使用Python爬取全球新冠肺炎疫情数据
导入所需库包
获取实时数据的url
正式编写程序
查看输出结果
导入所需库包
在获取数据之前,我们需要先安装好所需的包requests和pandas:
1.如果是使用pycharm可以直接使用File->Settings->Project->Project Interpreter->选择“+”->在搜索栏内输入需要下载的包
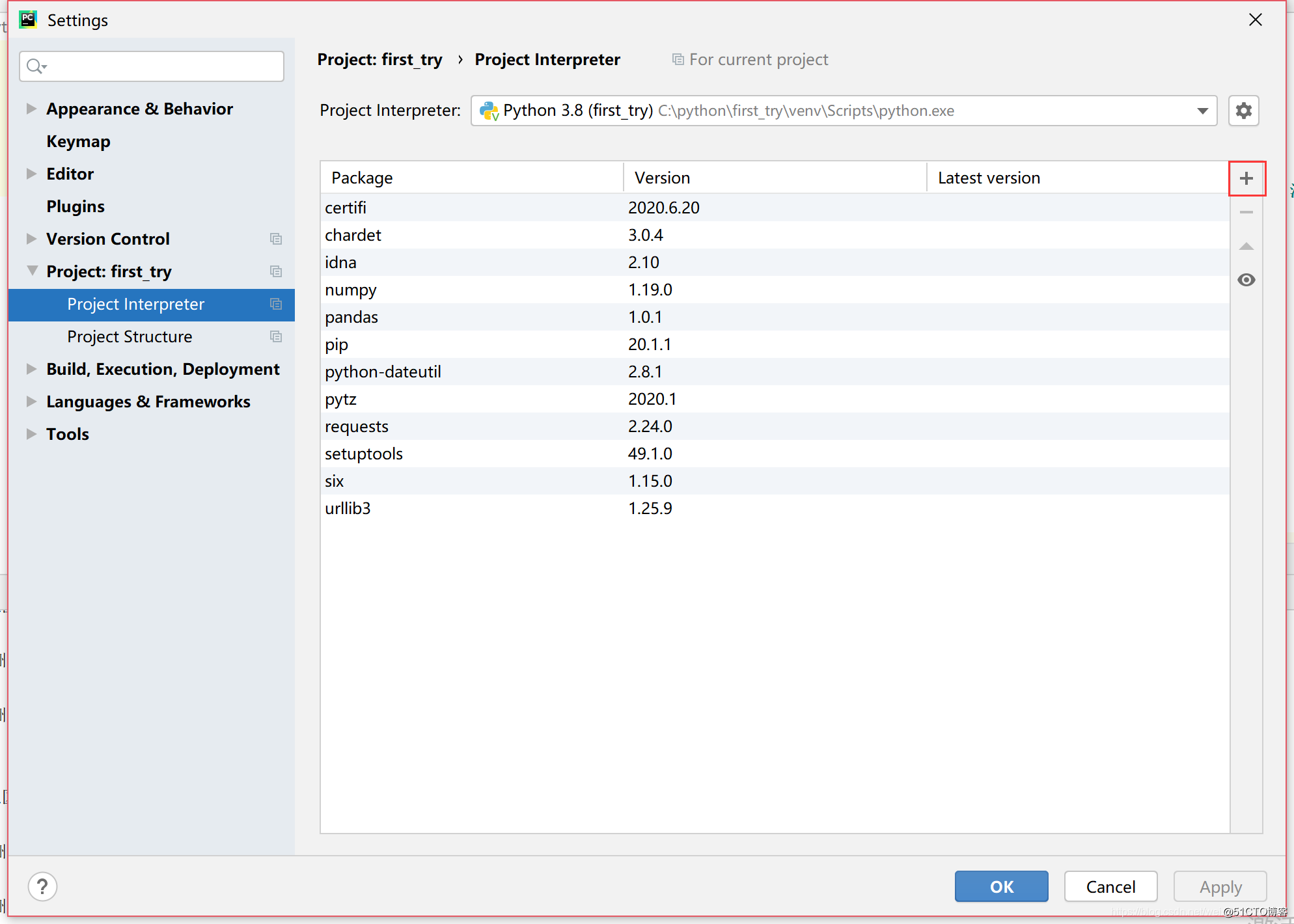
在这里我已经安装好了pandas和requests,但需要注意的是在安装pandas是系统会自动下载好另外两个包python-dateutil和numpy,这里面我们不用去管他。
出错的看这里!
