1、(千亿级kafka集群性能调优)集群信息
一个kafka集群,40台broker,基于Ambari,hdp管理(ambari_v2.5,hdp_v2.6)
10台broker配置5块3T盘
30台broker配置12块6T盘
每天所有生产端产生2000亿条左右的数据
消费端有SparkStreaming,Flume等业务程序
2、 第一次故障现象
-
生产环境flume无法消费kafka,sink的文件为空。
-
nifi中往kafka写消息报错
-
ISR缺失严重
3、第一次故障排查
-
元数据主题__consumer_offsets正常
-
对应无法消费的业务topic存在部分分区的ISR列表丢失2/3,且随着时间的推移,isr缺失的分区占比在增加
且flume端的消费组一直在rebalance。
尝试调整参数
kafka.consumer.session.timeout.ms=30000ms—增大消费者连接GroupCoordinator会话超时时间
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-50dRhE91-1592536113609)(C:\Users\lenovo\AppData\Roaming\Typora\typora-user-images\image-20200619104612641.png)]](https://img-blog.csdnimg.cn/2020061911095486.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3ODY1NDIw,size_16,color_FFFFFF,t_70)
flume sink 文件依旧为空,再次调大此参数依旧没用,flume的consumerGroup依旧显示在rebalancing
4、第一次解决方案
因为之前出现过类似isr缺失的现象,当时增大了此参数
num.replica.fetchers-------leader中进行复制的线程数,增大这个数值会增加relipca的IO
默认是单线程,当时增加到2
但是这次的问题kafka的server.log没有任何ERROR,能看到的只有nifi生产端的无法生产的ERROR日志(连接broker失败),以及flume消费端的大批量INFO日志(consumer group is rebalancing)
抱着试一试的方式将几十台broker中的两台num.replica.fetchers参数修改为4,增大了一倍,然后重启broker
由于数据量比较庞大,且此broker正在重启,kafka server.log报错如下

属于正常状况,耐心等待重启的broker中副本加入到isr中即可
之后发现flume的sink文件大小有所增加,证明开始消费了。
最后滚动重启所有broker,flume恢复消费,nifi后续生产也不报错了。
疑问点
-
flume修改参数,消费组日志信息中为何依旧提示持续rebalancing?
-
kafka的isr缺失为何导致nifi生产端链接broker失败?—也许集群网络的问题也可能有
kafka的isr同步能力参数见链接解决ISR丢失—— Kafka副本同步leader能力参数
遇到类似isr缺失的问题可以尝试调整这些参数来解决
-
但是这些参数的调整需要与kafka的数据量作对比,现在还没有一个数据量标准来衡量这些参数设置。
5、第二次故障现象
-
在生产端割接后,数据量增大20%
-
消费速度直降,sparkStreaming界面无法刷新,delay time过高,消费缓慢
-
consumer.group脚本查询不出,无法得知lag等偏移量信息
6、第二次性能调优
| 参数 | 当前值 | 推荐值 | 说明 |
|---|---|---|---|
| num.network.threads | 33 | server用来处理网络请求的网络线程数目。增大能够增加处理网络io请求,但不读写具体数据,基本没有io等待。过大,会带来线程切换的开销 用于接收并处理网络请求的线程数,默认为3。其内部实现是采用Selector模型。启动一个线程作为Acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从Sockets里读取请求,一般无需改动,除非上下游并发请求量过大。 |
