本文基于JDK1.8详细介绍了LinkedHashMap的底层原理,它到底是如何保证元素有序的?同时讲解了基于访问时间的迭代顺序的原理,以及如何使用LinkedHashMap实现简单的LRU缓存!
文章目录
- 1 LinkedHashMap的概述
- 2 LinkedHashMap的源码解析
- 2.1 主要类属性
- 2.2 构造器
- 2.2.1 LinkedHashMap()
- 2.2.2 LinkedHashMap(initialCapacity)
- 2.2.3 public LinkedHashMap(initialCapacity, loadFactor)
- 2.2.4 LinkedHashMap(initialCapacity,loadFactor,accessOrder)
- 2.2.5 LinkedHashMap(m)
- 2.4 常见API方法
- 2.5 大链表与迭代顺序的维护
- 3 LinkedHashMap与LRU缓存
- 4 LinkedHashMap的总结
1 LinkedHashMap的概述
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
LinkedHashMap来自于JDK1.4,直接继承自 HashMap,在 HashMap 基础上,通过维护一张基于整个哈希表的大双链表,解决了HashMap遍历元素时无序的问题。
LinkedHashMap还能基于元素访问时间的先后顺序迭代元素,可用于实现简单的LRU缓存。LinkedHashMap的默认构造实现是按插入顺序迭代的。
由于继承了HashMap,LinkedHashMap 很多方法直接使用 HashMap的实现,仅为维护总双链表覆写了部分方法。所以,要彻底看懂 LinkedHashMap 的源码,需要先看懂 HashMap 的源码。
本文中涉及到的的父类HashMap的方法均没有解析,这些方法的源码分析在HashMap源码解析一文中:Java集合—HashMap的源码深度解析与应用,注意HashMap源码非常的多且非常复杂,谨慎观看!
2 LinkedHashMap的源码解析
LinkedHashMap的代码很少,主要是大部分方法直接使用的父类HashMap的代码,我们主要看LinkedHashMap自己的源码!
2.1 主要类属性
除了继承了HashMap的属性,比如size、table等,LinkedHashMap类中还增加了3个属性用于实现保证元素顺序,分别是双向链表头节点引用header,双向链表尾节点引用tail和 排序模式标志位accessOrder 。accessOrder值为true时,表示按照访问顺序模式迭代;值为false时,表示按照插入顺序模式迭代。
//用来指向双向链表的头节点
transient LinkedHashMap.Entry<K,V> head;
//用来指向双向链表的尾节点
transient LinkedHashMap.Entry<K,V> tail;
//排序方式:true:访问顺序迭代,false:插入顺序迭代。
final boolean accessOrder;
2.2 构造器
2.2.1 LinkedHashMap()
public LinkedHashMap()
默认无参构造器,构造一个带默认初始容量 (16) 和加载因子 (0.75) 的空LinkedHashMap 实例。除了调用父类无参构造器之外,还设置accessOrder=false,这表明使用插入顺序遍历元素!
public LinkedHashMap() {
//调用父类HashMap的无参构造器
super();
accessOrder = false;
}
2.2.2 LinkedHashMap(initialCapacity)
public LinkedHashMap(int initialCapacity)
构造一个带指定初始容量和默认加载因子 (0.75) 的LinkedHashMap 实例。除了调用父类相应的构造器之外,还设置accessOrder=false,这表明使用插入顺序遍历元素!

public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
2.2.3 public LinkedHashMap(initialCapacity, loadFactor)
构造一个带指定初始容量和加载因子的空插入顺序 LinkedHashMap 实例。除了调用父类相应的构造器之外,还设置accessOrder=false,这表明使用插入顺序遍历元素!
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
2.2.4 LinkedHashMap(initialCapacity,loadFactor,accessOrder)
构造一个带指定初始容量、加载因子和排序模式的空 LinkedHashMap 实例。
public LinkedHashMap(int initialCapacity,float loadFactor, boolean
accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
2.2.5 LinkedHashMap(m)
public LinkedHashMap(Map<? extends K,? extends V> m)
构造一个映射关系与指定映射相同的插入顺序 LinkedHashMap 实例。所创建的 LinkedHashMap 实例具有默认的加载因子 (0.75) 和足以容纳指定映射中映射关系的初始容量。设置accessOrder=false,这表明使用插入顺序遍历元素!
