大家都知道,Spark可以和各种数据库进行连接并读取数据,今天就说说如何连接hive并读取数据。
方法一:在IDEA中连接hive
在pom.xml中添加依赖
导入mysql的驱动包和spark连接hive的驱动包
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.4</version>
</dependency>在main主目录下创建一个resources文件夹,创建好后右键单击,选择Make Directory as,选择Resources Root选项,接下来就是把配置文件放到这个文件夹下;
前面已经讲过配置hadoop和hive,在这里就不多说了;
把hadoop的配置文件hdfs-site.xml core-site.xml和hive的配置文件hive-site.xml复制到resources文件夹下;
hadoop的配置文件在hadoop260/etc/hadoop目录下;
hive的配置文件在hive110/conf目录下
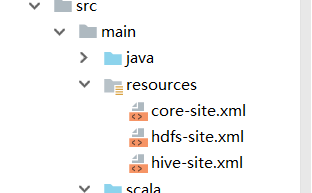
如图所示的位置;
然后在hive-site.xml中修改jdbc的url的ip为自己主机的ip地址
配置好以上信息后,启动hive就不多说了,然后选择一个数据库和其中一张表,先查看数据,查询完有数据时,回到IDEA中,创建scala目录并新建一个object类,接下来开始连接hive
import org.apache.spark.sql.SparkSession
object MyHiveSpark {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[*]")
.appName("spark_hive")
.enableHiveSupport()
.getOrCreate()
val df = spark.sql("select * from userinfos.user")
df.show()
}
}注意:
sql语句中有点不一样,就是查询的时候要带上数据库名.表名的语法
这样就能查询hive中的数据
方法二:在Linux系统下连接hive
1.把上面那所说的三个配置文件复制到spark/conf的文件下
cp /opt/soft/hive110/conf/hive-site.xml /opt/soft/spark240/conf/
cp /opt/soft/hadoop260/etc/hadoop/core-site.xml /opt/soft/spark240/conf/
cp /opt/soft/hadoop260/etc/hadoop/hdfs-site.xml /opt/soft/spark240/conf/2.把mysql的驱动包和spark连接hive的驱动包复制到spark240/jars文件夹里
3.驱动包可以到本地maven仓库中去找,直接拖到上面所说的地方,在这里就不多说了
4.启动spark并进入shell界面,前面在讲spark安装的时候有说过如何启动,可以自己去看
cd /opt/soft/spark240/bin
./spark-shell
import org.apache.spark.sql.hive.HiveContext
val hiveContext = new HiveContext(sc)
hiveContext.sql("select * from test").show() 如图所示,这样就能查询到hive中的数据了!
如图所示,这样就能查询到hive中的数据了!
注意:
在执行hiveContext.sql(“select * from test”).show() 会报一个异常:
The root scratch dir: /tmp/hive on HDFS should be writable.
Current permissions are: rwxr-xr-x如下图所式:

解决办法:
更改HDFS目录/tmp/hive的权限
hadoop fs -chmod 777 /tmp/hive同时删HDFS与本地的目录/tmp/hive
hadoop fs -rm -r /tmp/hive方法三:使用SparkSQL连接hive
同样先添加依赖就不都说了
def main(args: Array[String]): Unit = {
val Array(inpath, dt, hour) = args
val conf = new SparkConf().setAppName(this.getClass.getSimpleName)
//.setMaster("local[*]")
.setMaster("spark://192.168.5.150:7077")
val session = SparkSession.builder()
.config(conf)
// 指定hive的metastore的端口 默认为9083 在hive-site.xml中查看
.config("hive.metastore.uris", "thrift://192.168.5.150:9083")
//指定hive的warehouse目录
.config("spark.sql.warehouse.dir", "hdfs://192.168.5.150:9000/user/hive/warehouse")
//直接连接hive
.enableHiveSupport()
.getOrCreate()
import session.implicits._
val df1 = session.read.parquet(inpath)
//df1.write.saveAsTable(s"tmp.tmp_app_log_1")
df1.createOrReplaceTempView("test")
//sql的代码省略
val sql1 =
s""" select * from test """ .stripMargin
val tmp_table = s"""tmp_app_log_ ${dt}_ ${hour}"""
val df2 = session.sql(sql1)
//结果写入临时表
df2.write.saveAsTable(tmp_table)