|
| num.io.threads | 48 | server用来处理请求的I/O线程的数目。这个线程数目至少要等于硬盘的个数。过大,会带来线程切换的开销 |
7、第二次调优监控结果
滚动重启kafka集群后发现有所缓和,但是还是消费慢,并且发现jmx中指标中kafka空闲度低于30%,基本都在10%以下,更甚2%,1%,,证明kafka内部非常繁忙,调大JVM参数至40G依旧不见好转
具体kafka broker端jmx监控指标可以看下面的链接
https://blog.csdn.net/qq_38038143/article/details/89004261
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-m07mY26s-1593746806152)(C:\Users\lenovo\Desktop\MarkDown\千亿级Kafka调优实战总结.assets\9df252d61c2e1fc7525a7d05600ee76.png)]](https://img-blog.csdnimg.cn/20200703112703829.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3ODY1NDIw,size_16,color_FFFFFF,t_70)
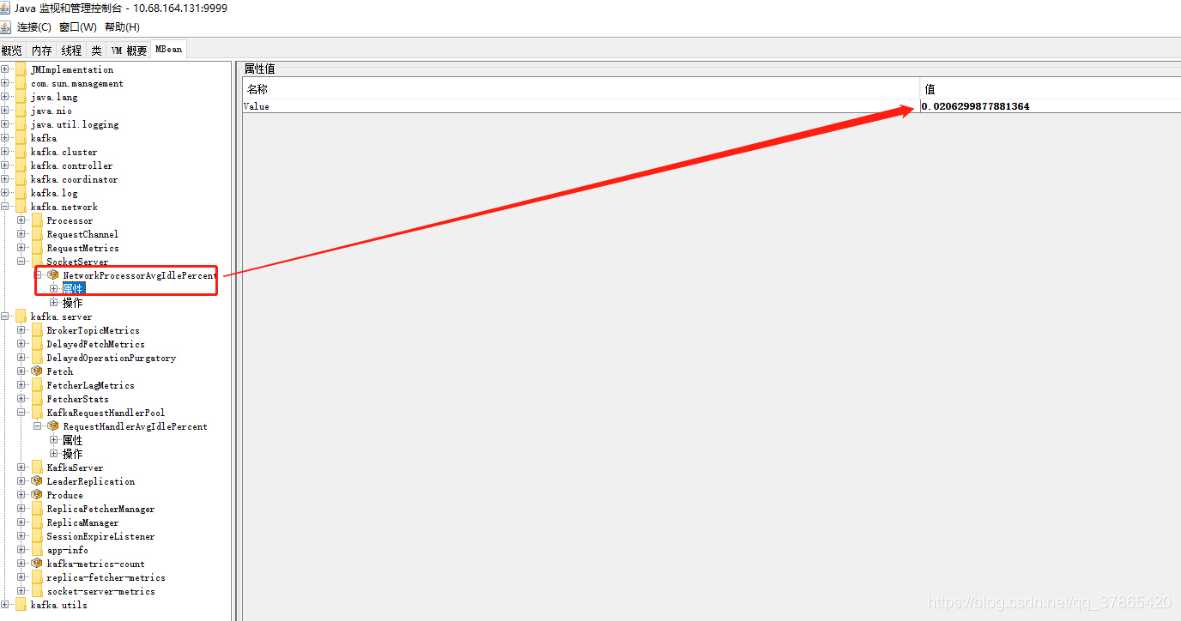
这2个空闲度(分别对应 磁盘IO空闲度,网络空闲度)非常的小,但是观察主机资源却十分富余,猜测kafka配置不够,使得主机资源没有利用起来。决定再次增大kafka调用资源参数
8、第三次性能调优
因为这次调整的参数比较多,并且根据节点的不同情况,需要使用ambari中的配置组
== 10台broker配置5块3T盘 ==
| 参数 | 当前值 | 推荐值 | 说明 |
|---|---|---|---|
| num.network.threads | 33 | 48 | server用来处理网络请求的网络线程数目。增大能够增加处理网络io请求,但不读写具体数据,基本没有io等待。过大,会带来线程切换的开销 用于接收并处理网络请求的线程数,默认为3。其内部实现是采用Selector模型。启动一个线程作为Acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从Sockets里读取请求,一般无需改动,除非上下游并发请求量过大。 |
| num.io.threads | 48 | 64 | server用来处理请求的I/O线程的数目。这个线程数目至少要等于硬盘的个数。过大,会带来线程切换的开销 |
| queued.max.requests | 500 | 4000 | 指定用于缓存网络请求的队列的最大容量,这个队列达到上限之后将不再接收新请求。 在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数。 增大queued.max.requests能够缓存更多的请求,以撑过业务峰值。如果过大,会造成内存的浪费。 |
| socket.receive.buffer.bytes | 102400 | 1024000 | Kafka naturally batches data in both the producer and consumer so it can achieve high-throughput even over a high-latency connection. To allow this though it may be necessary to increase the TCP socket buffer sizes for the producer, consumer, and broker using the socket.send.buffer.bytes and socket.receive.buffer.bytes configurations. The appropriate way to set this is documented |
| socket.send.buffer.bytes | 102400 | 1024000 | |