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
//调用父类的方法
putMapEntries(m, false);
}
2.4 常见API方法
LinkedHashMap的大部分方法的主体结构完全是使用的父类HashMap的方法。比如put、remove:
/**
* 父类HashMap实现的方法
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* 父类HashMap实现的方法
*/
public V remove(Object key) {
HashMap.Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
那么LinkedHashMap有没有自己的方法呢?当然有,并且还有一个特点,那就是这些方法和自己的三个属性有关,比如get、containsValue、clear方法等:
/**
* LinkedHashMap重写的get方法,增加了accessOrder的判断
*/
public V get(Object key) {
Node<K, V> e;
//调用父类的getNode方法,尝试查找key相同的节点
if ((e = getNode(hash(key), key)) == null)
return null;
//getNode找到节点之后通过判断标志位,来判断是否调用afterNodeAccess回调方法
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
/**
* LinkedHashMap重写的containsValue方法
* 我们知道,在父类中的containsValue方法实际上也是顺序遍历全部哈希表,由于子类LinkedHashMap将整个哈希表变成了一张大的链表
* 因此只需要遍历这一张大链表就行了!
*/
public boolean containsValue(Object value) {
/*循环大链表,尝试查找value相同的节点*/
for (LinkedHashMap.Entry<K, V> e = head; e != null; e = e.after) {
V v = e.value;
//判断value相同的要求是==返回true或者equals方法返回true
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
/**
* LinkedHashMap重写的clear方法,增加了大链表头尾节点head、tail置空的语句
*/
public void clear() {
//调用父类的clear方法
super.clear();
//自身维护的大链表头尾节点head、tail置空
head = tail = null;
}
2.5 大链表与迭代顺序的维护
这个大链表,就是我们所说的基于整张哈希表的链表,维护了LinkedHashMap的迭代顺序。
2.5.1 linkNodeLast方法
LinkedHashMap是通过linkNodeLast方法构建最初的大链表的,该方法是LinkedHashMap自己的方法:
/**
* 新节点链接到大链表末尾
*
* @param p 新节点
*/
private void linkNodeLast(LinkedHashMap.Entry<K, V> p) {
LinkedHashMap.Entry<K, V> last = tail;
//如果tail和head都为null,那么新添加第一个节点时,tail和head都指向该节点
tail = p;
if (last == null)
head = p;
/*否则,将新节点链接到大链表末尾,新节点成为新的tail节点*/
else {
p.before = last;
last.after = p;
}
}
很明显,新节点被链接到大链表末尾。该方法在newNode和newTreeNode方法中被调用到:
/**
* 在插入新普通节点时调用
*/
Node<K, V> newNode(int hash, K key, V value, Node<K, V> e) {
LinkedHashMap.Entry<K, V> p =
new LinkedHashMap.Entry<K, V>(hash, key, value, e);
//最终调用linkNodeLast将新节点链接到大链表末尾
linkNodeLast(p);
return p;
}
/**
* 在插入新红黑树节点时调用
*/
TreeNode<K, V> newTreeNode(int hash, K key, V value, Node<K, V> next) {
TreeNode<K, V> p = new TreeNode<K, V>(hash, key, value, next);
//最终调用linkNodeLast将新节点链接到大链表末尾
linkNodeLast(p);
return p;
}
上面的两个方法原本是父类的方法,在插入新节点时,用于创建新节点,LinkedHashMap对其进行了重写,主要是新增了linkNodeLast方法的调用,这样就维护了节点在大链表之中的关系!
2.5.2 afterNodeRemoval方法
上面讲了大链表节点的插入,自然可以删除,能想到,大链表节点的移除也是在remove方法被调用时一并进行的。
LinkedHashMap的remove方法和get方法一样,都是调用父类的方法,父类的删除方法并没有删除大链表节点之间的关系。可以想到,大链表的删除也是重写了某个私有方法,而父类的remove方法中调用了该方法来进行大链表节点的删除!
