy_list, encode_hidden, target_batches, max_target_length, batch_size, use_teacher_forcing, get_decoded_words, global_pointer):
# Initialize variables for vocab and pointer
/ (max_target_length, batch_size, self.num_vocab)
all_decoder_outputs_vocab = _cuda(torch.zeros(max_target_length, batch_size, self.num_vocab))
/ (max_target_length, batch_size, max_input_len)
all_decoder_outputs_ptr = _cuda(torch.zeros(max_target_length, batch_size, story_size[1]))
/ 初始输入为batch_size个SOS
decoder_input = _cuda(torch.LongTensor([SOS_token] * batch_size))
/ (batch_size, max_input_len)
memory_mask_for_step = _cuda(torch.ones(story_size[0], story_size[1]))
decoded_fine, decoded_coarse = [], []
hidden = self.relu(self.projector(encode_hidden)).unsqueeze(0)
...
...
其中:
self.projector = nn.Linear(2*embedding_dim, embedding_dim)
def forward(self, extKnow, story_size, story_lengths, copy_list, encode_hidden, target_batches, max_target_length, batch_size, use_teacher_forcing, get_decoded_words, global_pointer):
...
...
# Start to generate word-by-word
for t in range(max_target_length):
embed_q = self.dropout_layer(self.C(decoder_input)) # b * e
if len(embed_q.size()) == 1: embed_q = embed_q.unsqueeze(0)
_, hidden = self.sketch_rnn(embed_q.unsqueeze(0), hidden)
query_vector = hidden[0]
p_vocab = self.attend_vocab(self.C.weight, hidden.squeeze(0))
all_decoder_outputs_vocab[t] = p_vocab
_, topvi = p_vocab.data.topk(1)
# query the external konwledge using the hidden state of sketch RNN
prob_soft, prob_logits = extKnow(query_vector, global_pointer)
all_decoder_outputs_ptr[t] = prob_logits
if use_teacher_forcing:
decoder_input = target_batches[:,t]
else:
decoder_input = topvi.squeeze()
if get_decoded_words:
search_len = min(5, min(story_lengths))
prob_soft = prob_soft * memory_mask_for_step
_, toppi = prob_soft.data.topk(search_len)
temp_f, temp_c = [], []
for bi in range(batch_size):
token = topvi[bi].item() #topvi[:,0][bi].item()
temp_c.append(self.lang.index2word[token])
if '@' in self.lang.index2word[token]:
cw = 'UNK'
for i in range(search_len):
if toppi[:,i][bi] < story_lengths[bi]-1:
cw = copy_list[bi][toppi[:,i][bi].item()]
break
temp_f.append(cw)
if args['record']:
memory_mask_for_step[bi, toppi[:,i][bi].item()] = 0
else:
temp_f.append(self.lang.index2word[token])
decoded_fine.append(temp_f)
decoded_coarse.append(temp_c)
return all_decoder_outputs_vocab, all_decoder_outputs_ptr, decoded_fine, decoded_coarse
其中
self.sketch_rnn = nn.GRU(embedding_dim, embedding_dim, dropout=dropout)
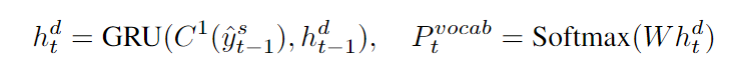
p_vocab = self.attend_vocab(self.C.weight, hidden.squeeze(0))
self.C = shared_emb / = GLMP.encoder.embedding
def attend_vocab(self, seq, cond):
/ (batch_size, hidden_size) matmul (hidden_size, vocab_size)
scores_ = cond.matmul(seq.transpose(1,0))
# scores = F.softmax(scores_, dim=1)
return scores_
def forward(self, extKnow, story_size, story_lengths, copy_list, encode_hidden, target_batches, max_target_length, batch_size, use_teacher_forcing, get_decoded_words, global_pointer):
...
...
p_vocab = self.attend_vocab(self.C.weight, hidden.squeeze(0))
all_decoder_outputs_vocab[t] = p_vocab 将该位置生成对应词表中每个单词的概率保存起来
_, topvi = p_vocab.data.topk(1) / values, indices 取最大概率对应下标(即目标单词)
...
...
