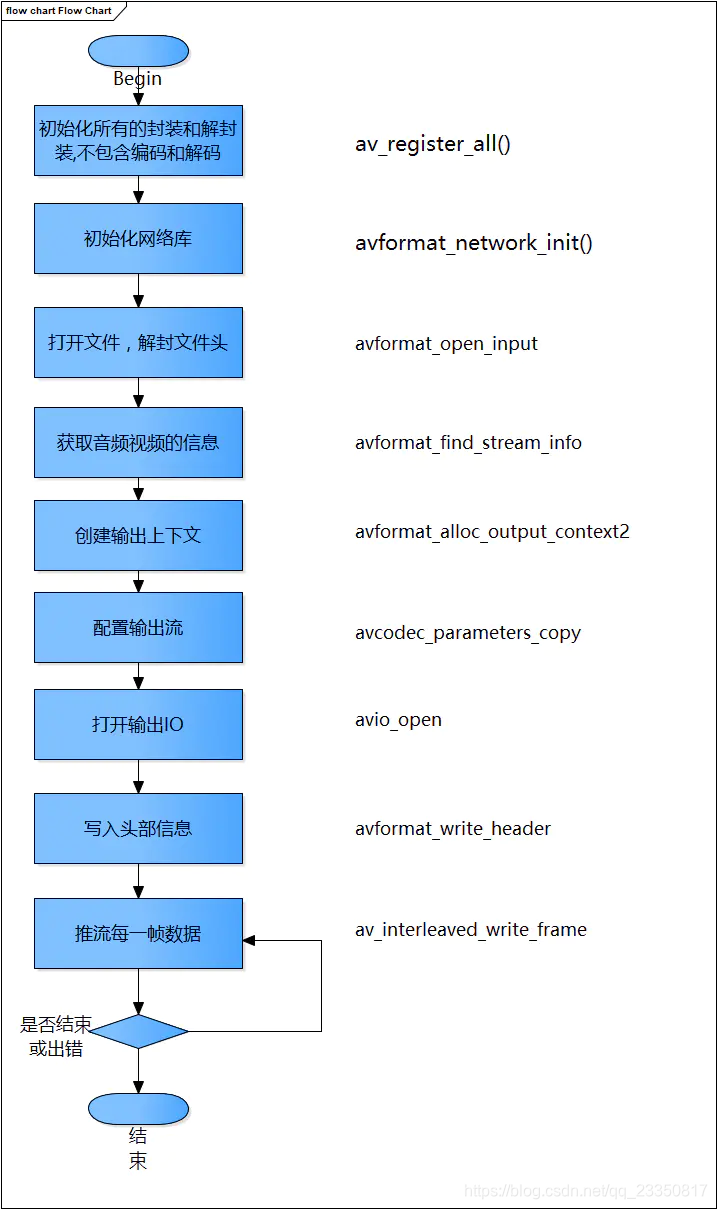
流程详解
av_register_all()
该方法初始化所有的封装和解封装。在使用FFmpeg的时候首先要调用这个方法。
static void register_all(void)
{
avcodec_register_all();
/* (de)muxers */
REGISTER_MUXER (A64, a64);
REGISTER_DEMUXER (AA, aa);
REGISTER_DEMUXER (AAC, aac);
//...
}
这里面就是进行各种注册,而REGISTER_MUXER 、REGISTER_DEMUXER 是前面定义的宏。我们看到是静态方法,说明该方法只能在所在的文件中使用,这也防止被注册多次。
avformat_network_init()
网络相关初始化。如果我们使用了网络拉流和推流等等,要先初始化。
avformat_open_input()
声明是
int avformat_open_input(AVFormatContext **ps, const char *url, AVInputFormat *fmt, AVDictionary **options);
定义在libavformat\utils.c中。主要功能
输入输出结构体AVIOContext的初始化;
输入数据的协议URLProtocol,通过函数指针的方式,与FFMPEG关联,剩下的就是调用该URLProtocol的函数进行open,read等操作了
avformat_find_stream_info
int avformat_find_stream_info(AVFormatContext *ic, AVDictionary **options);
可以读取视音频数据并且获得一些相关的信息。定义在libavformat\utils.c下
avformat_alloc_output_context2
int avformat_alloc_output_context2(AVFormatContext **ctx, AVOutputFormat *oformat,
const char *format_name, const char *filename);
定义在libavformat\mux.c中
ctx:函数调用成功之后创建的AVFormatContext结构体。
oformat:指定AVFormatContext中的AVOutputFormat,用于确定输出格式。如果指定为NULL,可以设定后两个参数(format_name或者filename)由FFmpeg猜测输出格式。
PS:使用该参数需要自己手动获取AVOutputFormat,相对于使用后两个参数来说要麻烦一些。
format_name:指定输出格式的名称。根据格式名称,FFmpeg会推测输出格式。输出格式可以是“flv”,“mkv”等等。
filename:指定输出文件的名称。根据文件名称,FFmpeg会推测输出格式。文件名称可以是“xx.flv”,“yy.mkv”等等。
函数执行成功的话,其返回值大于等于0。
内部流程
调用avformat_alloc_context()初始化一个默认的AVFormatContext。
如果指定了输入的AVOutputFormat,则直接将输入的AVOutputFormat赋值给AVOutputFormat的oformat。如果没有指定输入的AVOutputFormat,就需要根据文件格式名称或者文件名推测输出的AVOutputFormat。无论是通过文件格式名称还是文件名推测输出格式,都会调用一个函数av_guess_format()。
avio_open
打开FFmpeg的输入输出文件
int avio_open2(AVIOContext **s, const char *url, int flags,
const AVIOInterruptCB *int_cb, AVDictionary **options);
s:函数调用成功之后创建的AVIOContext结构体。
url:输入输出协议的地址(文件也是一种“广义”的协议,对于文件来说就是文件的路径)。
flags:打开地址的方式。可以选择只读,只写,或者读写。取值如下。
AVIO_FLAG_READ:只读。
AVIO_FLAG_WRITE:只写。
AVIO_FLAG_READ_WRITE:读写。
int_cb:不太清楚
options:不太清楚
avformat_write_header
写视频文件头,av_write_trailer()用于写视频文件尾
av_read_frame
定义在libavformat\utils.c中
读取码流中的音频若干帧或者视频一帧。解码视频的时候,每解码一个视频帧,需要先调用 av_read_frame()获得一帧视频的压缩数据,然后才能对该数据进行解码(例如H.264中一帧压缩数据通常对应一个NAL)。
这里我贴上官方的注释,很详细:
/**
* Return the next frame of a stream.
