文章目录
树在数据结构中非常重要,应用也很广泛,比如文件系统的管理,有根目录,里面有文件等等,我们先看一下树的基本概念,方便后续学习;后面会有一些特殊树的介绍

①节点的度:一个节点含有的子树的个数称为该节点的度;像上面A的度为6,D的度为1;
②树的度:一棵树中,最大的节点的度称为树的度;A的节点度最大,所以这个二叉树的度为6;
③叶子节点或终端节点:度为0的节点称为叶节点,就是它下面没数树了; 上面B、C、H、I…等节点都是叶子节点
④双亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点; 如上图:A是B的父节点
⑤子节点:一个节点含有的子树的根节点称为该节点的子节点;B是A的孩子节点、Q是J的子节点
⑥根结点:一棵树中,没有双亲结点的结点;如上图:A
⑦节点的层次:从根开始定义起,根为第1层,根的子节点为第2层
⑧树的高度或深度:树中节点的最大层次; 如上图:树的高度为4
一、二叉树
1、概念和分类
概念:顾名思义就是只有两个分支的树;
一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。每个结点最多有两棵子树,即二叉树不存在度大于 2 的结点;二叉树的子树有左右之分,其子树的次序不能颠倒。

上面的五个图依次为1.空二叉树、2.只有根节点的二叉树、3.只有左子树的二叉树、4.只有右子树的二叉树、5.正常二叉树;
2、二叉树的性质
①:二叉树的第i层上至多有2^(i-1)(i≥1)个节点。
②:深度为h的二叉树中至多含有2^h-1个节点。
③:若在任意一棵二叉树中,有n个叶子节点,有n2个度为2的节点,则n0=n2+1
④:具有n个节点的完全二叉树深为log2x+1(其中x表示不大于n的最大整数)[6]。
⑤:若对一棵有n个节点的完全二叉树进行顺序编号(1≤i≤n),那么,对于编号为i(i≥1)的节点:
当i=1时,该节点为根,它无双亲节点。
当i>1时,该节点的双亲节点的编号为i/2。
若2i≤n,则有编号为2的左孩子,否则没有左孩子
若2+1≤n,则有编号为2i+1的右孩子,否则没有右孩子

3、特殊情况(完全二叉树和满二叉树)
-
完全二叉树: 对于深度为K的,有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点对应时称为完全二叉树;
-
满二叉树: 一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
4、二叉树的遍历
- NLR:前序遍历(根左右)——访问根结点的操作发生在遍历其左右子树之前。
- LNR:中序遍历(左根右)——访问根结点的操作发生在遍历其左右子树之中(间)。
- LRN:后序遍历(左右根)——访问根结点的操作发生在遍历其左右子树之后。

备注:相应代码会在另一篇博客里面更新,这篇主要进行概念方面介绍
二叉树前中后序遍历及常见手撕代码题
二、二叉搜索树和二叉平衡树
1、两种树的基本认识
概念:二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
①:若它的左子树不为空,则左子树上所有节点的值都小于根节点的值
②:若它的右子树不为空,则右子树上所有节点的值都大于根节点的值
③:它的左右子树也分别为二叉搜索树
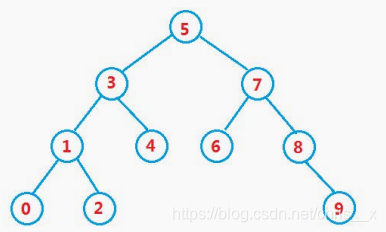
④:它的中序遍历一定是有序的:像下面这个中序遍历就是0123456789
二叉平衡树:任意节点的子树高度差都小于等于1,常见的二叉平衡树有B树,AVL树等;

2、二叉搜索树查找的性能分析
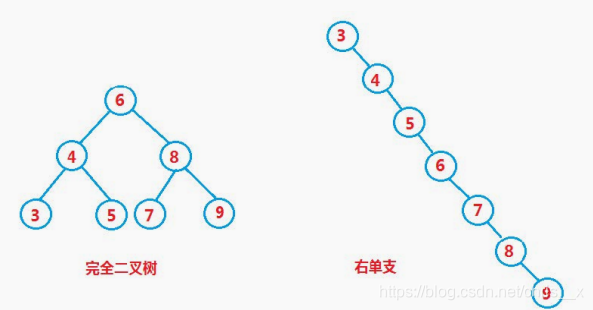
最优情况:二叉搜索树为完全二叉树,其平均比较次数为:
最差情况:二叉搜索树退化为单支树,其平均比较次数为n^2;
三、 AVL树和红黑树
出现原因:二叉搜索树虽可以缩短查找的效率,但如果数据有序或接近有序二叉搜索树将退化为单支树,查找元素相当于在顺序表中搜索元素,效率低下。
概念和性质:一棵AVL树或者是空树,或者是具有以下性质的二叉搜索树:
①它的左右子树都是AVL树
②左右子树高度之差(简称平衡因子)的绝对值不超过1(-1/0/1)