当时我以为已经下好了pandas但是在敲代码时候又报错了,解决方法如下: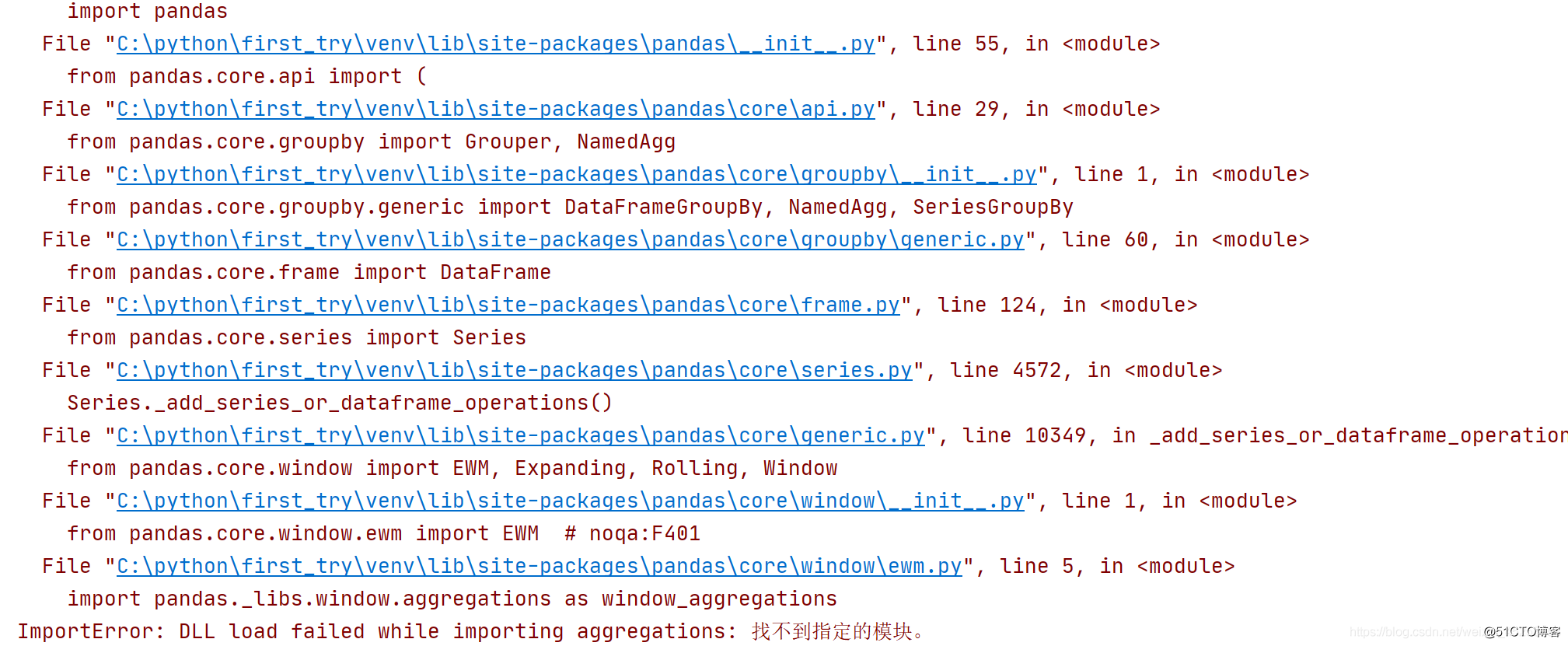
出现这个问题其实是pandas版本和python版本不兼容,我又换了一个版本pandas1.0.1就可以了。我们需要先将pandas删除,在点击加号在下面有一个,如图,将版本降下来就可以啦。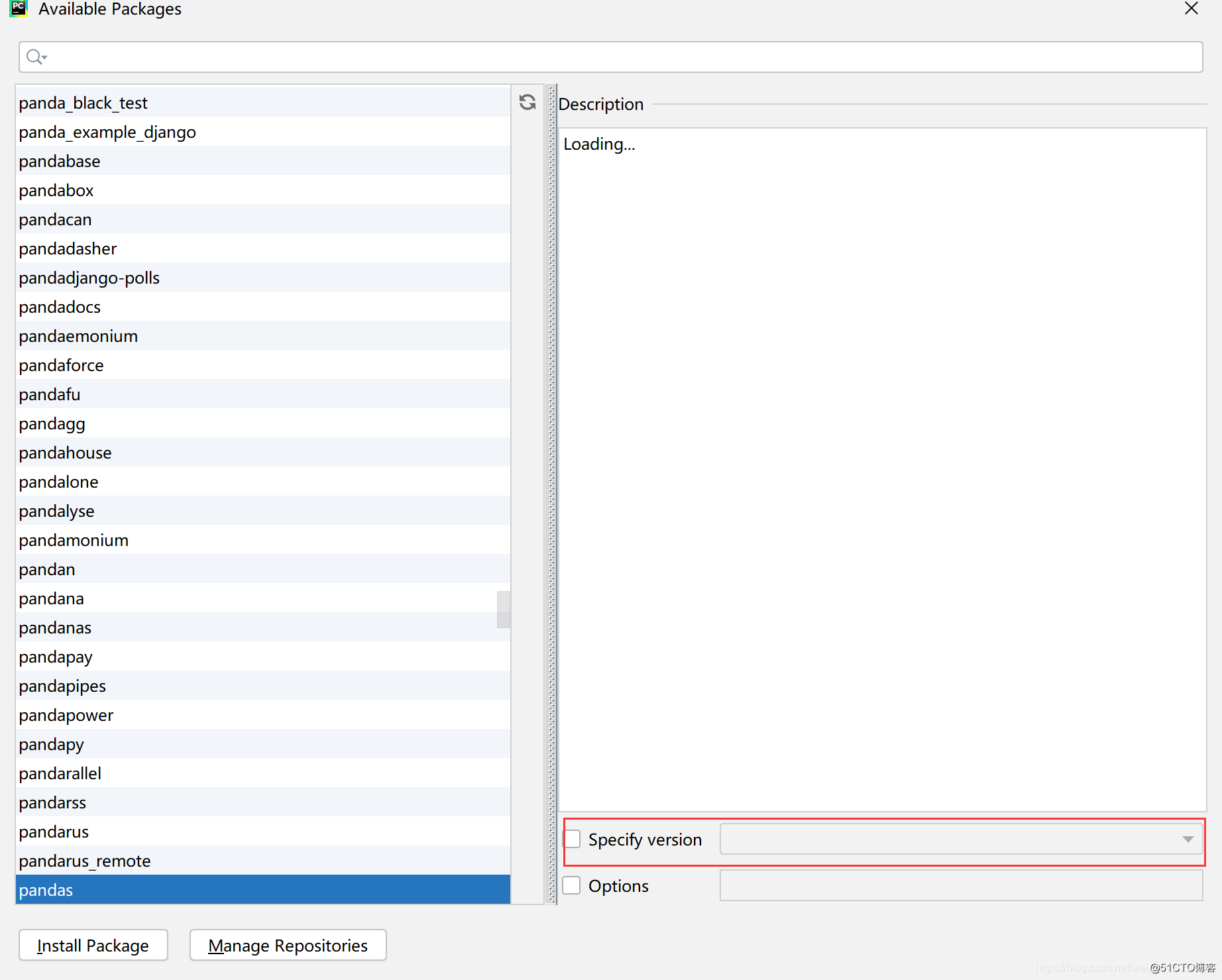
2.如果使用cmd去装python包也可以,只需要找好路径:
先找到当时的下载位置
(这是我电脑中的安装位置,打开到Scripts这个文件夹)
(速度比较慢,当时我下的时候只有4KB,不知道为什么这么慢)
C:\Users\A\AppData\Local\Programs\Python\Python38\Scripts