与大链表的创建不同,大链表节点的删除并没有自己实现方法,而是重写了父类的afterNodeRemoval方法,该方法在节点被成功移除之后调用。
/**
* 该方法在父类HashMap的removeNode方法中,在移除节点之后会被调用,但是HashMap是一个空实现
*
* @param p 被删除的节点
*/
void afterNodeRemoval(Node<K, V> p) {
}
/**
* 子类LinkedHashMap重写了afterNodeRemoval方法,用来实现删除大链表的节点
*
* @param e 被删除的节点
*/
void afterNodeRemoval(HashMap.Node<K, V> e) {
//p保存e,b是p在大链表中的前驱,a是p在大链表中的后继
LinkedHashMap.Entry<K, V> p =
(LinkedHashMap.Entry<K, V>) e, b = p.before, a = p.after;
//前驱后继置空
p.before = p.after = null;
//如果前驱为null
if (b == null)
//那么后继为大链表头节点
head = a;
else
//p的前驱的后继指向p的后继
b.after = a;
//如果后继为null
if (a == null)
//那么b为大链表尾节点
tail = b;
else
//p的后继的前驱指向p的前驱
a.before = b;
}
2.5.3 afterNodeAccess方法
LinkedHashMap维护了两种迭代顺序,一种是插入迭代顺序,一种是访问迭代顺序,它们是通过标志位accessOrder区分的,accessOrder在构造LinkedHashMap时就设置了值,默认是false,即元素插入顺序,也可以手动设置为true,即元素访问顺序。
我们知道LinkedHashMap使用一张大链表串联起整个哈希表来维护迭代顺序,那么具体怎么实现的呢?在上面的大链表的构建和删除的源码看起来,似乎仅仅是元素插入的顺序,并且也没有使用到accessOrder标志,那么具体怎么实现访问顺序迭代的呢?
实际上,迭代顺序的实现主要是和afterNodeAccess方法有关!
afterNodeAccess方法会在一个元素节点被访问到时被调用,但是HashMap只提供一个空实现。比如put、replace、merge、get等方法,注意一定是在节点被访问到之后调用,比如get查找某个节点,没有找到的话是不会调用的!
LinkedHashMap 中覆写了afterNodeAccess方法。在LinkedHashMap的重写中,当一个节点被访问时,如果 accessOrder 为 true,则会将该节点移到链表尾部。也就是说指定为 LRU 顺序之后,在每次访问一个节点时,会将这个节点移到链表尾部,保证链表尾部是最近最新访问的节点,那么链表首部就是最远最久未使用的节点。
/**
* 在元素被访问时,会调用afterNodeAccess方法,HashMap中的方法为空实现
*
* @param p 被访问的节点
*/
void afterNodeAccess(Node<K, V> p) {
}
/**
* LinkedHashMap 中重写的afterNodeAccess方法,用于将被访问到的节点移动到大链表末尾
*
* @param e 被访问的节点
*/
void afterNodeAccess(Node<K, V> e) { // move node to last
LinkedHashMap.Entry<K, V> last;
/*如果e不是尾节点,那么尝试移动e到尾部*/
if (accessOrder && (last = tail) != e) {
//p记录e,b保存p在大链表中的前驱,a保存p在大链表中的后继
LinkedHashMap.Entry<K, V> p =
(LinkedHashMap.Entry<K, V>) e, b = p.before, a = p.after;
//p的后继置空
p.after = null;
//如果b为null,表明p为头节点
if (b == null)
//头节点设置为p的后继a
head = a;
else
//否则b的后继设置为a
b.after = a;
/*如果a不为null,a的前驱设置为b*/
if (a != null) {
a.before = b;
}
/*否则,尾节点设置为b*/
else {
last = b;
}
//如果,last为null
if (last == null)
//那么头节点指向p
head = p;
else {
/*否则,将p链接在链表的最后*/
p.before = last;
last.after = p;
}
//尾节点指向p
tail = p;
++modCount;
}
}
3 LinkedHashMap与LRU缓存
LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:
- 新数据插入到链表头/尾部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头/尾部;
- 指定LRU缓存的容量,当链表长度大于容量时,将链表头/尾部的数据丢弃。
我们的LinkedHashMap已经提供了基于访问顺序的迭代机制,最近被访问的节点在尾部,最远被访问的节点在头部.那么自然可以实现LRU缓存,当然它的实现和下面这两个方法有关。
3.1 afterNodeInsertion方法
在插入元素操作之后,不光会调用linkNodeLast方法,在成功插入节点的情况下,在最后还会调用afterNodeInsertion方法,并传递evict=true(构造器中插入节点是传递evict=false)。同样HashMap同样只提供一个空实现。
比如put方法,存在两个情况,一种是替换value,一种是插入新节点,如果替换value,那么肯定访问到了某个节点,此时调用afterNodeAccess,如果是插入新节点,那么肯定是调用afterNodeInsertion方法,这两个方法不可能同时调用!