# query the external konwledge using the hidden state of sketch RNN
prob_soft, prob_logits = extKnow(query_vector, global_pointer)
all_decoder_outputs_ptr[t] = prob_logits
输入:
- query_vector:经过sketchRNN得到的隐藏状态
- global_pointer:表示记忆中的目标实体单词是否存在于预期的系统回复 Y 中的0/1指针
- data[‘sketch_response’]:草图回复序列
输出:
- prob_soft:查询向量的记忆相关度的软记忆注意
- prob_logits:prob_soft未经Softmax的logits
(1)
(2)
def forward(self, query_vector, global_pointer):
u = [query_vector]
for hop in range(self.max_hops):
m_A = self.m_story[hop] / load_memory时保存的EmbeddingA
if not args["ablationG"]:
/ 记忆信息 * 全局记忆指针 根据权重对记忆信息进行处理(即指针指向的位置权重几乎不变,未指向的位置信息大幅度衰减)
m_A = m_A * global_pointer.unsqueeze(2).expand_as(m_A)
if(len(list(u[-1].size()))==1):
u[-1] = u[-1].unsqueeze(0) ## used for bsz = 1.
u_temp = u[-1].unsqueeze(1).expand_as(m_A)
/ 记忆信息 * 查询向量 对应公式(1)
prob_logits = torch.sum(m_A*u_temp, 2)
prob_soft = self.softmax(prob_logits)
m_C = self.m_story[hop+1] / load_memory时保存的EmbeddingC
if not args["ablationG"]:
m_C = m_C * global_pointer.unsqueeze(2).expand_as(m_C)
prob = prob_soft.unsqueeze(2).expand_as(m_C)
/ 对应公式(2),加权求出记忆o_k
o_k = torch.sum(m_C*prob, 1)
u_k = u[-1] + o_k
u.append(u_k)
/ 最后返回的是决定查询向量的记忆相关度的软记忆注意和未经Softmax的logits
return prob_soft, prob_logits
prob_soft, prob_logits = extKnow(query_vector, global_pointer) / -->
all_decoder_outputs_ptr[t] = prob_logits / 保存软注意的logits
if use_teacher_forcing: / 是否采用真实标签作为下一个step的输入
decoder_input = target_batches[:,t]
else:
decoder_input = topvi.squeeze()
if get_decoded_words: / 此时为false
...
...
见 输出总结
return all_decoder_outputs_vocab, all_decoder_outputs_ptr, decoded_fine, decoded_coarse
在其上输出增加global_pointer
return outputs_vocab, outputs_ptr, decoded_fine, decoded_coarse, global_pointer
损失定义和计算
# Loss calculation and backpropagation
loss_g = self.criterion_bce(global_pointer, data['selector_index'])
loss_v = masked_cross_entropy(
all_decoder_outputs_vocab.transpose(0, 1).contiguous(),
data['sketch_response'].contiguous(),
data['response_lengths'])
loss_l = masked_cross_entropy(
all_decoder_outputs_ptr.transpose(0, 1).contiguous(),
data['ptr_index'].contiguous(),
data['response_lengths'])
loss = loss_g + loss_v + loss_l
loss.backward()
loss_g: 通过检查记忆中的目标实体单词是否存在于预期的系统回复
中,来定义标签
之后全局记忆指针通过
和
的二分类交叉熵来训练。

loss_v: 使用标准的交叉熵损失来训练Sketch RNN
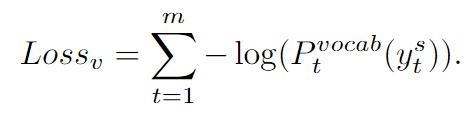
loss_l:Sketch RNN隐藏状态
对外部知识进行查询。最后一跳中的记忆注意对应于本地记忆指针
,表示为时间步
的记忆分布。为了训练本地记忆指针,在最后一跳记忆注意的外部知识上增加一个监督。我们首先定义解码时间步的本地记忆指针
的位置标签,位置
是记忆中的一个空标记,它允许我们在即使外部知识中不存在该函数时也可以计算损失函数。
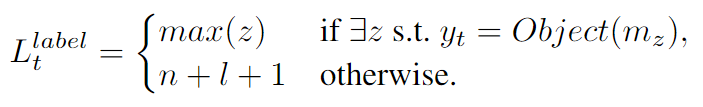
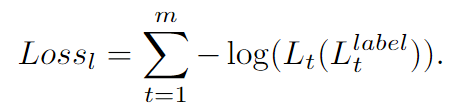
Loss 三种Loss加权相加,此处均设为1。
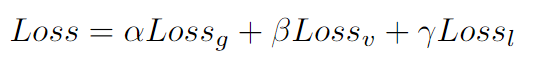
masked_cross_entropy计算
def masked_cross_entropy(logits, target, length):
"""
Args:
logits: A Variable containing a FloatTensor of size
(batch, max_len, num_classes) which contains the
unnormalized probability for each class.
