一、Keepalived是什么?
Keepalived是一款高可用软件,它的功能主要包括两方面:
1)通过IP漂移,实现服务的高可用:服务器集群共享一个虚拟IP,同一时间只有一个服务器占有虚拟IP并对外提供服务,若该服务器不可用,则虚拟IP漂移至另一台服务器并对外提供服务;
2)对LVS应用服务层的应用服务器集群进行状态监控:若应用服务器不可用,则keepalived将其从集群中摘除,若应用服务器恢复,则keepalived将其重新加入集群中。
二、keepalived工作原理
keepalived是以VRRP协议为实现基础的,VRRP全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
虚拟路由冗余协议,可以认为是实现路由器高可用的协议,即将N台提供相同功能的路由器组成一个路由器组,这个组里面有一个master和多个backup,master上面有一个对外提供服务的vip(该路由器所在局域网内其他机器的默认路由为该vip),master会发组播,当backup收不到vrrp包时就认为master宕掉了,这时就需要根据VRRP的优先级来选举一个backup当master。这样的话就可以保证路由器的高可用了。
keepalived主要有三个模块,分别是core、check和vrrp。core模块为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。check负责健康检查,包括常见的各种检查方式。vrrp模块是来实现VRRP协议的。
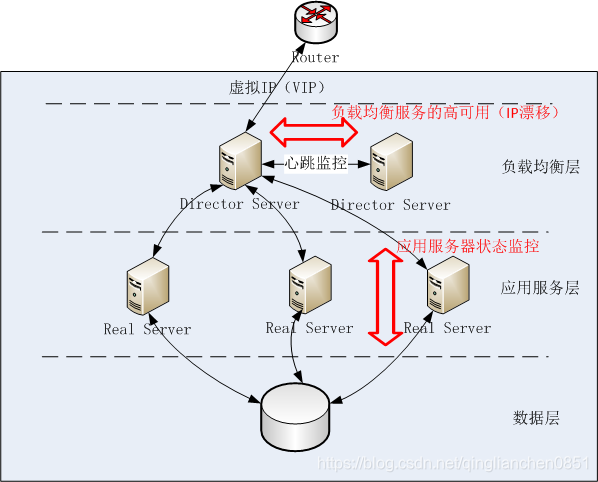
Keepalived可以单独使用,即通过IP漂移实现服务的高可用,也可以结合LVS使用,即一方面通过IP漂移实现LVS负载均衡层的高可用,另一方面实现LVS应用服务层的状态监控,如图所示:
三、Keepalived高可用故障切换转移原理
Keepalived 高可用服务对之间的故障切换转移,是通过 VRRP(Virtual Router Redundancy Protocol , 虚拟路由器冗余协议)来切换的。

在 Keepalived 服务正常工作时,主 Master 节点会不断地向备节点发送(多播的方式)心跳消息,用以告诉备 Backup 节点自己还活着,当主 Master 节点发生故障时,就无法发送心跳消息,备节点也就因此无法继续检测到来自主 Master 节点的心跳了,于是调用自身的接管程序,接管主 Master 节点的 IP 资源及服务。而当主 Master 节点恢复时,备 Backup 节点又会释放主节点故障时自身接管的 IP 资源及服务,恢复到原来的备用角色。
四、结合Keepalived在DR模式下的DS高可用实现
在lvs的服务中,若DS宕掉了整个服务就会瘫痪,因此需要准备一台备用的DS,并结合Keepalived实现高可用。
本次实验需要4台虚拟机和1个物理机:
| 虚拟机名称 | 作用 | IP |
|---|---|---|
| server2 | DS(master) | 172.25.254.2 |
| server4 | RS1 | 172.25.254.3 |
| server5 | RS2 | 172.25.254.4 |
| server3 | DS (backup) | 172.25.254.3 |
VIP为:172.25.254.100
测试服务:Http 端口:80
物理机为客户端
1.安装keepalived 在server2和server3
yum install keepalived -y2.配置keepalived
在server2上
cd /etc/keepalived/
vim keepalived.conf
1 ! Configuration File for keepalived
2
3 global_defs {
4 notification_email {
5 root@localhost #服务器出问题后发送提醒邮件的地址,此处设置为本机
6 }
7 notification_email_from keepalived@localhost #提醒邮件的发送人,此处设置为本机
8 smtp_server 127.0.0.1 #发送服务器
9 smtp_connect_timeout 30 #指定smtp超时连接时间
10 router_id LVS_DEVEL
11 vrrp_skip_check_adv_addr
12 #vrrp_strict #需要注释掉
13 vrrp_garp_interval 0
14 vrrp_gna_interval 0
15 }
16
17 vrrp_instance VI_1 {
18 state MASTER #将server1作为主节点
19 interface ens33
20 virtual_router_id 51 #标识
21 priority 100 #优先级,100最高
22 advert_int 1 #每隔1s监测一次
23 authentication { #认证方式
24 auth_type PASS
25 auth_pass 1111
26 }
27 virtual_ipaddress {
28 172.25.254.100 #VIP
29 }
30 }
31
32 virtual_server 172.25.254.100 80 {
33 delay_loop 3 #当 RS 报错后尝试3次才会邮件警告
34 lb_algo rr #负载均衡策略为轮询
35 lb_kind DR #LVS工作模式,
36 #persistence_timeout 50 #需要注释掉
37 protocol TCP #协议
38
39 real_server 172.25.254.4 80 { #RS1
40 TCP_CHECK { #TCP检测
41 weight 1 #1为生效,0为生效
42 connect_port 80 #端口
43 connect_timeout 3 #检测后端的超时时间
44 }
45 }
46
47 real_server 172.25.254.5 80 { ##RS2
48 TCP_CHECK {
