说个小笑话,元旦放几天假回来,对自己的代码还生疏了些。于是准备这篇给mysql做个较全面的总结,方便自己下次查阅,也希望能给大家一些帮助。
mysql问题
-
mysql基础
常规增删改查语句铺出来先。
增加语句:insert into table1(field1,field2) values(value1,value2)
删除语句:delete from table1 where 条件
修改语句:update table1 set field1=value1 where 条件
查询语句 select * (或者要查询的字段)from table1 where 条件
常规的,会用以上四条语句,能解决80%的问题。 -
进阶的mysql——基于查询语句
不管在哪个项目,查询是重点。
关于查询的几个进阶语句:
group by: 分组
order by : 排序
having:筛选
limit:展示个数条件
例:
(假设是某考试,每个人考三次,大于80分的合格,抽出资历深(年龄大的)的3对男女外出教学授课)
即为:查找1班(class_one)中平均成绩(score)大于80,年龄(age)最大的前3名的男学生和女学生的信息(t1表)
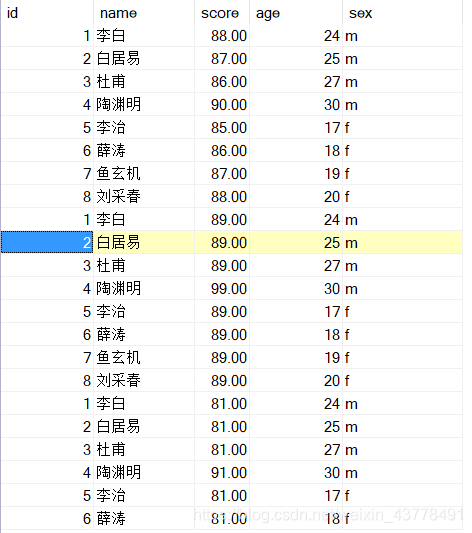
思路:由于要查男生前三 和女生前三,及需要把原始数据表分为多个表进行查询,
这里只有男女两个性别,则直接用union进行连接,先查出男生中年龄最大的三个即可。
答案为:
(select *, from t1 where sex=‘f’ group by name having avg(score)>80 order by age desc limit 3 )
union all (select * from t1 where sex=‘m’ group by name having avg(score)>80 order by age desc limit 3 );
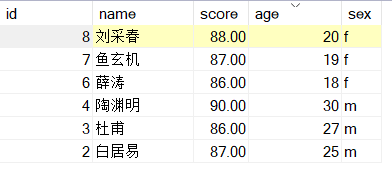
有个注意的地方,平均成绩大于80 必要用having 不能用where,
having可以用的前提是我已经筛选出了的字段,进行函数结合式筛选,但是如果我没有就会报错,因为having是从前筛选的字段再筛选,而where是从数据表中的字段直接进行的筛选的,且不能用函数表达式。 -
数据库的备份和恢复
这个没啥可说 就两个语句
备份:mysqldump -u用户名 -p 源库名 > XXX.sql
源库名:
–all-databases 备份所有库
库名 备份单个库
-B 库1 库2 库3 备份多个库
库名 表1 表2 表3 备份多张表
恢复: mysql -u用户名 -p 目标库名 < XXX.sql -
索引问题
这个呢,是不是一个好的数据库工程师,就看你这个索引问题优化的怎么样了。
常见索引注意点也就是
1,避免无意义的索引,每个索引要有意义。
2,组合索引得支持前缀索引。
3,mysql是以B树的形式保存索引的,增删的时候mysql会自动维护索引位置,以维护树的平衡。及索引越多,移动的次数越多,成本越高。
还有一些原则:
1,数据少的表就不要索引;
2,若字段频繁更新增减,也不适合建立索引。
3,在查询时,在where,group by ,order by 等后面接的字段加索引。python——mysql操作
简化下mysql 数据库编程的流程就以下这么多,正常项目中,这些语句都会拆分在每个类或者方法里,便于重复利用。这里需要注意的就是游标对象的属性及函数。import pymysql db=pymysql.connect( host="localhost", user="root", passwd="123456", database="数据库名", charset="utf8") #2,创建游标对象 cur=db.cursor() #3,利用游标对象的方法执行sql命令 cur.execute(要执行的sql语句) #例如 'select * from t1' #4.提交到数据库 db.commit() #5.关闭游标对象 cur.close() #获取数据 data=cur.fetchall() #6.关闭数据库连接 for row in data: print(row) db.close() -
游标原理
游标在sql中有一段内存区域,也正因为此,mysql可以有数据的回滚。
除了上面例子中的属性,游标对象还有个属性是cur.rowcount 表示sql更改了表多少行。
游标的优缺点, 因为游标有一段内存,所以他可以保存查询的结果,我们可以对这个查询的结果进行若干次查询,效率十分高。
缺点是,游标使用时会对行进行加锁,当有多个业务需要进行操作时,会受影响;同时,因为游标的数据是放在内存上,当数据过大,会造成内存不足。
最后附上两个思考题
1.索引是什么?有什么作用以及优缺点?
索引是对数据库表中一或多个列的值进行排序的结构,是帮助MySQL高效获取数据的数据结构,使数据库程序迅速地找到表中的数据,而不必扫描整个数据库。
MySQL数据库几个基本的索引类型:普通索引、唯一索引、主键索引、全文索引
优点:
索引加快数据库的检索速度
索引降低了插入、删除、修改等维护任务的速度
唯一索引可以确保每一行数据的唯一性
通过使用索引,可以在查询的过程中使用优化隐藏器,提高系统的性能
缺点:
索引需要占物理和数据空间
索引需动态维护,占用系统资源
2.什么是事务?什么是锁?
事务:
就是被绑定在一起作为一个逻辑工作单元的SQL语句分组,如果任何一个语句操作失败那么整个操作就被失败,以后操作就会回滚到操作前状态,或者是上有个节点。事务机制可以确保数据一致性。
事务的四个特点:
原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
一致性(consistency)。事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
锁:
在所有的DBMS中,锁是实现事务的关键,锁可以保证事务的完整性和并发性。与现实生活中锁一样,它可以使某些数据的拥有者,在某段时间内不能使用某些数据或数据结构。当然锁还分级别的。
按粒度:有行级锁和表级锁。
按类型:读锁(共享锁)
select:加读锁后别人不能更改表记录,但可查询
写锁(互斥锁、排他锁)
update:加写锁后别人不能查询,不能改
按锁的机制分为:乐观锁和悲观锁
乐观锁:很乐观,觉得除了自己都不会有人去修改,所以查询、修改数据库时不会上锁,所以再数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,这样可以省去了锁的开销,加大了系统的整个吞吐量,但如果发现冲突了,就需要特殊处理了。
悲观锁:很悲观,觉得每个人都可能回去改所以每次查询、修改数据操作之前就会上锁,整个数据处理过程中,将数据处于锁定状态,自己更新数据后再释放锁,可以有效防止库存冲突问题。但是这样效率就很低。