cd C:\Users\A\AppData\Local\Programs\Python\Python38\Scripts
pip install pandas
pip install requests
如果你之前装过但是由于各种原因,一定要先把他删掉
pip unstall pandas 再重新操作。
获取实时数据的url
在获取的时候,最好选用火狐浏览器,我这里用的是火狐,因为都是中文的,找起来比较方便。
现在在浏览器上复制下面的链接,点击右键检查元素
https://news.qq.com/zt2020/page/feiyan.htm#/global?pool=bj
与我们之前查找字段的方式不同,因为动态数据只能在json能够找到,只是查看代码是不够的。我们需要用另一种方式专门适用于爬取动态数据。
找到“网络”,并刷新一下,就会发现ranklist,双击点进去,我们就能看到一个动态数据列表,下面的任务就是根据url按照字段写进去。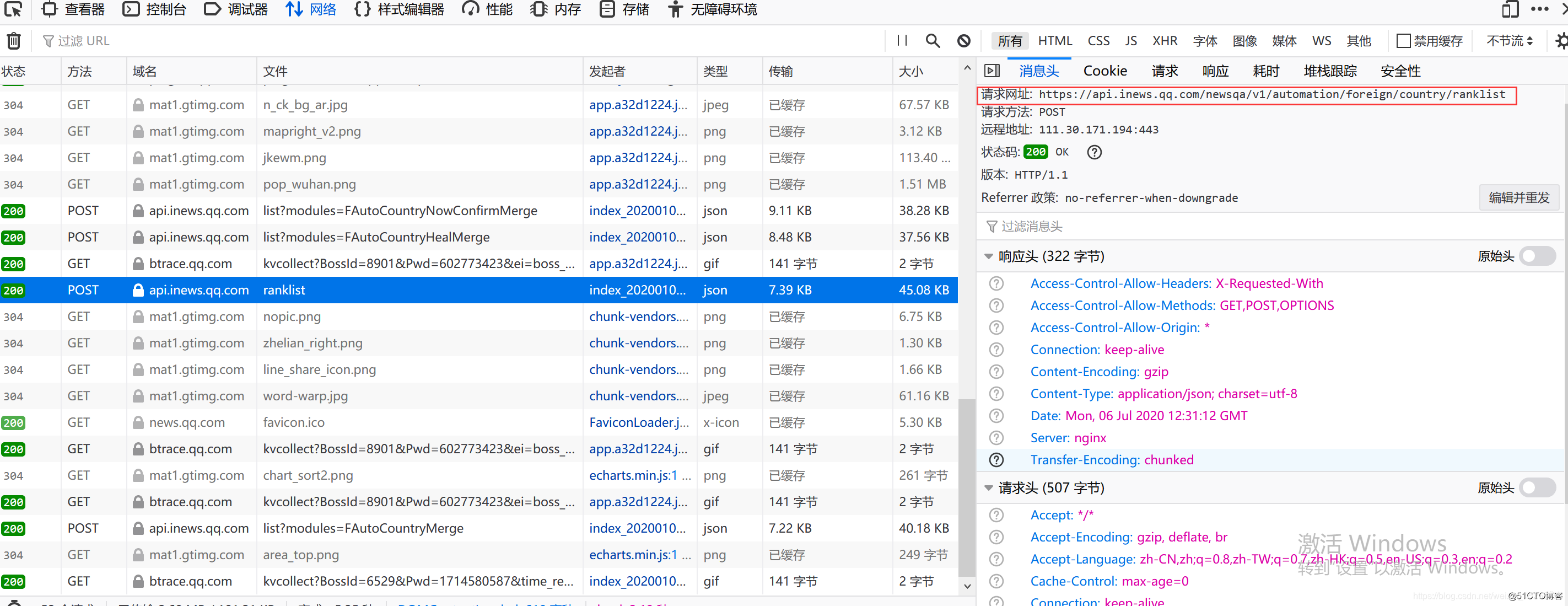
正式编写程序
将ranklist的请求地址复制下来,之后就可以开始编写我们的python程序了。
import requestsimport jsonimport pandas as pd//将pandas包用别名pd表示
url='https://api.inews.qq.com/newsqa/v1/automation/foreign/country/ranklist'//刚才复制的url地址
r=requests.get(url)//用requests获取地址
content=json.loads(r.text)//将所有json数据转化为数据字典的形式123456这个时候可以在屏幕中看到获取来的数据,使