target: A Variable containing a LongTensor of size
(batch, max_len) which contains the index of the true
class for each corresponding step.
length: A Variable containing a LongTensor of size (batch,)
which contains the length of each data in a batch.
Returns:
loss: An average loss value masked by the length.
"""
if USE_CUDA:
length = Variable(torch.LongTensor(length)).cuda()
else:
length = Variable(torch.LongTensor(length))
# logits_flat: (batch * max_len, num_classes)
logits_flat = logits.view(-1, logits.size(-1)) ## -1 means infered from other dimentions
# log_probs_flat: (batch * max_len, num_classes)
log_probs_flat = functional.log_softmax(logits_flat, dim=1)
# target_flat: (batch * max_len, 1)
target_flat = target.view(-1, 1)
# losses_flat: (batch * max_len, 1)
losses_flat = -torch.gather(log_probs_flat, dim=1, index=target_flat)
# losses: (batch, max_len)
losses = losses_flat.view(*target.size())
# mask: (batch, max_len)
mask = sequence_mask(sequence_length=length, max_len=target.size(1))
losses = losses * mask.float()
loss = losses.sum() / length.float().sum()
return loss
def sequence_mask(sequence_length, max_len=None):
if max_len is None:
max_len = sequence_length.data.max()
batch_size = sequence_length.size(0)
seq_range = torch.arange(0, max_len).long()
seq_range_expand = seq_range.unsqueeze(0).expand(batch_size, max_len)
seq_range_expand = Variable(seq_range_expand)
if sequence_length.is_cuda:
seq_range_expand = seq_range_expand.cuda()
seq_length_expand = (sequence_length.unsqueeze(1)
.expand_as(seq_range_expand))
return seq_range_expand < seq_length_expand
torch.gather
梯度裁剪
# Clip gradient norms
ec = torch.nn.utils.clip_grad_norm_(self.encoder.parameters(), clip)
ec = torch.nn.utils.clip_grad_norm_(self.extKnow.parameters(), clip)
dc = torch.nn.utils.clip_grad_norm_(self.decoder.parameters(), clip)
# Update parameters with optimizers
self.encoder_optimizer.step()
self.extKnow_optimizer.step()
self.decoder_optimizer.step()
self.loss += loss.item()
self.loss_g += loss_g.item()
self.loss_v += loss_v.item()
self.loss_l += loss_l.item()
for i, data in pbar:
model.train_batch(data, int(args['clip']), reset=(i==0))
pbar.set_description(model.print_loss()) / 设置tqdm描述为自定义打印loss
# break
if((epoch+1) % int(args['evalp']) == 0):
acc = model.evaluate(dev, avg_best, early_stop)
model.scheduler.step(acc)
def print_loss(self):
print_loss_avg = self.loss / self.print_every
print_loss_g = self.loss_g / self.print_every
print_loss_v = self.loss_v / self.print_every
print_loss_l = self.loss_l / self.print_every
self.print_every += 1
return 'L:{:.2f},LE:{:.2f},LG:{:.2f},LP:{:.2f}'.format(print_loss_avg, print_loss_g, print_loss_v, print_loss_l)
def evaluate(self, dev, matric_best, early_stop=None):
print("STARTING EVALUATION")
# Set to not-training mode to disable dropout
self.encoder.train(False)
self.extKnow.train(False)
self.decoder.train(False)
ref, hyp = [], []
acc, total = 0, 0
dialog_acc_dict = {}
F1_pred, F1_cal_pred, F1_nav_pred, F1_wet_pred = 0, 0, 0, 0
F1_count, F1_cal_count, F1_nav_count, F1_wet_count = 0, 0, 0, 0
pbar = tqdm(enumerate(dev),total=len(dev))
new_precision, new_recall, new_f1_score = 0, 0, 0
kvr数据集,暂不表。
if args['dataset'] == 'kvr':
with open('data/KVR/kvret_entities.json') as f:
global_entity = json.load(f)
global_entity_list = []
for key in global_entity.keys():
if key != 'poi':
global_entity_list += [item.lower().replace(' ', '_') for item in global_entity[key]]
else:
for item in global_entity['poi']:
global_entity_list += [item[k].lower().replace(' ', '_') for k in item.keys()]
global_entity_list = list(set(global_entity_list))
还是编解码,但这次get_decoded_words参数为True,我们来看看做了些什么。
for j, data_dev in pbar:
# Encode and Decode
_, _, decoded_fine, decoded_coarse, global_pointer = self.encode_and_decode(data_dev, self.max_resp_len, False, True)
decoded_coarse = np.transpose(decoded_coarse)
decoded_fine = np.transpose(decoded_fine)
...