| controller.message.queue.size | 10 | 100 | partition leader与replicas数据同步时,消息的队列尺寸 |
| replica.socket.receive.buffer.bytes | 65536 | 131072 | 备份时向leader发送网络请求时的socket receive buffer |
== 30台broker配置12块6T盘 ==
| 参数 | 当前值 | 推荐值 | 说明 |
|---|---|---|---|
| num.network.threads | 33 | 90 | server用来处理网络请求的网络线程数目。增大能够增加处理网络io请求,但不读写具体数据,基本没有io等待。过大,会带来线程切换的开销 用于接收并处理网络请求的线程数,默认为3。其内部实现是采用Selector模型。启动一个线程作为Acceptor来负责建立连接,再配合启动num.network.threads个线程来轮流负责从Sockets里读取请求,一般无需改动,除非上下游并发请求量过大。 |
| num.io.threads | 48 | 90 | server用来处理请求的I/O线程的数目。这个线程数目至少要等于硬盘的个数。过大,会带来线程切换的开销 |
| queued.max.requests | 500 | 4000 | 指定用于缓存网络请求的队列的最大容量,这个队列达到上限之后将不再接收新请求。 在网络线程停止读取新请求之前,可以排队等待I/O线程处理的最大请求个数。 增大queued.max.requests能够缓存更多的请求,以撑过业务峰值。如果过大,会造成内存的浪费。 |
| socket.receive.buffer.bytes | 102400 | 1024000 | Kafka naturally batches data in both the producer and consumer so it can achieve high-throughput even over a high-latency connection. To allow this though it may be necessary to increase the TCP socket buffer sizes for the producer, consumer, and broker using the socket.send.buffer.bytes and socket.receive.buffer.bytes configurations. The appropriate way to set this is documented |
| socket.send.buffer.bytes | 102400 | 1024000 | |
| controller.message.queue.size | 10 | 100 | partition leader与replicas数据同步时,消息的队列尺寸 |
| replica.socket.receive.buffer.bytes | 65536 | 131072 | 备份时向leader发送网络请求时的socket receive buffer |
9、第三次调优监控结果
经过参数的加大,发现生产端与消费端都可以正常运行了,再没有消费缓慢的问题出现了!
但是还有新的问题
-
A:但是在运维过程中,对某些主题进行分区迁移时(主题-1k分区-单分区迁移),相比参数加大调优之前迁移速度极为缓慢。
-
B:并且ISR列表变得极为不稳定,白天业务多,数据量起来了后,大部分主题的分区一直处于频繁的expand,shrink
对于问题A,我进行了kafka分区迁移源码的探索
有兴趣可以查看https://blog.csdn.net/qq_37865420/article/details/107037215
对于问题 B先是监控了jmx指标,再分析参数是否还需要调整,最后再用nmon,iostate,iotop等工具看主机资源等操作。实在查不出来原因
jmx指标如下图的左边是10台5块3T,右边是30台12块6T
- RequestHandlerAvgIdlePercent
请求处理器空闲率(不得低于0.3,如果低于则需要进行加大num.io.thread)。。。我已经加了那么大-。-!!

