Hyperledger Fabric性能优化
由于最近在做Fabric方向的研究课题,读到一篇文章对于Fabric性能的优化提出了非常好的建议与算法。文章名称《Blurring the Lines between Blockchains andDatabase Systems: the Case of Hyperledger Fabric》,来自顶会Sigmod,附上下载链接,如果想细读,可自行下载。
链接: https://pan.baidu.com/s/1xE-xzyzxAe8COwLd-vqerw .
链接: 密码: j3o8
提出问题
(1)Fabric这样的系统与经典的分布式数据库系统之间,究竟存在哪些概念上的相似和差异?
(2)是否有可能通过将技术从数据库过渡到区块链,从而进一步模糊这两种类型系统之间的界限,进而提高Fabric性能?
实验
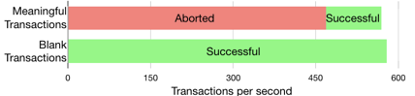
实验一:提交一组有意义的交易,这些交易源于资产传输场景,并报告了吞吐量,划分为中止的交易和成功的交易。这项揭示了Fabric的一个严重的问题:大量的交易最终都被中止了。中止的原因是交易发生冲突,这是并发执行的一个副作用。
解决方法:(a)增加系统的总吞吐量(b)将Fabric中止的交易转为成功的交易
实验二:提交没有任何逻辑的空白交易,空白的和有意义的交易的总吞吐量基本上是相等的,表明系统的吞吐量并不是由交易处理的核心组件控制的,而是由其他辅助因素控制的
Fabric交易处理流程
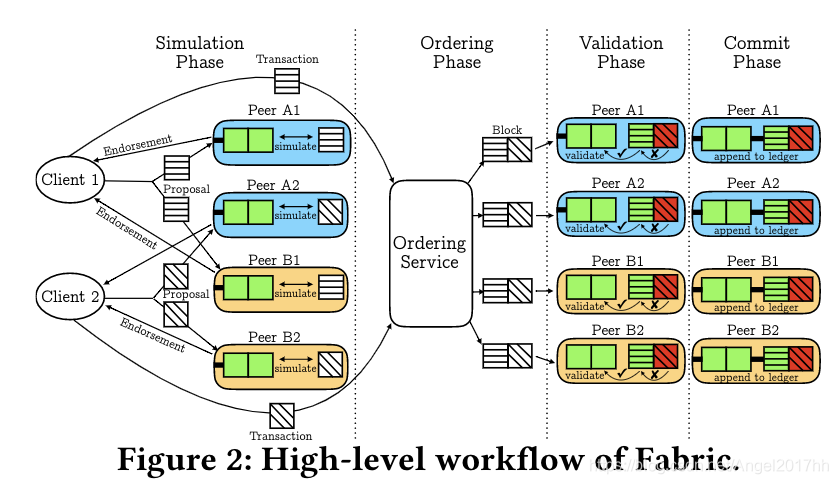
1、模拟阶段:客户端将交易提案发送给peer节点模拟交易,因为组织之间并不互相信任,所以每个组织至少有一个peer节点来模拟,模拟完成后将读写集和对提案的签名返回给客户端,客户端形成实际交易并发送给order节点;
2、排序阶段:排序节点将客户端发送来的交易经过排序后打包成块提交给peer节点进行验证,Fabric一般以交易到达顺序排序,不以任何方式检查语义,不能保证所有peer节点在同一时刻接收到区块,但能保证所有peer节点从order节点接收到的区块内的交易顺序是一样的;
3、验证阶段:验证交易是否遵守背书策略,验证交易是否发生冲突;
4、提交阶段:所有peer节点更新当前状态,并将包含有效和无效的交易的区块写入账本
交易中止、转为成功
一、交易重排序
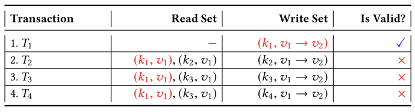
由于T2、T3、T4在模拟期间都读取v1版本中的k1,因此它们没有机会提交,因为它们使用的是k1的过期版本。在验证阶段它们被识别为无效交易,相应的交易提案必须由客户端重新提交,重新模拟->排序->验证->提交。交易重排序后:
交易重排序算法伪代码:
func reordering(Transaction[] S){
//step1:为S中的每个交易建立一个buildConflictGraph()函数来检查读写集并建立一个冲突图
Graph cg=buildConflictGraph(S)
//step2:在冲突图中,必须识别出所有环。我们用divideIntoSubgraphs(cg)方法将cg划分出最强连通子图
Graph[] cg_subgraphs=divideIntoSubgraphs(cg)
//在强连通子图中,每个节点都可以从任何一个其它节点到达,这表明cg的不止一个节点的强连通子图都必须包含至少一个环,我们在连通子图中使用getAllCycles()方法来识别图中的所有环
Cycle[] cycles=emptyList()
foreach subgraph in cg_subgraphs:
if(subgraph.numNodes()>1):
cycles.add(subgraph.getAllCycle())
//step3:为了移除cg中的环,我们必须从S中移除冲突交易,为了弄清交易引起的最严重的问题,对于S中的每个交易,我们都记录它所连成的环有几个
MaxHeap transactions_in_cycles=emptyMaxHeap()
foreach Cycle c in cycles:
foreach Transaction t in c:
if transactions_in_cycles.contains(t):
transactions_in_cycles[t]++
else
transactions_in_cycles[t]=1
//step4:定义S‘为S,将在所有环中出现最多的交易移除,直到所有环都消失
Transaction[] S'=S
while not cycles.empty():
Transaction t=transactions_in_cycles.popMax()
S'.remove(t)
foreach Cycle c in cycles:
if c.contains(t):
c.remove(t)
cycles.remove(c)
foreach Transaction t' in c:
transactions_in_cycles[t']--
//step5:从S‘中必须实现可序列化的调度,开始建立S’的没有环的冲突图
Graph cg‘=buildConflictGraph(S')
//执行调度,从图中还没有被访问过的节点开始
Transactions[] order=emptyList()
Node startNode=cg'.getNextNode()
while order.length()<cg'.numNodes():
addNode=true
if startNode.alreadyScheduled():
startNode=cg'.getNextNode()
continue
//向上遍历寻找根源
foreach Node parentNode in startNode.parents():
if not parentNode.alreadyScheduled():
startNode=parentNode
addNode=false
break
//找到根源,调度并继续向下遍历
if addNode:
startNode.scheduled()
order.append(startNode)
foreach Node childNode in startNode.children():
if not childNode.alreadyScheduled()
startNode=childNode
break
return order.invert()
}
Step1:为交易读写集建立冲突图