49 weight 1
50 connect_port 80
51 connect_timeout 3
52 }
53
54
55
56 }
在server3上
cd /etc/keepalived/
vim keepalived.conf
除了这一部分,其他与server1的配置文件相同
17 vrrp_instance VI_1 {
18 state BACKUP #将server4作为备用节点
19 interface ens33
20 virtual_router_id 51
21 priority 50 #优先级,低于server1的优先级
22 advert_int 1
23 authentication {
24 auth_type PASS
25 auth_pass 1111
26 }
27 virtual_ipaddress {
28 172.25.254.100 #VIP
29 }
30 }
4.安装发送邮件软件
yum install mailx -y5.启动服务
在server2和server3
systemctl start keepalived.service
若有错误可查看日志报错
server 3:
若提示没有ipvsadm命令需要安装:yum install ipvsadm -y
6.测试
配置好keepalived后,在客户端测试,说明轮训机制正常:
[kiosk@foundation63 ~]$ curl 172.25.63.100
server
[kiosk@foundation63 ~]$ curl 172.25.63.100
server2
[kiosk@foundation63 ~]$ curl 172.25.63.100
server3
[kiosk@foundation63 ~]$ curl 172.25.63.100
server2
当关闭server3 http服务后(说明keepalived自带后端服务健康检测):
[kiosk@foundation63 ~]$ curl 172.25.63.100
server2
[kiosk@foundation63 ~]$ curl 172.25.63.100 #关闭server2 http
server3
[kiosk@foundation63 ~]$ curl 172.25.63.100
server3
也可使用mail命令在server1查看邮件信息以确定错误:
[root@server1 keepalived]# mail
Heirloom Mail version 12.5 7/5/10. Type ? for help.
"/var/spool/mail/root": 3 messages 3 new
>N 1 keepalived@localhost Thu Feb 20 23:29 17/676 "[LVS_DEVEL] Realserver"
N 2 keepalived@localhost Fri Feb 21 23:51 17/676 "[LVS_DEVEL] Realserver"
当DS server1宕掉后,server4会马上接替server1的工作:
[root@server1 keepalived]# systemctl stop keepalived.service #模拟server1 宕机
[root@server4 ~]# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:fd:33:c9 brd ff:ff:ff:ff:ff:ff
inet 172.25.63.4/24 brd 172.25.63.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.63.100/32 scope global eth0 #server 4 马上获得VIP
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fefd:33c9/64 scope link
valid_lft forever preferred_lft forever
You have new mail in /var/spool/mail/root
此时服务丝毫不受影响
当server 1 再次上线时,由于server 1的优先级高于server4,因此 server 1 又会马上作为DS:
[root@server1 keepalived]# systemctl start keepalived.service #server1 上线
[root@server1 keepalived]# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:1b:f6:56 brd ff:ff:ff:ff:ff:ff
inet 172.25.63.1/24 brd 172.25.63.255 scope global eth0
valid_lft forever preferred_lft forever
inet 172.25.63.100/32 scope global eth0 #马上获得VIP
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe1b:f656/64 scope link
valid_lft forever preferred_lft forever
[root@server4 ~]# ip addr show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:fd:33:c9 brd ff:ff:ff:ff:ff:ff
inet 172.25.63.4/24 brd 172.25.63.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fefd:33c9/64 scope link #server 4 又重新成为BACKUP
valid_lft forever preferred_lft forever
在此一系列的动作中,对客户端的服务丝毫不受影响