在LinkedHashMap重写的实现中,当内部的removeEldestEntry()方法返回 true 时会移除最远最久未访问的节点,也就是链表首部节点 head。evict 只有在构建 Map 的时候才为 false,在单独调用方法时为 true。
这个方法在插入节点之后调用,明显是因为LUR缓存容量有限制,新插入节点之后有可能需要移除最远最久未访问的节点。
/**
* HashMap提供的空实现
*
* @param evict 构造器中传递false,单独调用方法传递true
*/
void afterNodeInsertion(boolean evict) {
}
/**
* LinkedHashMap重写的实现
*
* @param evict 构造器中传递false,单独调用方法传递true
*/
void afterNodeInsertion(boolean evict) {
LinkedHashMap.Entry<K, V> first;
//如果evict为true,并且大链表头节点不为null,并且removeEldestEntry(first)方法返回true
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
//那么调用removeNode移除头节点,这一移除方法中具有afterNodeRemoval方法
removeNode(hash(key), key, null, false, true);
}
}
3.2 removeEldestEntry方法
我们看到afterNodeInsertion方法内部调用了removeEldestEntry方法并以返回值作为是否需要移除头节点的判断条件之一。
removeEldestEntry方法是LinkedHashMap 自己的方法,并且还是一个抽象方法。 默认返回false,如果需要让它返回true或者根据代码返回,需要继承 LinkedHashMap 并且覆盖这个方法的实现。
该方法在实现 LRU 的缓存中特别有用,在该方法中可以设置缓存容量,然后比较节点总数和缓存容量的大小,当节点总数超过缓存容量时可以返回true(因为新增节点成功之后会调用afterNodeInsertion方法),然后通过移除最近最久未使用的节点(头节点),从而保证缓存空间足够,并且缓存的数据都是热点数据。
/**
* 移除最近最少被访问条件之一,通过覆盖此抽象方法可实现不同策略的缓存
*
* @param eldest 大链表头节点
* @return true,移除 false,不移除
*/
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return false;
}
3.3 LRU缓存实现案例
当我们基于 LinkedHashMap实现缓存时,通过继承LinkedHashMap并且覆写removeEldestEntry方法,再构造对象是设置accessOrder为true,可以实现自定义策略的 LRU 缓存。比如我们可以根据节点数量判断是否移除最近最少被访问的节点,或者根据节点的存活时间判断是否移除该节点等。
案例:
/**
* 简单的LRU缓存,通过继承LinkedHashMap来实现
*/
class LRUCache<K, V> extends LinkedHashMap<K, V> {
/**
* 缓存容量
*/
private int maxEntries;