红黑树:红黑树,是一种二叉搜索树,但在每个结点上增加一个存储位表示结点的颜色,可以是Red或Black。 通过对任何
一条从根到叶子的路径上各个结点着色方式的限制,红黑树确保没有一条路径会比其他路径长出俩倍,因而是接近
平衡的。
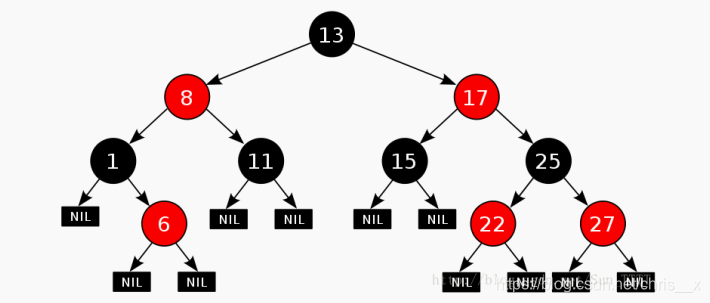
特征:
①每个结点不是红色的就是黑色的,但根节点必须为黑色
②如果一个节点是红色的,则它的相邻结点必须是是黑色的
③每个叶子节点都是黑色的
对于每个结点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点
从根节点到叶子节点的每条路径中,必须包含相同数目的黑色节点
红黑树也是一种二叉搜索树,但是他不是完全平衡的
其最长路径中节点个数不会超过最短路径中节点个数的两倍
AVL树和红黑树的比较
红黑树和AVL树都是高效的平衡二叉树,增删改查的时间复杂度都是O(
),红黑树不追求绝对平衡,其只需保证最长路径不超过最短路径的2倍,相对而言,降低了插入和旋转的次数,所以在经常进行增删的结构中性能比AVL树更优,而且红黑树实现比较简单,所以实际运用中红黑树更多。
红黑树的应用
’1. java集合框架中的:TreeMap、TreeSet底层使用的就是红黑树
2. C++ STL库 – map/set、mutil_map/mutil_set
3. linux内核:进程调度中使用红黑树管理进程控制块,epoll在内核中实现时使用红黑树管理事件块
4. 其他一些库:比如nginx中用红黑树管理timer等
四、B树和B+树
出现的原因:B树是为了提高磁盘或外部存储设备查找效率而产生的一种多路平衡搜索树;假如树的高度比较高时,查找最差情况下要比较树的高度次,数据量如果特别大时,树中的节点可能无法一次性加载到内存中,需要多次IO
B树: 是一种搜索树,树的目的都是解决查找效率低的问题。B树 也是如此,它最初启发于二叉搜索树,二叉搜索树的特点是:每个非叶节点都只有两个孩子节点。然而这种做法会导致当数据量非常大时,二叉查找树的深度过深,搜索算法自根节点向下搜索时,需要访问的节点也就变的相当多。如果这些节点存储在外存储器中,每访问一个节点,相当于就是进行了一次 I/O 操作(因为每一层的节点都在一个磁盘上),随着树高度的增加,频繁的 I/O 操作一定会降低查询的效率,所以 B树 就被搞出来降低树的高度,从而减少磁盘的访问。
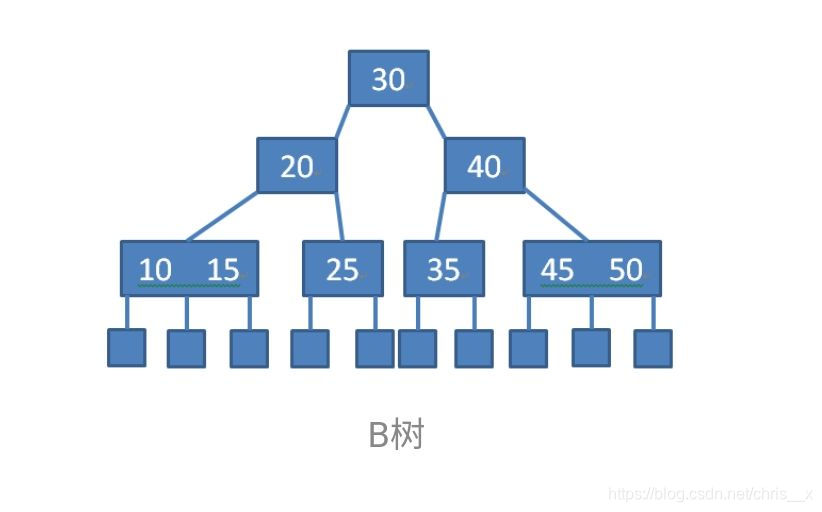
特征
一棵M阶(M>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树或者满足一下性质:
- 根节点至少有两个孩子
- 每个非根节点至少有M/2(上取整)个孩子,至多有M个孩子
- 每个非根节点至少有M/2-1(上取整)个关键字,至多有M-1个关键字,并且以升序排列
- key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
- 所有的叶子节点都在同一层
任意非叶子节点最多只有M个孩子
所有叶子节点位于同一层
特性:(后面和B+树作区分)
①关键字集合分布在整颗树中
②任何一个关键字出现且只出现在一个结点中
③搜索有可能在非叶子结点处就结束
④其搜索性能等价于在关键字全集内做一次二分查找
B+ 树通常用于数据库和操作系统的文件系统中做索引
①在所有非叶子节点中,含有 K 个关键字的节点有 k 颗子树,这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点中(而 B 树是每个关键字都用来保存数据的)
②所有的叶子节点包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子节点本身依关键字的大小自小而大顺序连接
③所有的非叶子节点可以看成索引
④通常在 B+ 树上有两个头指针,一个指向根节点,一个指向叶子节点。
同一个关键字会在不同节点中重复出现,根节点的最大关键字元素就是整个 B+ 树的最大元素。
B树和B+树的区别
1、B 树所有节点都带有指向记录(数据)的指针,在非叶子节点就可以查找到数据,并停止搜索。而 B+ 树只有叶子节点会带有指向记录(数据)的指针,也就是在叶子结点中才可以查找到数据,并停止搜索。因为 B+ 树它把所有的数据都存储在叶节点中,内部节点只存放关键字和孩子指针,不会带上指向记录(数据)的指针。
2、B+的磁盘读写代价更低:因为B+树中间节点没有数据,所以同样大小的磁盘空间可以容纳更多的节点元素;如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
3、B+ 的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相同。