NLP文本数据增强热门技术
背景
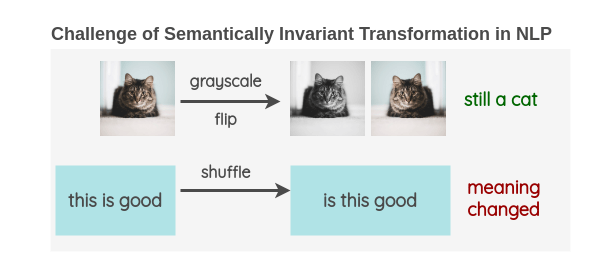
CV中有很多简单实用的数据增强方式,如旋转图像、调整RGB等。这些方法在保证图像特征的基础上增加了训练量,进而能够提升模型的表现效果。但在NLP中这些方法就不再适用,文本上少量的调整都可能改变整体上下文语义信息。
《A Visual Survey of Data Augmentation in NLP》(本文主要参考文章)中这样阐述这种情况:
word替换
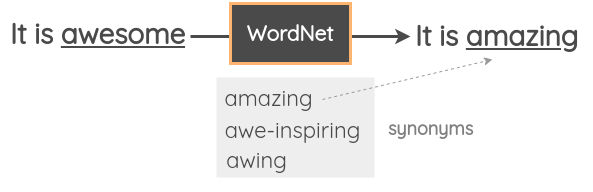
同义词替换
基于公开的知识库,随机选择当前句子中的单词,应用同义词库将其替换为其同义词。比如,使用WordNet数据库,将「awesome」替换为「amazing」。
使用该方法扩充数据集的论文如:
- Character-level Convolutional Networks for Text Classification
- EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
- Siamese Recurrent Architectures for Learning Sentence Similarity
词向量替换
采用预先训练好的单词嵌入,如Word2Vec、GloVe、FastText、Sent2Vec,并使用嵌入空间中最近的相邻单词替换句子中的某些单词。(个人认为用bert微调后的向量表现更佳)

因为词向量可将词汇映射到同一个语义空间,在具体应用中,我们可以通过临近词替换当前词的方式,随机替换单词进而增加训练数据。
使用该方法的论文如:
另外,也可以调用api接口,来获取词向量和每个词的临近词向量。可以导入预训练好的词向量,也可以自行训练(自行训练需要构建个人语料集,分词后feed到词向量模型,经过训练后再计算相似度)。
#导入预训练好的Glove词向量
import gensim.downloader as api
info = api.info() # show info about available models/datasets
model = api.load("glove-twitter-25") # download the model and return as object ready for use
model.most_similar("cat")#导入预训练好的word2vec词向量
from gensim.models.word2vec import Word2Vec
import gensim.downloader as api
corpus = api.load('text8') # download the corpus and return it opened as an iterable
model = Word2Vec(corpus) # train a model from the corpus
model.most_similar("car")掩码语言模型(Masked Language Model,MLM)
在BERT模型中,可以通过MLM来根据上下文预测遮盖的词汇。因为bert已经采用大量语料集进行了预训练,所以这种方法生成的词汇在语义程度上更接近原词,生成的文本也更有可解释性。
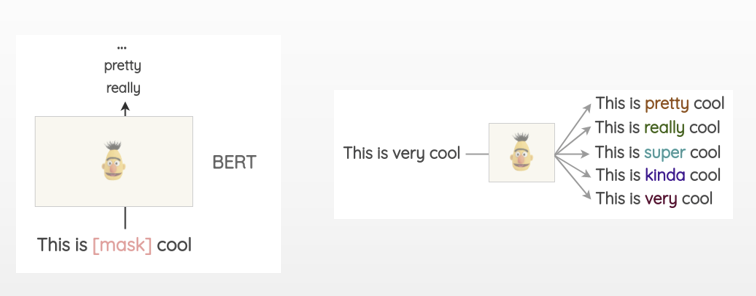
这种方法存在的问题是要考虑遮盖哪些词,能最大限度保留文本上下文语义。
源码可参考:token预测
基于tfidf的词替换
替换文本中tfidf分数较低的词汇,要替换的词汇由所有分数较低的词汇中随机抽样。
使用该方法的论文有:

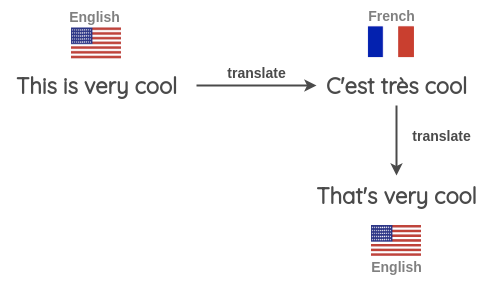
反向翻译
先将文本翻译成其他语言,再翻译回来,如果新文本与原文本形式不一,即可用于数据增强。
资源:Google Sheets说明
文本表面转换
使用简单模式匹配来进行转换,这个主要基于正则表达式,无太多技术含量,此处不详述。

随机噪声
加入噪声是机器学习常用的用于提高模型鲁棒性的方法。主要有如下几种噪声注入方式。
注入拼写错误例子
映射常见拼写句子,生成错误映射。
资源:英文常见错误映射
空白噪声
随机去除一些词汇,并用占位符标记。常用于缓解过拟合问题。

打乱文本句子顺序

随机处理(插入、替换、删除)

语法树
总结可为:规则+语法依赖树。实用价值较小,不详述。

文本混合
思想基于图像增强技术,经过修改应用于NLP。相关论文:
- Augmenting Data with Mixup for Sentence Classification: An Empirical Study
具体方法有wordMixup和sentMixup两种。
wordMixup
随机选择两个文本,经过等长的embedding嵌入,按比例组合在一起。然后再经过CNN/LSTM等编码得到文本嵌入,计算交叉熵。

sentMixup
与上述方法类似,在细节处做了调整。