用一行代码print(content)print(type(content))//我们也可以查看它现在的数据类型<dict>就代表数据字典的形式12
下面我们对数据进行处理。每一列的顺序可以随便写,但一定要队形数组下标的字段,我们能在响应里面找到json数组的相应字段。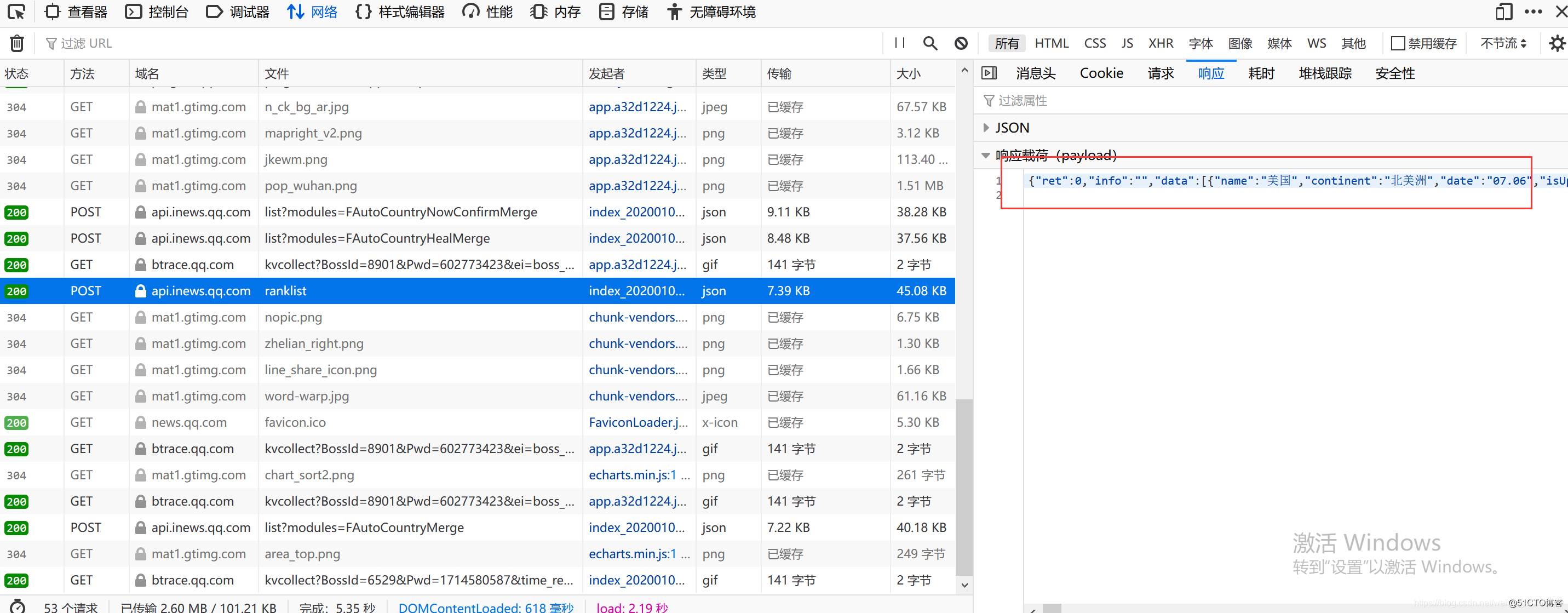
df=pd.DataFrame(columns=['国家和地区','所属洲','日期','今日新增病例','确诊人数','疑似病例','死亡病例','治愈病例'])for i in range(len(content['data'])):
df.loc[i+1]=[content['data'][i]['name'],
content['data'][i]['continent'],