* This function returns what is stored in the file, and does not validate
* that what is there are valid frames for the decoder. It will split what is
* stored in the file into frames and return one for each call. It will not
* omit invalid data between valid frames so as to give the decoder the maximum
* information possible for decoding.
*
* If pkt->buf is NULL, then the packet is valid until the next
* av_read_frame() or until avformat_close_input(). Otherwise the packet
* is valid indefinitely. In both cases the packet must be freed with
* av_packet_unref when it is no longer needed. For video, the packet contains
* exactly one frame. For audio, it contains an integer number of frames if each
* frame has a known fixed size (e.g. PCM or ADPCM data). If the audio frames
* have a variable size (e.g. MPEG audio), then it contains one frame.
*
* pkt->pts, pkt->dts and pkt->duration are always set to correct
* values in AVStream.time_base units (and guessed if the format cannot
* provide them). pkt->pts can be AV_NOPTS_VALUE if the video format
* has B-frames, so it is better to rely on pkt->dts if you do not
* decompress the payload.
*
* @return 0 if OK, < 0 on error or end of file
*/
总结起来每段的核心意思
读取码流中的音频若干帧或者视频一帧
如果pkt->buf是空,那么就要等待下一次av_read_frame调用。否则无法确定是否有效
pts dts duration通常被设置为正确的值。但如果视频帧包括Bzh帧,那么pts可以是AV_NOPTS_VALUE。所以最好依赖dts。
av_interleaved_write_frame
输出一帧视音频数据
核心类
AVFormatContext
AVFormatContext是一个贯穿始终的数据结构,很多函数都要用到它作为参数。它是FFMPEG解封装(flv,mp4,rmvb,avi)功能的结构体。
内部的成员变量,大家可以查看头文件。这里我们列举下一些常用重要的成员变量:
struct AVInputFormat *iformat:输入数据的封装格式
AVIOContext *pb:输入数据的缓存
unsigned int nb_streams:视音频流的个数
AVStream **streams:视音频流
char filename[1024]:文件名
int64_t duration:时长(单位:微秒us,转换为秒需要除以1000000)
int bit_rate:比特率(单位bps,转换为kbps需要除以1000)
AVDictionary *metadata:元数据
视频的原数据(metadata)信息可以通过AVDictionary获取。元数据存储在AVDictionaryEntry结构体中
typedef struct AVDictionaryEntry {
char *key;
char *value;
} AVDictionaryEntry;
每一条元数据分为key和value两个属性。
在ffmpeg中通过av_dict_get()函数获得视频的原数据。
cout << endl << endl << "======元信息=======" << endl;
string meta, key, value;
AVDictionaryEntry *m = NULL;
while (m = av_dict_get(ictx->metadata, "", m, AV_DICT_IGNORE_SUFFIX)) {
key=m->key;
value=m->value;
meta.append(key).append("\t:").append(value).append("\r\n");
}
cout << meta.c_str() << endl;
AVStream
AVStream是存储每一个视频/音频流信息的结构体。
int index:标识该视频/音频流
AVCodecContext codec:指向该视频/音频流的AVCodecContext(它们是一一对应的关系)
AVRational time_base:时基。通过该值可以把PTS,DTS转化为真正的时间。- FFMPEG其他结构体中也有这个字段,但是根据我的经验,只有AVStream中的time_base是可用的。PTStime_base=真正的时间
int64_t duration:该视频/音频流长度
AVDictionary *metadata:元数据信息
AVRational avg_frame_rate:帧率(注:对视频来说,这个挺重要的)
AVPacket attached_pic:附带的图片。比如说一些MP3,AAC音频文件附带的专辑封面。
AVPacket
AVPacket是存储压缩编码数据相关信息的结构体。
uint8_t *data:压缩编码的数据。
例如对于H.264来说。1个AVPacket的data通常对应一个NAL。
注意:在这里只是对应,而不是一模一样。他们之间有微小的差别:使用FFMPEG类库分离出多媒体文件中的H.264码流
因此在使用FFMPEG进行视音频处理的时候,常常可以将得到的AVPacket的data数据直接写成文件,从而得到视音频的码流文件。
int size:data的大小
int64_t pts:显示时间戳
int64_t dts:解码时间戳
int stream_index:标识该AVPacket所属的视频/音频流。