文章内容输出来源:拉勾教育Java高薪训练营;
环境介绍
服务器: 阿里云Centos7.4
hadoop版本: hadoop-2.7.2
下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2
搭建环境
| 节点 | teacher1 | teacher2 | teacher3 |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | DataNode,secondarynamenode |
| YARN | NodeManager | ResourceManager,NodeManager | NodeManager |
配置host
vi /etc/hosts
39.107.96.104 teacher1
172.17.50.3 teacher2
172.17.50.4 teacher3
172.17.50.2 teacher1
39.107.72.162 teacher2
172.17.50.4 teacher3
172.17.50.2 teacher1
172.17.50.3 teacher2
39.107.67.194 teacher3
- 阿里云有个坑,配置自己的主机名是要用外网ip,其他主机要用内网ip。
SSH互通环境
MHA集群的各节点直接需要基于ssh互相通信,先将主从的服务器之间免密ssh互通
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub root@teacher1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@teacher2
ssh-copy-id -i ~/.ssh/id_rsa.pub root@teacher3
安装Hadoop
- 用文件传输工具工具将hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面
- 进入到Hadoop安装包路径下
cd ~/software/
- 解压安装文件到/opt/module下面
tar -zxvf hadoop-2.7.2.tar.gz -C /home/teacher/opt/module/
- 将hadoop添加到环境变量打开/etc/profile:在profie文件末尾添加jdk路径
vi /etc/profile
export HADOOP_HOME=/home/teacher/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
source /etc/profile
- 测试是否安装成功
hadoop version
集群配置
1.配置hadoop-env.sh
vi hadoop-env.sh
//文件末尾
export JAVA_HOME=/opt/module/jdk1.8.0_231
2.核心配置文件:core-site.xml(hdfs的核心配置文件)
vi core-site.xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://teacher1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/teacher/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
