TCP连接的建立与拆除全状态

图中蓝色箭头是server端(或者说是passive端)要干的事情,红色箭头是client端(或者说是active端)要干的事情。
flow control
主要解决的问题:
避免由于【发送方速度过快,接收方跟不上】导致的流量浪费
flow control的方法:
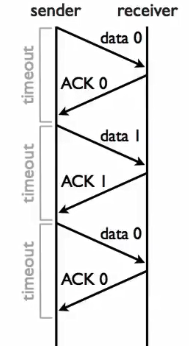
1.stop and wait协议:
(1)路径上同一时刻只能有1个数据包
(2)接收方收到以后,要发回去一个ack包
(3)发送方收到ack包以后,就能够继续发下一个数据包
(4)如果限时之内仍未收到ack包,它就认为是网络问题导致了丢包,于是发送方重发该数据包

限时之内未收到ack包对应的可能情况:
1.data半路丢了
2.data到了,ack半路丢了
3.data到了,ack在限时之内没送到。
第三种情况有点糟糕,因为在重发data以后,发送方才收到ack,并且发送了下一份data。那么发送方并不知道【将要收到的ack】是用来确认【收到重发data】还是确认【收到下一份data】的。因此为了避免这种重复的糟糕情况,ack包中使用一个【一位计数器】。由于相邻两次data对应ack中的计数器值肯定不同,因此可用来检测是否重复。
不过这种方法也是建立在这样的前提之上:一次发送的时延不超过一次timeout,网络自身也不会产生重复的包。如果不满足的话,增加计数器的位数即可解决。

2.sliding window协议:
stop and wait有个最主要的问题:
假设A向B发送数据,遵循stop and wait的原理,只有。待发送的数据包统一都是12kbit,RTT(round to trip,往返时间,也就是从发送data到收到对应ack花费的时间)=50ms,那么A每秒可发送给B的数据总量为12kbit×(1s÷50ms)=12kbit×20=240kbit,而B的每秒接收数据总量瓶颈是10Mbit/s,仅用了很小一部分,虽然控制了流量不会超过B,但发送效率很低。
注意:发送效率的计算:分组长度为12kbit,发送速度为10Mbit/s,则发送需要1.2ms。RTT=20ms,则发送一组共需要(20+1.2)=21.2ms,利用率为1.2/21.2=0.0566
由此就有了stop and wait的一般化版本——sliding window。
(1)路径上同一时刻最多可以有N个数据包(包括N个data和N个ack)
(2)接收方收到以后,要发回去一个ack包
(3)发送方收到ack包以后,就能够继续发下一个数据包
(4)如果限时之内仍未收到ack包,它就认为是网络问题导致了丢包,于是发送方重发该数据包
可以看到(2)~(4)步和stop and wait是一样的,最大的改动是(1)。N由接收方B的每秒接收数据总量瓶颈决定,也就是说可以控制N,使得A每秒可发送给B的数据总量接近B的每秒接收数据总量瓶颈
以刚刚的A和B例子来计算的话,想要达到理想情况10Mbit/s,N应满足12kbit×N×20=10Mbit,即N=500/12=41
sliding window的实现中,用到了以下变量:
0.序列号:数据包在数据流中的序列号
1.SWS(sliding window size):相当于N。
2.LAR(last acknowledgment received):最近一次接收到的ack包对应的数据包序列号
3.LSS(last segment sent):最近一次已发送的数据包序列号。
及时更新更新LAR和LSS,每次发送都要控制好这个不等式:(LSS-LAR)≤ SWS或者LSS≤ SWS+LAR
例如:如果SWS=5,LSS=12,LAR=10,那么接下来发送方最多可以准备发送序列号为13、14、15的数据包。
接下来,如果发送方成功发送了13,但仍未收到11的ack包,那么发送方最多可以准备发送序列号为14、15的数据包。
如果此时收到了11和12的ack包,则发送方最多可以准备发送序列号为14、15、16、17的数据包。
更形象地说,LAR是sliding window的左边缘,LSS是sliding window包含的数据包序列号,SWS是sliding window的最大长度