NetworkProcessorAvgIdlePercent(不得低于0.3,如果低于则需要进行加大num.network.thread),这个就很大了,表示kafka内部网络很正常
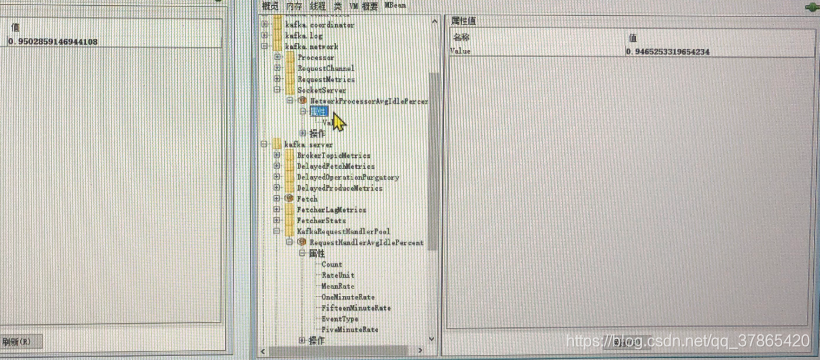
IsrExpandsPerSec(ISR的expand频率)
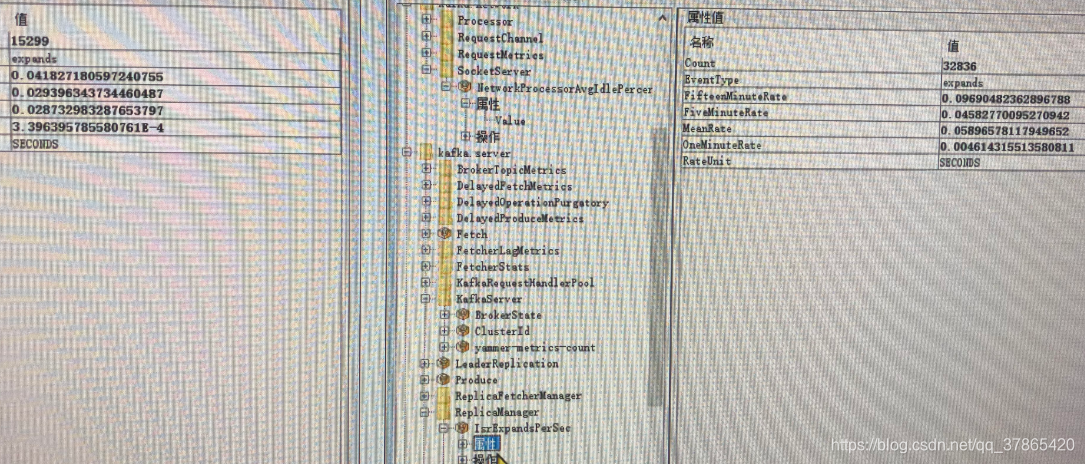
IsrShrinkPerSec(ISR的shrink频率)

RequestQueueSize(请求对列1404)