3.hdfs配置文件 hdfs-site.xml
vi hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--secondarynamenode的地址--> 辅助namenode工作
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>teacher3:50090</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/teacher/data/hadoop/name/</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/teacher/data/hadoop/data/</value>
</property>
4.yarn配置文件
vi yarn-env.sh
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>teacher2</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3072</value>
</property>
5.mapreduce配置文件
cp mapred-site.xml.template mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.配置集群中从节点信息
vim slaves
teacher1
teacher2
teacher3
7.分发文件,将teacher1中hadoop目录下的软件拷贝到其他机器
scp -r hadoop-2.7.2 teacher3:/home/teacher/opt/module/
集群启动
如果果集群是第一次启动,需要格式化NameNode
hadoop namenode -format
1. 各个服务组件逐一启动/停止(集群某个进程挂掉使用这种方式重启 )
分别启动/停止hdfs组件
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenod
启动/停止yarn.
yarn-daemon.sh start|stop resourcemanager|nodemanager
2、分模块启动,集群启动方式
(1)整体启动/停止hdfs(在namenode节点启动)
start-dfs.sh
stop-dfs.sh
(2)整体启动/停止yarn (在resourcemanager节点启动)
start-yarn.sh
stop-yarn.sh
测试结果
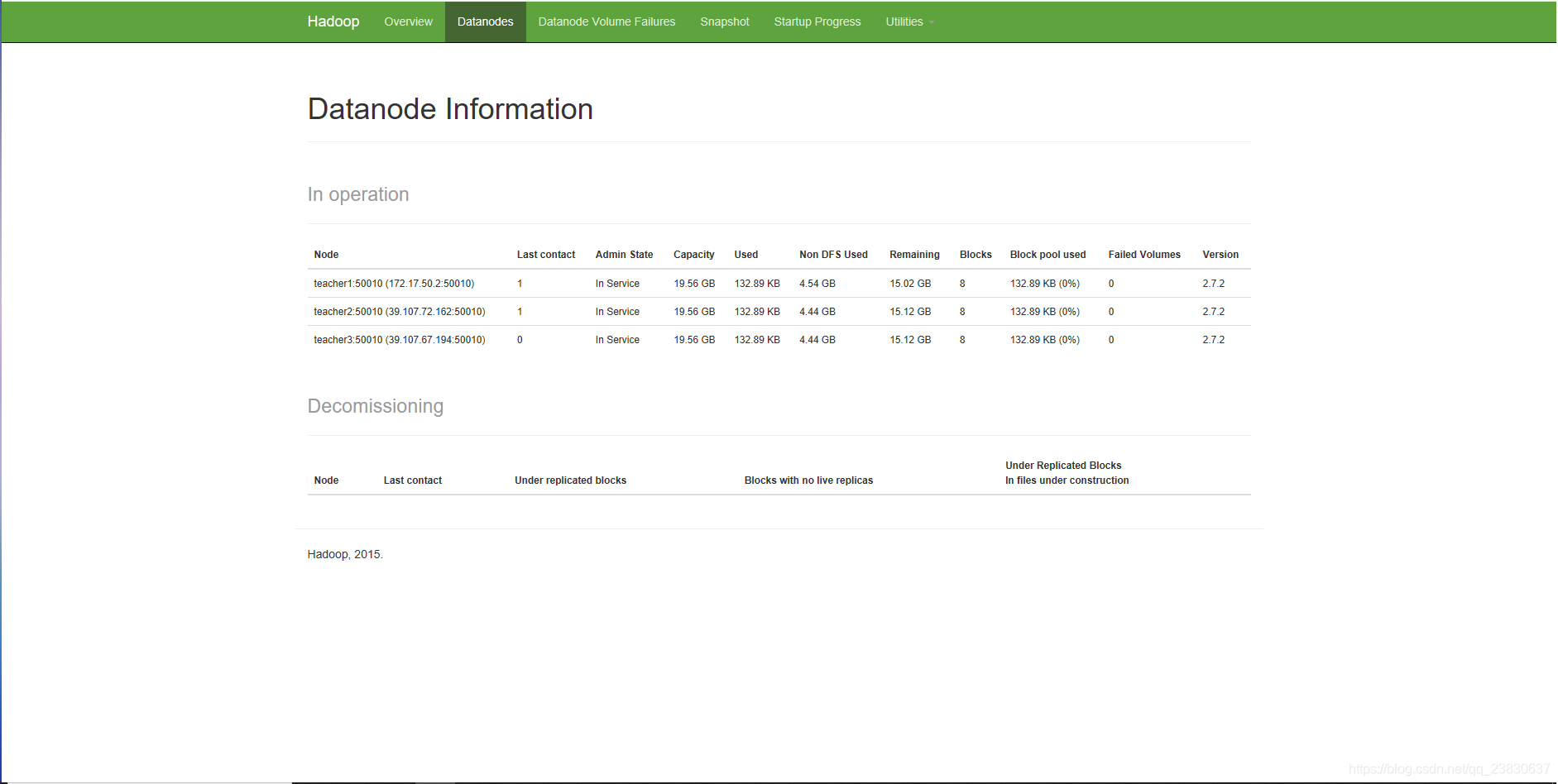
Web端查看SecondaryNameNode:
http://teacher3:50090/status.html
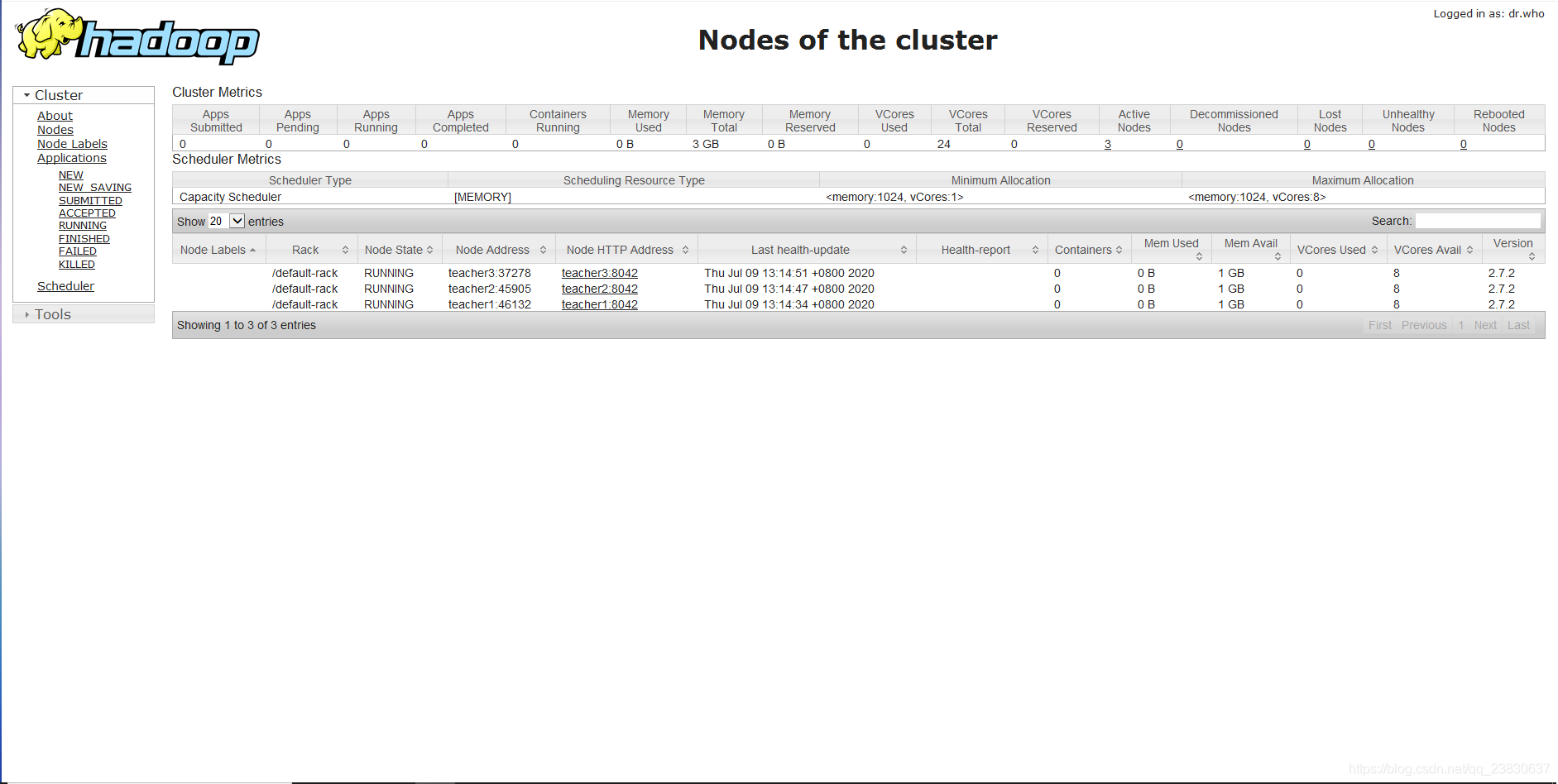
Yarn的web页面查看地址:http://teacher2:8088/
写在最后
工作几年,一直都没有去体系化的学习,很多东西没有复杂的工作场景经验,去年综合几家机构,最后还是决定报了拉勾的高薪训练营,在这里也是实实在在的学习到了很多,学完掌握程度也比之前深了很多,而且还有定期的内推,多了更多的机会,真的对我有了很大的帮助提升。