Python的re模块,正则表达式
#导入re模块
import re
1、match方法的使用:
result = re.match(正则表达式,待匹配的字符串)
正则表达式写法:
第一部分:
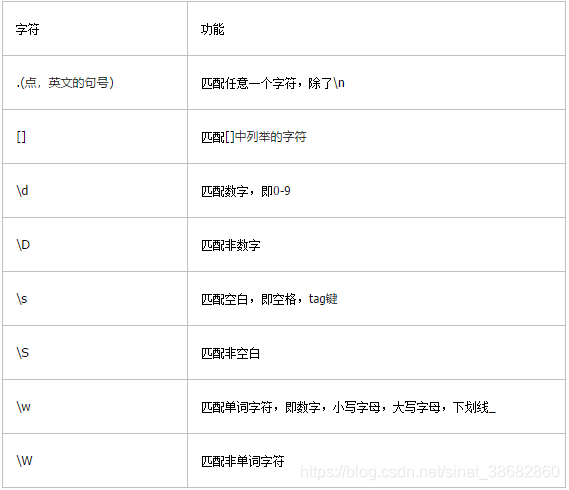
举例:
>>> re.match(".","&and") #.匹配任意字符,除了\n,只要第一个匹配,后面的and都是无所谓了,match方法就是这样定义的。从字符串最左边开始匹配,只要都匹配正则表达式,字符串后面的多余部分可以随意
<_sre.SRE_Match object; span=(0, 1), match='&'> #匹配到就有返回值,match是匹配到的具体内容,即 给一个.匹配了最左边的第一个字符&。
>>> re.match(".","\n") #不匹配,就返回None
>>> re.match("[1234][a-z][A-Z]\d","1aZ9") #正则表达式的意思是第一个字符要满足在1-4范围内,第二个字符是小写字母a-z,第三个字符是大写字符A-Z,第四个字符是数字,后面的字符串刚好满足,所以返回了下面这串值。这里同样的1aZ9匹配,1aZ9#@@¥%¥也是匹配的。
<_sre.SRE_Match object; span=(0, 4), match='1aZ9'>
>> re.match("\w\W","a%224") #第一个匹配单词字符,第二个匹配非单词字符,后面的无所谓
<_sre.SRE_Match object; span=(0, 2), match='a%'>
>>> re.match("\w\W","ab")
第二部分,个数相关:
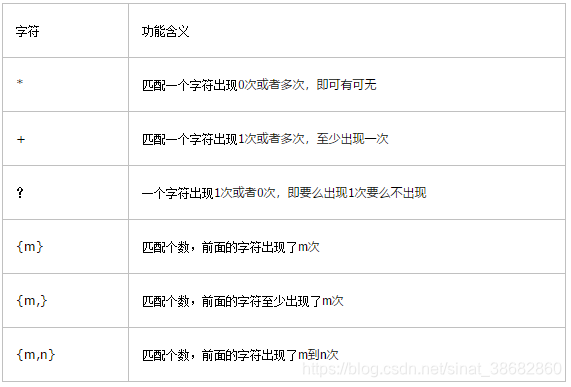
举例:
>>> re.match("\d*","1234aa") #\d出现了0次或者多次
<_sre.SRE_Match object; span=(0, 4), match='1234'> #匹配到的是1234
>>> re.match("\d*","abd")
<_sre.SRE_Match object; span=(0, 0), match=''> #匹配到空字符
>>> re.match("\d+","abd") #匹配不到,因为+意思是必须至少出现1次
>>> re.match("\d{11}","18510666666") #数字匹配11个
<_sre.SRE_Match object; span=(0, 11), match='18510666666'>
# 匹配手机号,分析:手机号第一个数字必须为1,第二个数字应该是3、4、5、8、9,第3个到第11个是任意数字,所以为:\d{9},表示9个数字,然后只能有11个数字,所以9个数字的后面加$表示匹配结束,只能匹配前面的11个数字
res = re.match(r"1[34589]\d{9}$", "13511111111")
>>> re.match("1[34589]\d{9}","12000000000") #第2个数字不满足,不匹配
>>> re.match("1[34589]\d{9}","13000000000r") #满足,匹配
<_sre.SRE_Match object; span=(0, 11), match='13000000000'>
第三部分,边界相关:

还是上面的例子,匹配手机号:
>>> re.match("1[34589]\d{9}","13000000000r") #满足,匹配
上面这个正则表达式是匹配的,但是显然不对,手机号后面不应该有字母,怎么解决呢?在写完的正则表达式后加$即可
>>> re.match("1[34589]\d{9}$","13000000000r") #不满足,不匹配
如果要匹配一个:D:\python\test,怎么办?