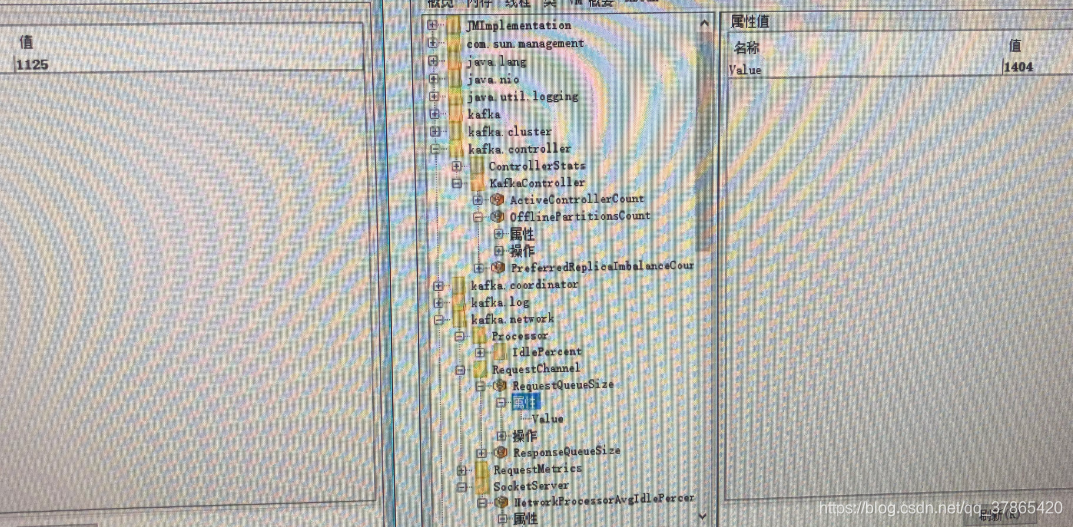
ResponseQueueSize(response1)
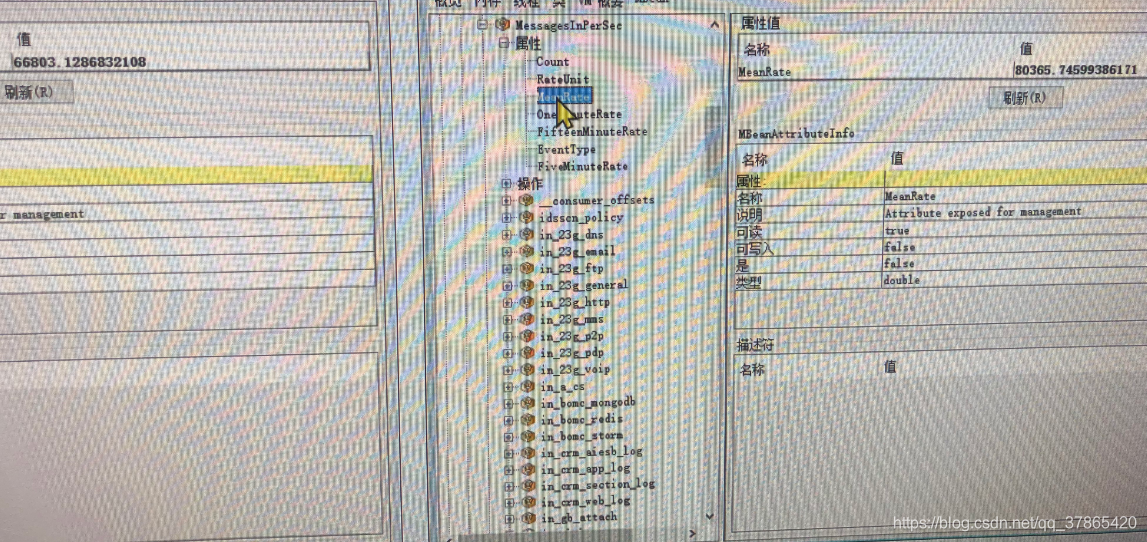
MessagesInPerSec(每秒数据生产量80365)
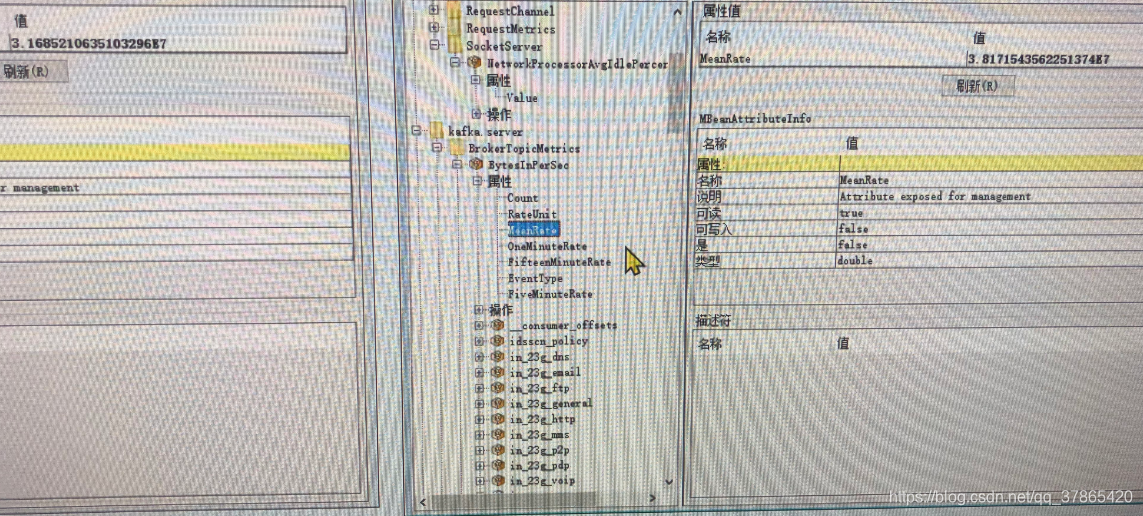
BytesInPerSec(每秒生产3.8E7)
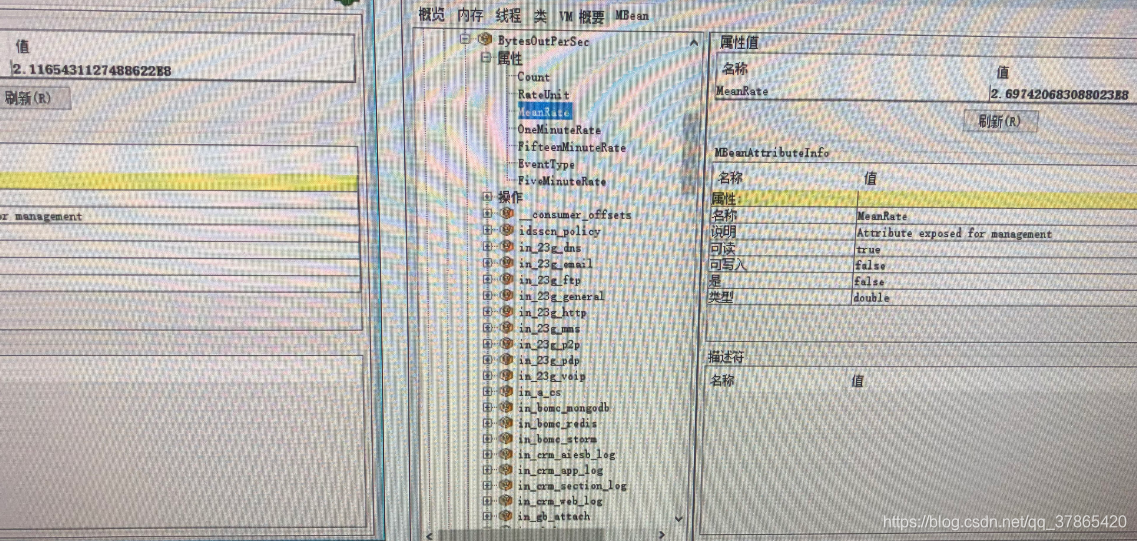
