均值方差模型(Markowitz Mean-Variance Model)
1952 年,马柯维茨发表了《证券组合选择》,建立起现代投资组合理论的框架。马科维茨认为,投资者可以用预期收益率
,以及收益率的标准差 来完全构建和衡量一个投资组合,因此,该模型又称为均值-方差模型。依据他的观点,对于一个资产数目为
,且各资产头寸相同的投资组合,如果已知每一个资产收益率的方差
和资产两两之间的协方差
,则我们可以计算这个投资组合的方差:
对于包含
个资产的投资组合,我们需要计算
个协方差,通常以协方差矩阵来表示:
此时,资产的协方差矩阵包含了我们投资组合的一切风险信息。在实际计算中,我们需要通过历史数据来计算经验协方差矩阵 (empirical covariance matrix),作为协方差矩阵的估计。然而,使用经验协方差矩阵存在以下问题:
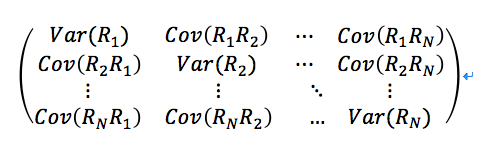
(1)数据量要求大。要对协方差矩阵实现较为准确的估计,需要保证观测值数目大于矩阵的维数。考虑以沪深 300 的 300 个成分股作为投资组合,以月度数据计算经验协方差矩阵,则需要至少 300/12 = 25 年的数据,因此缺乏现实可行性;
(2)依据历史数据进行协方差估计无法反映投资组合中资产的结构性变化(例如并购);
(3)大量资产两两之间的协方差计算,容易出现多重比较谬误(multiple comparison fallacy)的问题,因而引起资产之间相关性的错误判断。
(4)历史数据中包含大量的噪音,因此简单使用资产的协方差矩阵进行预测会造成较大的偏差。
结构化风险模型 (Structural Risk Model, SRM)
针对以上用资产的协方差矩阵来衡量投资组合风险所存在的缺陷,国际著名的投资组合表现分析研究机构 MSCI Barra 使用结构化风险模型(也称多因子模型,以下简称 SRM)来衡量投资组合的表现和风险。其核心思想是,我们可以选取一系列公共因子(common factors)和特异因子(idiosyncratic factors)来描述一个投资组合的风险。常用的公共因子有所属行业,成长性,市盈率等,特异因子则是和公共因子相对的概念,用于解释每个资产的收益率中不能用公共因子解释的部分。
设因子个数为
,资产个数为
,窗口大小为
投资组合的收益率
资产的头寸
因子暴露(factor exposure)矩阵
因子收益率
特异因子(idiosyncratic factors)收益率
其线性关系为
另外,SRM 给出了以下的两个假设:
1.对于同一个资产 i,因子收益率和特异收益率不存在线性相关,
2.对于两个不同的资产 i 和 j,它们的特异收益率也不存在线性相关,
基于这两个假设,我们可以推导出 SRM 的投资组合风险表达式:
其中 为投资组合收益率的标准差, 为因子收益率的协方差矩阵。 和 分别为权重向量和特异因子收益率方差矩阵。
上述两个表达式即为结构化风险模型的核心。虽然它们的形式上稍显复杂,但它们的意义是明确的:投资组合的风险可以用因子收益率的协方差矩阵,而非投资组合中资产的收益率的协方差矩阵来描述。从数据处理的角度来看,SRM是一种数据降维技术。因此,它具有数据降维通常的优点:
(1)去除数据中的噪音;
(2)它能够大大减少计算量,因此也降低了出现多重比较谬误的可能性。例如,一个包含 500 个资产的投资组合,如果要构建其相关系数矩阵,则需要计算 500*(500-1)/2 = 124,750 个相关系数,如果选用 50 个因子的相关系数来描述,则只需要计算 50*(50-1)/2 = 1225 个相关系数;
(3)因子的统计量通常比资产的统计量有更好的稳定性,因此基于SRM能给出更精确的长期预测;
(4)因子暴露度的调整可以捕捉资产的结构性变化;
(5)因子本身有清晰的经济学涵义,在对 SRM 的因子进行筛选的过程中,也会加深我们对于投资组合风险来源的认识。