>>> re.match("D:\\python\\test","D:\\python\\test") #这样写是不对的,python会把\解析为转义字符,如何能避免呢,下面这样写,在正则表达式的前面加r:
>>> re.match(r"D:\\python\\test","D:\\python\\test")
<_sre.SRE_Match object; span=(0, 14), match='D:\\python\\test'>
Ps:推荐每当写正则表达式的时候,不管后面有没有转义字符,都加r
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
re.match(r"^.+ve\B","ho ver") #\B表示前面的字符e不在边界
<_sre.SRE_Match object; span=(0, 5), match='ho ve'>
>>> re.match(r"^.+ve\b","ho ve r")
<_sre.SRE_Match object; span=(0, 5), match='ho ve'>
>>> re.match(r"\w+\b\s+\w+\b\s+\w+\b","I love python")
<_sre.SRE_Match object; span=(0, 13), match='I love python'>
|管道符,逻辑或符号,在正则表达式中一样表示或,即匹配|符号两边的任意一个表达式都可以
比如,匹配0-100的数字:
#分析:第一个|符号前面的表达式是0,匹配0,第二个是100,第三个是匹配两位数字或者1位数字,第一位数字是1-9,第2位数字是0-9,?意思是可以有可以没有。
re.match(r"0|100|[1-9][\d?]$","90")
<_sre.SRE_Match object; span=(0, 2), match='90'>
>>> re.match(r"0|100|[1-9][\d?]$","0")
<_sre.SRE_Match object; span=(0, 1), match='0'>
完善后:
>>> re.match(r"[1-9]?\d$|100","0") #0匹配了第二个\d$
<_sre.SRE_Match object; span=(0, 1), match='0'>
第四部分,分组:
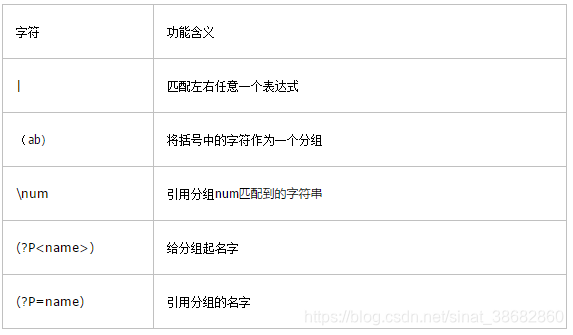
举例:
#定义一个字符串s
S=”<html><body><p>python</p></body></html>”
匹配上述的字符串,正则表达式如何写?
分析:第一个< html>跟最后一个< /html>是一对,内容是一样的只是后面多了一个/,同理中间也是如此,这个时候可以使用分组的思想
先使用不分组的思想匹配:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
res = r"<.+><.+><.+>.+</.+></.+></.+>"
>>> re.match(res,s)
<_sre.SRE_Match object; span=(0, 39), match='<html><body><p>python</p></body></html>'>
可以匹配到,然后使用分组思想,很简单,就是将<>里面的内容用()包起来,然后后面使用索引:
>>> res = r"<(.+)><(.+)><(.+)>.+</\3></\2></\1>"
>>> re.match(res,s)
<_sre.SRE_Match object; span=(0, 39), match='<html><body><p>python</p></body></html>'>
分析:第一个(.+)是分组的第一个索引,匹配到的内容是html,你希望最后一个<>内也是这个值,那么就在最后的位置,写\1表示匹配第一个分组的内容
有时分组内容太多,用索引会有可能乱掉,就可以使用起别名的方式,如下:
>>> res = r"<(?P<key1>.+)><(?P<key2>.+)><(?P<key3>.+)>.+</(?P=key3)></(?P=key2)></(?P=key1)>"
>>> re.match(res,s)
<_sre.SRE_Match object; span=(0, 39), match='<html><body><p>python</p></body></html>'>
原本第一个分组里面的内容是<(.+)>,想要起别名,就在.+的前面加上?P< key1>,后面引用这个别名的时候:(?P=key1),要注意括号必须有,有括号才表示分组
如果想获取< p>< /p>中间的内容,应该如何获取呢,或者你想要获取每一个分组的内容?