...
if get_decoded_words:
search_len = min(5, min(story_lengths)) / 最大搜索长度为min(5,问句最小长度)
prob_soft = prob_soft * memory_mask_for_step
_, toppi = prob_soft.data.topk(search_len) / 选择软注意的top search_len 个token进行搜索
temp_f, temp_c = [], []
for bi in range(batch_size):
/ 生成的回复token
token = topvi[bi].item() #topvi[:,0][bi].item()
/ 转为单词并保存
temp_c.append(self.lang.index2word[token])
if '@' in self.lang.index2word[token]: / 如果有草图标记
cw = 'UNK'
for i in range(search_len):
/ 如果存在于问句中存在,则copy word
if toppi[:,i][bi] < story_lengths[bi]-1:
cw = copy_list[bi][toppi[:,i][bi].item()]
break
/ 保存copy word 到 temp_f
temp_f.append(cw)
/ 若设置该选项,则会将已copy的单词屏蔽,防止多次复制
if args['record']:
memory_mask_for_step[bi, toppi[:,i][bi].item()] = 0
else: / 若没有草图标记,也将其保存入temp_f
temp_f.append(self.lang.index2word[token])
decoded_fine.append(temp_f) / 使用copy机制后的输出
decoded_coarse.append(temp_c) / 未进行copy的输出
decoded_coarse = np.transpose(decoded_coarse) / 转为ndarray格式
decoded_fine = np.transpose(decoded_fine)
/ 生成结果用空格链接
for bi, row in enumerate(decoded_fine):
st = ''
for e in row:
if e == 'EOS': break
else: st += e + ' '
st_c = ''
for e in decoded_coarse[bi]:
if e == 'EOS': break
else: st_c += e + ' '
pred_sent = st.lstrip().rstrip() / 去除两边的空格
pred_sent_coarse = st_c.lstrip().rstrip()
gold_sent = data_dev['response_plain'][bi].lstrip().rstrip() / 正确答案
ref.append(gold_sent)
hyp.append(pred_sent)
if args['dataset'] == 'kvr':
...
...
else:
# compute Dialogue Accuracy Score
current_id = data_dev['ID'][bi]
if current_id not in dialog_acc_dict.keys():
dialog_acc_dict[current_id] = []
if gold_sent == pred_sent: / 句子完全相同
dialog_acc_dict[current_id].append(1)
else:
dialog_acc_dict[current_id].append(0)
# compute Per-response Accuracy Score
total += 1
if (gold_sent == pred_sent): / 句子完全相同
acc += 1
if args['genSample']: / 顾名思义
self.print_examples(bi, data_dev, pred_sent, pred_sent_coarse, gold_sent)
# Set back to training mode
self.encoder.train(True)
self.extKnow.train(True)
self.decoder.train(True)
后续的评估BLUE,ENTF1等细节过几天可能会更新后续吧。
主体过了一遍,但是只是踏出了第一步。
可能的后续:记忆网络和指针网络考古,最新任务型对话SOTA论文及代码,GLMP实验复现等。。。
当然也可能什么都没有,哈哈哈哈哈哈~