/**
* 构造器
*
* @param maxEntries 最大容量
*/
LRUCache(Integer maxEntries) {
//调用父类构造器
super(maxEntries, 0.75f, true);
this.maxEntries = maxEntries;
}
/**
* 通过重写removeEldestEntry方法,加入一定的条件,满足条件返回true。
*
* @param eldest 大链表头节点
* @return true,表示允许移除头节点;false,表示不允许移除头节点
*/
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
//如果节点数量大于LRU缓存容量,那么返回true
return size() > maxEntries;
}
/**
* 测试
*/
public static void main(String[] args) {
//新建LRUCache,容量为5,首先循环存放十次
LRUCache<Integer, Integer> cache = new LRUCache<>(5);
for (int i = 0; i < 10; i++) {
cache.put(i, i * i);
}
System.out.println("调用10次插入方法后,缓存的内容======>");
System.out.println(cache + "\n");
System.out.println("访问键为7的节点后,缓存内容======>");
cache.get(7);
System.out.println(cache + "\n");
System.out.println("访问键为1的节点后,缓存内容======>");
cache.get(1);
System.out.println(cache + "\n");
System.out.println("插入键值为1的键值对后,缓存内容======>");
cache.put(1, 1);
System.out.println(cache);
System.out.println("删除键为6的键值对后,缓存内容:");
cache.remove(6);
System.out.println(cache);
System.out.println("插入键值为7的键值对后,缓存内容:");
cache.put(7, 7);
System.out.println(cache);
}
}
4 LinkedHashMap的总结
LinkedHashMap底层基于整个HashMap的哈希表维护了一张大链表,保证了所有元素的迭代顺序,可以是插入顺序,也可以是访问顺序。有了对LinkedHashMap和HashMap源码的认识,我们可以画出LinkedHashMap的大概结构图:
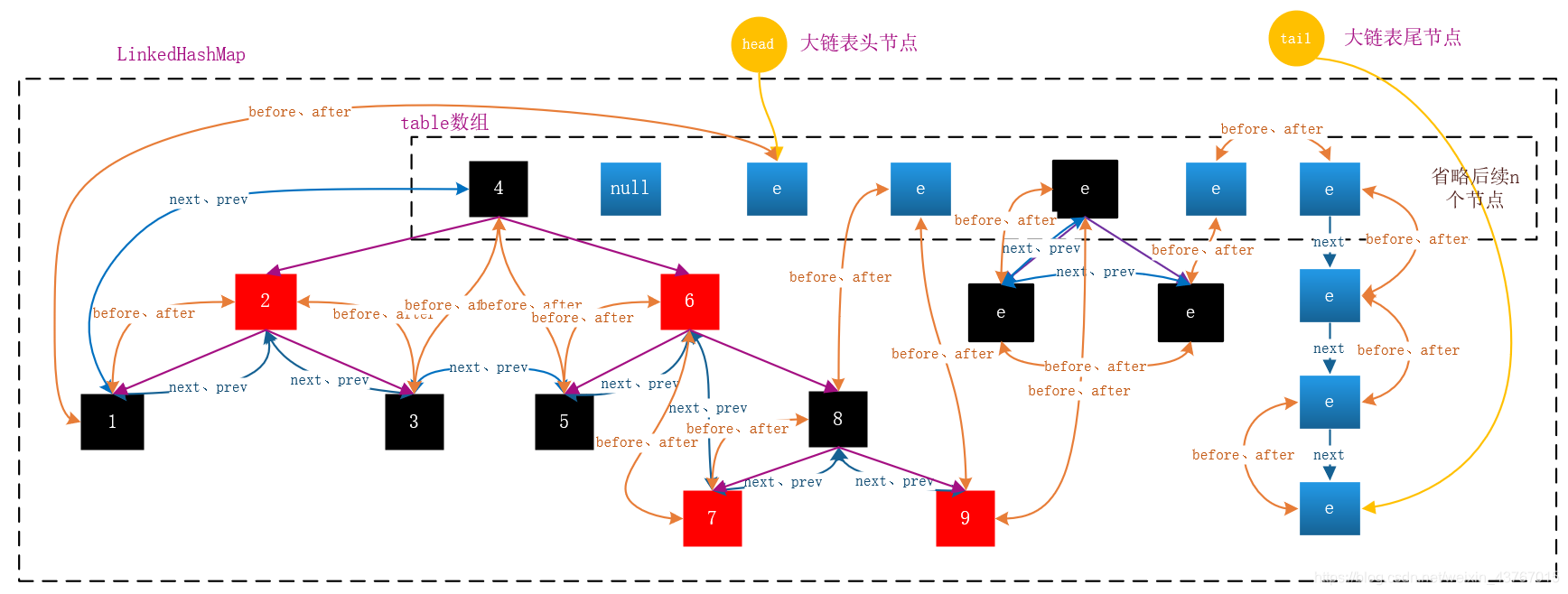
看完这篇文章,是不是觉得LinkedHashMap挺简单的?其实那是因为最底层、最关键的方法实现都在HashMap中实现了,如果你想挑战一下自己,可以去看一看HashMap的源码,那应该比本文略有难度:Java集合—HashMap的源码深度解析与应用。
如果有什么不懂或者需要交流,可以留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!