BytesOutPerSec(每秒被消费2.7E8)
PartitionCount
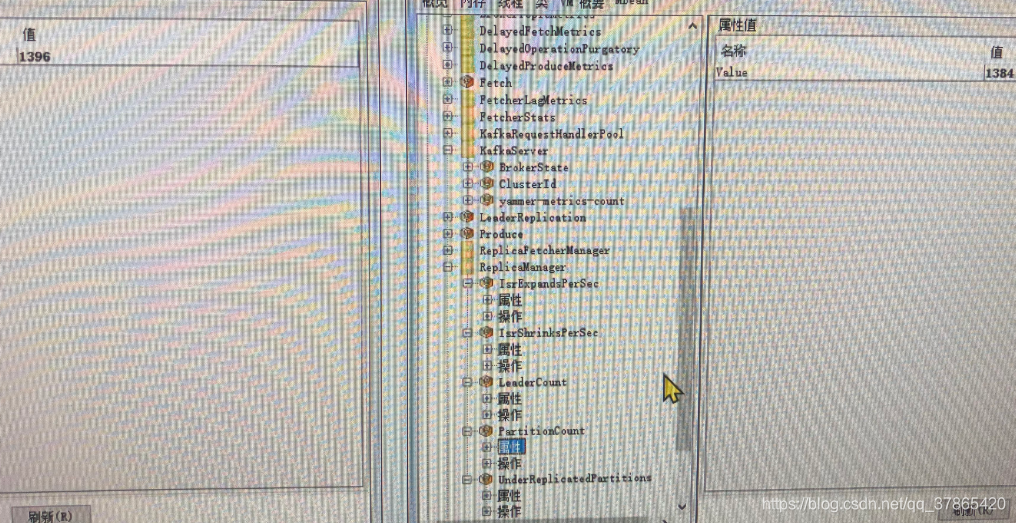
LeaderCount
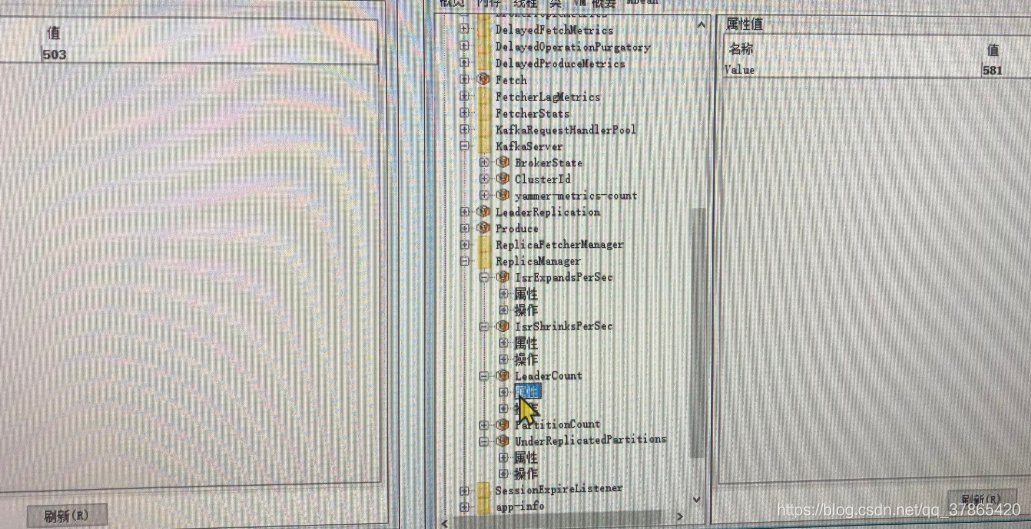
UnderReplicatedPartitions(ISR缺失蛮多的)
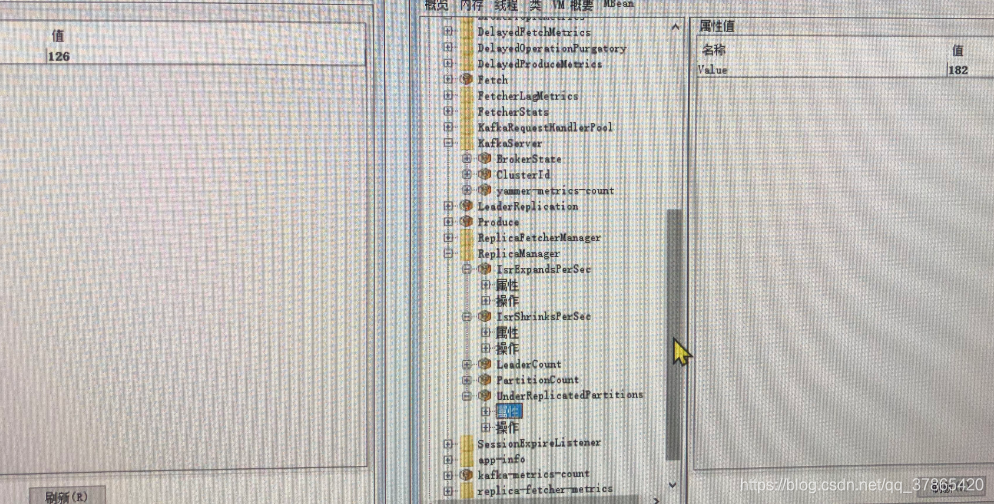
由JMX指标分析,IO请求(RequestHandlerAvgIdlePercent)空闲度还是极低,网络空闲度(NetworkProcessorAvgIdlePercent)很高。