1 介绍
本文基于《Rich feature hierarchies for accurate object detection and semantic segmentation》翻译总结,该文论述了R-CNN。
最近10年,关于各种不同的视觉识别任务主要是基于SIFT和HOG。SIFT和HOG是块方向直方图。在R-CNN之前,物体识别停滞了几年。我们是结合了region proposals和CNNs,故取名R-CNN:Regions with CNN features。我们的方法有两个关键点:(1)将高容量的卷积神经网络应用于自底向上的region proposals,以定位和分割物体;(2)当标签的训练数据不足时,辅助任务的监督预训练,进行特别领域的微调,可以产生显著的性能提升。
不像图片分类,物体检测需要在一个图片中定位物体。一种方法是将定位作为一个回归问题,但不是非常成功;另一种方法是建立滑窗检测器,我们采用的此方法,有5个卷积层,非常大的视野(195195 pixels)和步长(3232 pixels)。
网络结构如下图。对于输入图片,我们方法产生2000个分类独立的region proposals,从每一个proposal中使用CNN提取一个固定长度的feature vector,然后使用类别特定的线性SVM对每一个region进行分类。忽略region的形状,从每一个region proposal 计算固定大小的CNN输入。

2 R-CNN 物体识别
我们的物体识别系统包括3个模块。第一个模块是生成分类独立的region proposal。这些proposals 定义了候选识别物的set集合。第二个模块是一个大的卷积神经网络,其从每个region提取固定长度的特征vector。第三个模块是特定类别的线性SVMs的set集合。
2.1 模块设计
特征提取:从每个region提取一个4096维的特征向量。前向传输一个重新组合的227*227 RGB图片,使其通过5个卷积层和两个全连接层,来计算特征。
为了计算一个region proposal 的特征,我们必须将该region的图片数据转换成兼容CNN的形式(CNN的输入是227*227 pixel)。不考虑region的大小与纵横比,我们使紧凑的bounding box中的所有像素变形到要求的固定大小。下图展示了一些变形后的regions。

2.2 测试时间检测
我们在测试图片提取2000左右个region proposals,然后变形每一个proposal,前向传输它使其通过CNN,来计算特征。然后对于每个分类,我们使用SVM计算每个提取的特征向量的得分。给定一个图片的所有得分regions,我们对于每一个独立分类采用贪婪非最大抑制,即如果一个region和一个高得分region有 IoU(intersection-over-union) 重叠,其比学习的阈值大,那么就拒绝该region。
运行时间分析:两个特点使检测运行效率高,第一个是所有的CNN参数在所有类别间共享,第二是CNN计算的特征向量是低维的,4K维。
特征矩阵是20004096,SVM权重矩阵是4096N,其中N是类型数量。

2.3 训练
监督预训练:我们在一个大的附加数据集(ILSVRC2012 classification)上使用图片水平的标注(没有bounding box 标签)预训练CNN。
**特定领域微调:**为了使我们的CNN适用于新任务(识别)和新领域(变形的proposal windows),我们仅使用变形的region proposals继续进行CNN 参数的SGD(stochastic gradient descent)训练。除了将CNN 的imageNet-specific 1000-way 分类层用一个随机初始化的N+1 way 分类层替换外,CNN结构没有变化。其中N指物体类别的数量,额外加1是为了背景。对于VOC,N=20;对于ILSVRC2013,N=200。我们将与ground-truth box有 >=0.5 IoU overlap 的所有region proposals视为对于box分类积极的,其他为消极的。我们开始SGD以0.001的学习率。在每个SGD迭代中,统一采样32个 positive windows和96个 background windows,构成大小为128的mini-batch。我们偏向采样positive窗口,因为与背景相比,它们极为罕见。
物体类别分类:我们设定一个 IoU overlap 阈值,在阈值之下的定义为negative 样本。Positive 样本定义为每个分类的ground-truth bounding boxes。
因为训练数据太大,不适合在内存中,所有我们采用standard hard negative mining方法。hard negative mining能快速收敛,实际上mAP在遍历一次所有图片后就停止增长。
2.4 网络结构
网络结构对R-CNN识别效果有很大的影响,如下表,T-NET 和O-NET的结果有差异。

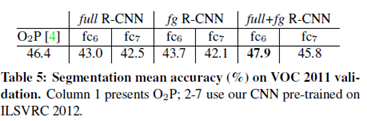
3 语义分割
CNN 特征语义分割:我们评估了三种策略。第一种策略(full)不考虑region的形状,直接在变形后的window上计算CNN 特征。但是这些特征忽略了region的非矩形形状。这两种region有相似的bounding box,但却有非常小的overlap。第二种策略(fg)仅仅在region 的foreground mask上计算CNN 特征。我们用平均的输入替换background,以致于background regions在平均相减后是0。第三种是full+fg,简单连接full和fg的特征。实验结果如下: