最近在读《Introduction to Data Mining 》这本书,发现课后答案只有英文版,于是打算结合自己的理解将答案翻译一下,其中难免有错误,欢迎大家指正和讨论。侵删。
第十章



答:
首先,注意到基于密度和基于邻近度的技术是相关的,因为高密度的区域的点附近必然有很多点。而基于模型的技术需要找到一个适合数据的模型,并且一个具体的模型是假定的,从这一方面来说,基于密度和邻近度的技术不需要对数据做任何假定。此外,基于邻近度的技术可以适用于任何情况,只需要定义好一个合适的邻近度度量,比如欧几里得距离适用于稠密的低维数据集,而余弦相似度适用于稀疏的高维数据集。由于基于密度的技术也需要基于邻近度,因此基于密度的技术也适用于任何数据集,这两种技术通常也会产生相似的结果。

(a)该定义和基于邻近度的方法很类似。
(b)适用于小型数据集。


(a)该定义和基于邻近度的方法很类似。
(b)第一,如果分布不对称的话,从中心到凸包边缘点之间的距离变化会很显著。
第二,这种方法不适合分配有意义的数值异常分数。

(a)属于基于邻近度的技术
(b)优点:该方法发现的项不属于任何大小为3的超团模式中,并且不会与其他任何的项有强关联,很可能是异常点。此外,计算很高效
缺点:这种方法不适合分配有意义的数值异常分数,只能简单地分出异常点和正常点。而且不能直接控制找出的异常点的数目。此外,数据必须是离散的。
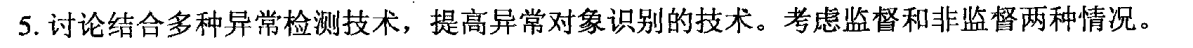
对于监督的情况,应该用整体分类技术,一个点属于哪个类取决于分类点的投票数。非监督的情况,类似的投票方法也可以用,但注意需要假定对象作为异常点是二分类的,如果我们有异常分数,可以和某些规则结合, 比如取平均或最大,产生整体的异常分数。

如果用K均值聚类,复杂度取决于找簇的过程,时间和点的数量成比例,因此是O(m)。此外,基于密度和邻近度的技术需要计算每一对点之间的邻近度,因此复杂度为O(m2)。在一些特别的情况,比如低维数据,可以用特殊的数据结构,比如k-d树,计算点的最近邻会减少计算量,复杂度为O(mlogm)。类似的,基于网格的方法可以减少基于密度的技术的计算量到O(m),但这样的方法可能不太精确,并且适用的范围有限。


(a)

tc的值会随m的增加而缓慢增加。
0.05的显著水平下,m=1020 ,tc = 93
(b)g的分布随着m的增加而逐渐接近于t分布


(a)单侧的值与平均值距离超过标准差3倍的可能性为0.00135,双侧的为0.0027,因此对于1000000个值的集合,会有1350或2700个离群点。
(b)根据实际情况,可以将这些点都看作离群点,也可以定义成超过标准差4倍或5倍的是离群点。

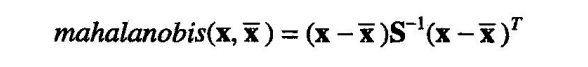
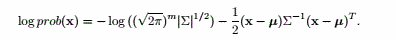
用样本均值和协方差矩阵代入得,
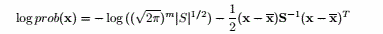

第一个度量是局限的,因为它忽视了一个点可能也离其他的簇很近,轮廓系数不仅考虑了一个点离所在簇的距离,也考虑了到其他簇的距离,因此轮廓系数更全面地考察了一个点属于一个簇的可能性。


(a)因为点D的存在,簇中心会稍微偏上,因此底部的点得分更高。
(b)不能,会被认为是一个只含一个点的簇。
(c)比如心电图,如果有一群病人都有不正常的心电图,如果用相对距离度量会认为这些人是正常的。

检测率 = 1%×0.99 / 1% = 99%
假警告率 = 99%×0.01 / ( 99%×0.01 + 1%×0.99 ) = 0.5

当新的异常类型出现时,需要用到非监督的异常检测技术。但监督的异常检测的技术也能发挥作用,因此这两种技术都需要用到。一个典型的例子就是网络欺诈检测,可以对已知的欺诈类型打上标签和特征。

总的来说,这是一个哲学或语义问题。从定义来说,异常点通常是比较少的,但不排除一个数据集中异常对象比较多的情况。

和上一题类似,是一个定义问题。在实际中,通常在异常检测技术中我们会考虑相对密度。

没意义。对于均匀分布来说,这样的概念是值得怀疑的。