吞吐量非常高,ISR的缩扩还是有的,UnderReplicatedPartitions比较多(ISR缺失严重),RequestQueueSize为1000多,然而ResponseQueueSize竟然为1,说明响应慢(有什么东西让请求堵塞住了)
10、jstack分析确定原因
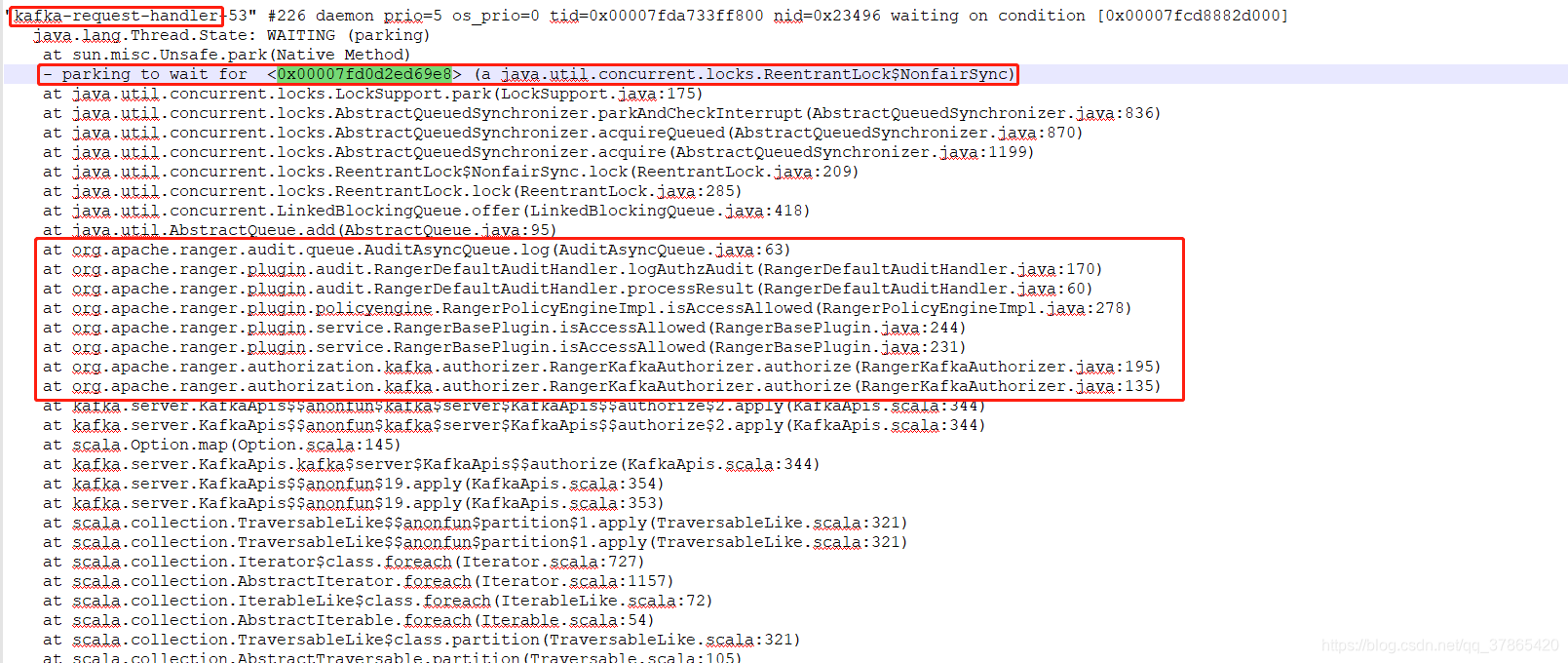
jstack看很多kafka-request-handler线程都在parking一个对象
然后发现,这是底下ranger在写审计日志,一条消息就要写一次
然后一天1k-2k亿条数据。。。就卡住了。
然后requestHandler线程都请求等待,
然后就影响ISR频繁expand,shrink。
11、解决办法
关闭kafka-ranger-plugin的写入audit日志功能,单单开启它的Authorization功能
此方案暂时进行了测试,测试通过,但是生产未验证,后续割接完成后再更新
所以大家以后用kerberos+ranger管理kafka认证授权,得注意了ranger这块了,ranger有点虎。。