这时候可以使用group方法,接上面的:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> gr = re.match(res,s)
>>> gr.group() #不写索引值就默认把匹配到的所有值都打出来
'<html><body><p>python</p></body></html>'
>>> gr.group(1) #获取第一个分组
'html'
>>> gr.group(2) #获取第2个分组
'body'
>>> gr.group(3) # 获取第3个分组
'p'
>>> gr.group(4) #获取第4个分组报错了,因为没有第4个了
Traceback (most recent call last):
File "<input>", line 1, in <module>
IndexError: no such group
如果只想获取< p>< /p>中间的内容python,那你要把中间匹配到的内容用()括起来,表示也是一个分组:
res = r"<(?P<key1>.+)><(?P<key2>.+)><(?P<key3>.+)>(.+)</(?P=key3)></(?P=key2)></(?P=key1)>"
gr = re.match(res,s)
gr.group(4)
'python'
第五部分,re模块的其他方法:
Search方法,从待匹配的字符串中检索出需要的,比如从”阅读次数为 999”字符串中检索出阅读次数:
>>> ret = re.search(r"\d+","阅读次数为:999")
>>> ret.group()
'999'
Search方法只能匹配到第1次的内容,比如:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> ret = re.search(r"\d+","阅读次数为:999,浏览次数为:2000")
>>> ret.group()
'999'
如果想要把所有的数字都找出来,可以使用findall方法,findall方法返回的是一个列表,没有group方法,可以直接打印列表
>>>ret = re.findall(r"\d+","阅读次数为:999,浏览次数为:2000")
>>> ret
['999', '2000']
这里强调一下正则表达式中的()问题:
- 正则表达式中没有括号时,就是正常匹配,跟之前讲的match()里面的用法一样。比如下面这段:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import re
str = 'wang 123 sun 456 a WANG'
pattern = re.compile(r'\w+\s+\w+')
li = pattern.findall(str)
print(li)
结果为:[‘wang 123’, ‘sun 456’, ‘a WANG’]
- 如果有一个括号,输出的内容就是括号中的内容,比如将正则表达式改为:
pattern = re.compile(r'(\w+)\s+\w+')
li = pattern.findall(str)
print(li)
输出的结果为:[‘wang’, ‘sun’, ‘a’]
匹配还是按照没有括号的\w+\s+\w+这个正则表达式匹配,但是输出的只有括号中的内容。
- 当正则表达式中有两个括号时,那输出list的每个元素是一个元组,每个元组包含两个元素,这两个元素对应的就是正则中两个括号的内容。比如:
pattern = re.compile(r'((\w+)\s+\w+)')
li = pattern.findall(str)
print(li)
结果:[(‘wang 123’, ‘wang’), (‘sun 456’, ‘sun’), (‘a WANG’, ‘a’)]
compile方法:
要提取出一个字符串中的英文字母,可以用以下的方法:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
import re
pattern = re.compile('[a-zA-Z]')
s = pattern.findall('sdf223dgrz')
打印的结果为:[‘s’, ‘d’, ‘f’, ‘d’, ‘g’, ‘r’, ‘z’]
compile方法的意思是编译正则表达式模式,返回一个正则表达式对象,可以把常用的正则表达式通过compile编译出来,方便以后的调用,比如想找出多个字符串中的英文字母,就可以像上面那样写,再多写几个findall方法。如果不用compile方法,上面那两行代码可以写成:print(re.findall(’[a-zA-Z]’, ‘sdf223dgrz’))。
compile还有第2个参数是flags,默认传0,flags编译标志位,用来修改正则表达式的匹配方式,常用的值有:
-
re.I :匹配的时候忽略大小写
-
re.L : 做本地化识别匹配
-
re.M : 多行匹配,影响^和$
-
re.S : 使‘.’可以匹配到‘/n’
比如找出下面str字符串中的wan开头的,不区分大小写:
str = 'wang xian sheng is a WANG'
pattern = re.compile(r'wan\w', re.I)
li = pattern.findall(str)
print(li)
打印结果为:[‘wang’, ‘WANG’]
Sub方法可以替换匹配到的字符串
>>> ret = re.sub(r"\d+","1000","阅读次数为:999 ")
>>> ret
'阅读次数为:1000 ’
sub方法的第一个参数是正则表达式,需要替换掉的内容,第2个参数为替换后的数据,第三个参数是待匹配待替换的字符串
第二个参数也可以为一个方法名,比如将阅读次数加1:
定义一个方法,有一个参数,接收匹配到的数据,并且返回一个数据
sub方法会将匹配到的数据依次传到方法read_num中,所以我们首先要使用group方法获取到每个参数的具体内容,然后将这个字符串转为int类型,再加1,注意return的时候要转为字符串,这个位置的值只能是字符串
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
def read_num(num):
num_temp = num.group()
num = int(num_temp) + 1
return str(num)
s = "阅读次数为:999,浏览次数为2000"
ret = re.sub(r"\d+",read_num,s)
print(ret)
#print结果:阅读次数为:1000,浏览次数为2001
将句子中的pho换成python
>>> ret = re.sub(r"php","python","I love php")
>>> ret
'I love python'
区分大小写:
>>> ret = re.sub(r"php","python","I love phP")
>>> ret
'I love phP'
Python中的贪婪和非贪婪
Python中默认的匹配时贪婪的(即尽可能多的匹配),那么如何能做到非贪婪呢?
在“*”“?”“+”“{m,n}”的后面加上?就可以做到非贪婪,尽可能少的匹配
比如:s=“this is a number: 0312-265-8888”,匹配出里面的电话号码,如果用下面第一种方法:
>>> ret = re.match(r".+(\d+-\d+-\d+)",s) #因为要匹配数字,所以把号码用括号括起来
>>> ret.group()
'this is a number: 0312-265-8888'
#这个结果是这种方式提取到的号码,明显不是我们想要的
>>> ret.group(1)
'2-265-8888'
这面这种方式就是贪婪方式,前面的.+尽可能的匹配多一些,后面的\d+只要有一个数字就可以满足,所以别的数字都归到了.+里面,在.+的后面加?后结果就不一样了:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> ret = re.match(r".+?(\d+-\d+-\d+)",s)
>>> ret.group(1)
'0312-265-8888'
加了?改成了非贪婪模式,那就是说尽可能多的匹配后面的\d+。
补充:
-
\s:匹配的是任意的空白字符,
-
\S:匹配的是任意的非空白字符
所以[\s\S]:就可以匹配到任意字符
[\s\S]? 的意思是非贪婪模式下匹配任意字符,等同于.? 再加一个参数re.S
这个的group()方法,还有另外的类似方法是groups(),举例:
>>> ret = re.match(r"(.+?)(\d+-\d+-\d+)",s)
>>> ret.groups()
('this is a number: ', '0312-265-8888')
Groups方法返回一个元祖,每一个分组匹配到的字符串放到元祖里面。
上面的结果是加了?的,如果不加?,那么结果为:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
>>> ret = re.match(r"(.+)(\d+-\d+-\d+)",s)
>>> ret.groups()
('this is a number: 031', '2-265-8888')
Split()方法的用法:
找出s中的单词
>>> s = "hi python,hello world"
#用,或者空格分隔s,返回一个列表,注意:|的后面有一个空格
>>> ret = re.split(r",+| +",s)
>>> ret
['hi', 'python', 'hello', 'world']