今天看到了一则令NLP人振奋的消息,谷歌发布了迁移学习之最强模型-BERT,该模型一举打破了11项纪录,尤其是在斯坦福大学的SQuAD数据集上再次超越了人类评测专家标准,包括将GLUE基准推至80.4%(绝对改进7.6%),MultiNLI准确度达到86.7%(绝对改进率5.6%)等。被称为“全面超越人类的模型”,下面我们就看看BERT模型厉害之处。
BERT(Bidirectional Encoder Representations from Transformers)意思是来自Transformer 的双向编码器表征,与最近的语言表征模型不同,BERT基于所有层中的左、右语境进行联合调整,来预训练深层双向表征。因此,只需要增加一个输出层,就可以对预训练的 BERT 表征进行微调,就能为更多的任务创建当前的最优模型,比如问答和语言推断任务。整个过程不需要对特定任务进行实质性的架构修改。
模型架构对比:
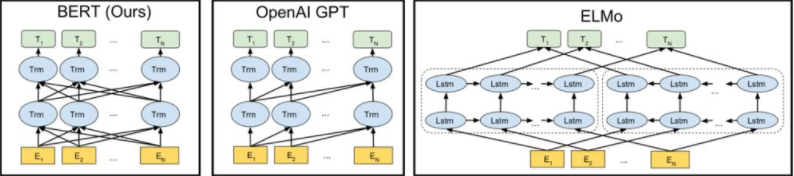
从左至右依次为BERT、OpenAI GPT以及ELMo模型架构
BERT 使用双向 Transformer,OpenAI GPT 使用从左到右的 Transformer,ELMo 使用独立训练的从左到右和从右到左 LSTM 的级联,来生成下游任务的特征。三种模型中,只有 BERT 表征是联合的,基于所有层中的左右两侧语境。
输入表征
输入表征能够在一个标记序列中清晰地表示单个文本句子或两个文本句子(例如,[问题、答案])。对于给定的token,其输入表征是通过对相应的token、分段和位置嵌入求和来构建的。

具体的情况是:
使用WordPiece嵌入,拥有30000个token词汇。用##表示拆分的单词片段。
使用学习的位置嵌入,支持多达512个token的序列长度。每个序列的第一个token是特殊分类嵌入([CSL])。对应于该token的最终隐藏状态(即Transformer的输出)被用作分类任务的聚合序列表征。对于非分类的任务,则忽略此向量。句子对被组合成单一的序列。用两种方式区分句子。首先,用一个特殊的token将它们分开([SEP])。其次,在第一句的每一个token中添加了一个学习句子A嵌入,在第二句的每一个token中添加了一个句子B嵌入。对于单句输入,只使用句子A嵌入。
BERT的主体结构和创新点
BERT模型沿袭了GPT模型的结构,采用Transfomer的编码器作为主体模型结构。Transformer舍弃了RNN的循环式网络结构,完全基于注意力机制来对一段文本进行建模。
Transformer所使用的注意力机制的核心思想是去计算一句话中的每个词对于这句话中所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及重要程度。因此再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。
Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。
Transformer的注意力层得到的词-词之间关系
GPT则利用了Transformer的结构来进行单向语言模型的训练。所谓的语言模型其实是自然语言处理中的一种基础任务,其目标是给定一个序列文本,预测下一个位置上会出现的词。

模型学习这样的任务过程和我们人学习一门语言的过程有些类似。我们学习语言的时候会不断地练习怎么选用合适的词来造句,对于模型来说也这样。例如:
>今天 天气 不错, 我们 去 公园 玩 吧。
这句话,单向语言模型在学习的时候是从左向右进行学习的,先给模型看到“今天 天气”两个词,然后告诉模型下一个要填的词是“不错”。然而单向语言模型有一个欠缺,就是模型学习的时候总是按照句子的一个方向去学的,因此模型学习每个词的时候只看到了上文,并没有看到下文。更加合理的方式应该是让模型同时通过上下文去学习,这个过程有点类似于完形填空题。例如:
>今天 天气 { }, 我们 去 公园 玩 吧。
通过这样的学习,模型能够更好地把握“不错”这个词所出现的上下文语境。
而BERT对GPT的第一个改进就是引入了双向的语言模型任务。
此前其实也有一些研究在语言模型这个任务上使用了双向的方法,例如在ELMo中是通过双向的两层RNN结构对两个方向进行建模,但两个方向的loss计算相互独立。
不得不说的是,Google在NLP和深度学习方面已经走得很远了,去年的时候众多模型还不能达到评测专家水平,而近年10月份就能超越,真的是首屈一指的大家。我们作为后生,实在是应该潜下心来认真学习,希望能够追赶并超越。虽然国内的众多巨头都在不同的领域发表了顶会论文,但是和Google比起来,怕也是有不小的差距,因此,我们应该努力打造国内互相交流、相互促进的好环境。
另附上BERT的论文链接https://arxiv.org/abs/1810.04805
以上部分内容参考于http://news.cnfol.com/it/20181020/26955952.shtml