content['data'][i]['date'],
content['data'][i]['confirmAdd'],
content['data'][i]['confirm'],
content['data'][i]['suspect'],
content['data'][i]['dead'],
content['data'][i]['heal']]12345678910由于数据量非常的大,我们也可以字段关键字查找,代码如下:
print(df[0:1])
df2=df[df['国家和地区'].isin(['新加坡'])]
print(df2)123查看输出结果
当前我只在控制屏中进行输出,当然也可以把他保存到csv中,下面是运行截图: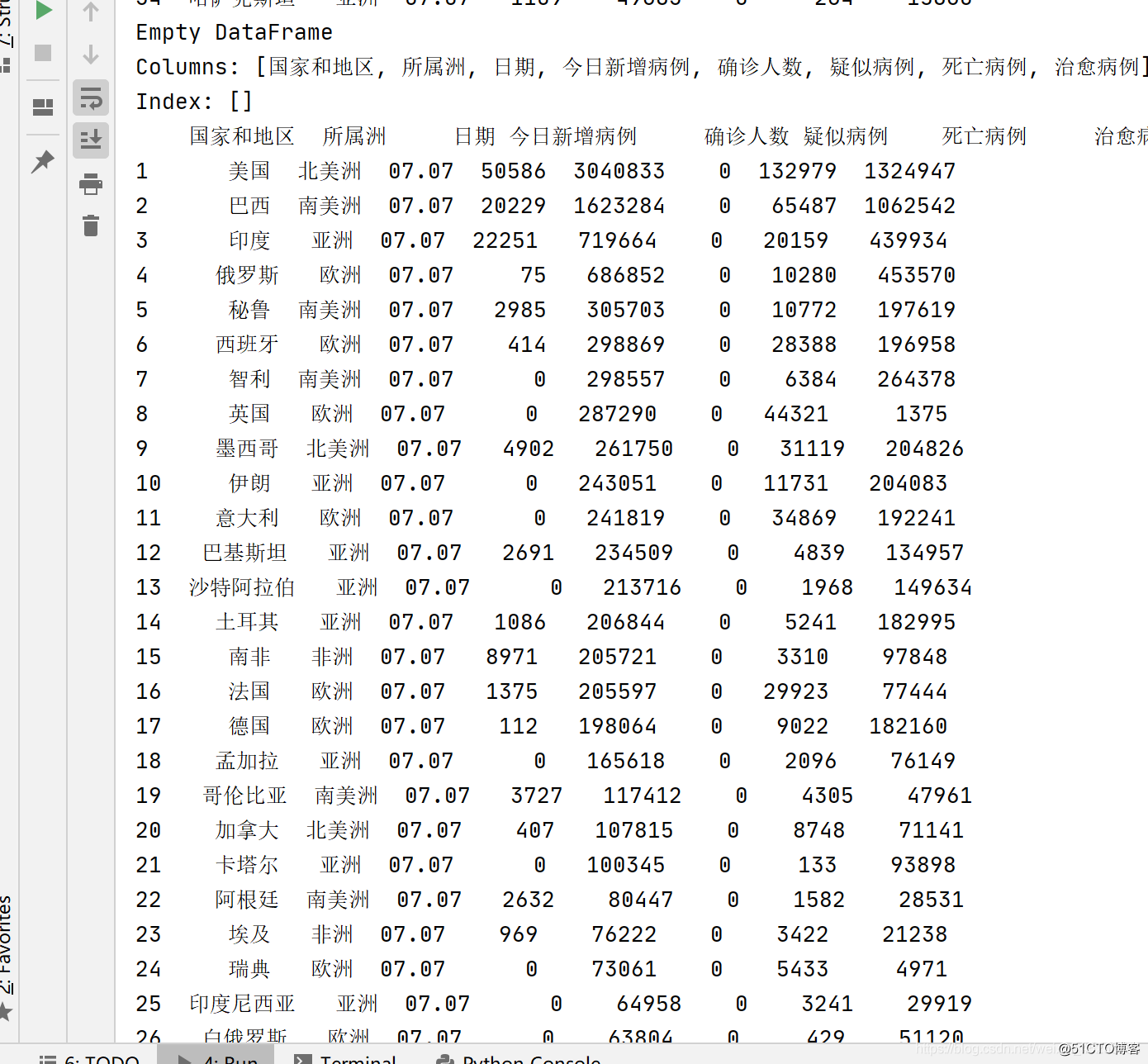
这样子一个简单的动态数据爬取就完成了,有没有感觉很容易呢?