根据读写集画Conflict graph
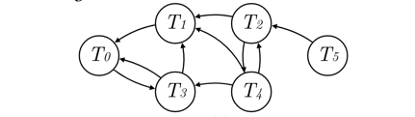
Step2:利用Tarian算法将图划分为几个强连通子图,利用Johnson算法来识别强连通子图中的所有环
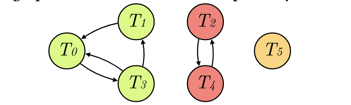
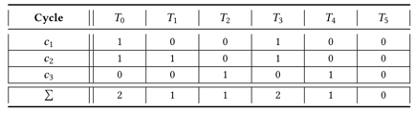
Step3:用表记录每个强连通子图中的环,每笔交易分别存在于哪个环中。环c1=T0->T3->T0,c2=T0->T3->T1->T0,环c3=T2->T4->T2
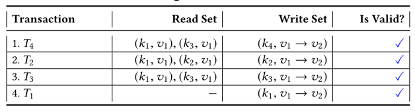
Step4:先处理参与环最多的交易,如果所在的环数一样多,就选择先处理下标小的,例如T0和T3都存在与两个环中,就先处理T0,这保证了算法的确定性。
移除T0和T2

Step5:构建合理的交易顺序T5->T1->T3->T4,交易顺序的得来:先看T1,T1有父级T3和T4,由于T3又有父级T4,所以应该把T4放到最后一个位置,然后从T4向上有T1和T3,由于T3是T1的父级,所以T3应该在倒数第二个位置,T1在倒数第三个位置,由于T5是单独的,应放在第一位,从而得出的交易顺序为T5->T1->T3->T4
出块条件:
在Fabric中,如果满足下面三个条件之一,就将所接收到的所有交易打包成一个区块:
(1)交易达到一定数量;
(2)数据大小达到一定值;
(3)从接收到这些交易的第一个交易开始,已经过去了一段时间(TTC);
为了避免上面的表格中的不同key的数量太多,影响算法性能,提出增加一个打包条件
(4)所接收到的所有交易中的不同key集合达到一定数量
二、使用高级并发控制来提前中止交易(early abort)
为了实现这种机制,在validation过程中,必须检查每个读取值的版本号,并测试它是否更新

一开始,最新被验证通过的block id是last-block-id = 4。首先在模拟阶段的读操作读取balA=70成功,接下来在验证阶段将balA修改为50、将balB修改为100。如果这时候在模拟阶段要读取balB的值,那么对应的交易将是无效的,因为此时last-block-id是4,而更新block-id为5, 4 < 5。表示在区块id为5的区块中的交易将这个值修改了,但是该区块还没验证通过。当该区块验证通过,那么last block id将变为5。
验证优化后的Fabric性能实验
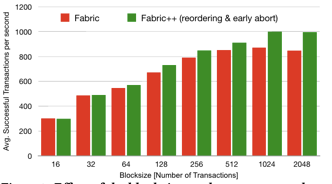
1、Blocksize对吞吐量的影响,fabric默认的Blocksize为10个交易,通过实验发现,增加块大小也会增加Fabric成功交易的吞吐量,由于目标是获得更高的整体吞吐量,所以使用的是1024个交易的Blocksize
2、Workload配置参数值选择
RW:Number of read&written balances per transaction
HR:Probability for picking a hot account for reading
HW:Probability for picking a hot account for writing
HSS:Number of hot account balances
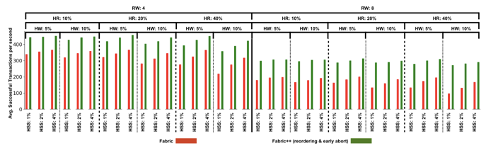
相比较而言,当BS=1024,RW=8,HR=40%,HW=10%,HSS=1%的时候,Fabric++相较于Fabric每秒交易成功的数量增加的最多
3、在最佳配置下测试交易重排序和early abort哪一个机制对Fabric性能优化更多
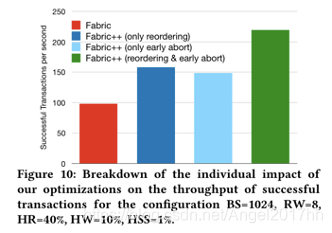
reordering和early abort两个技术协同工作时:在阶段提前中止的交易在order阶段不会以块的形式结束,因此,在重排序过程中,只考虑有实际成功机会的交易
4、测试Fabric++中提出的reordering和early abort交易对Fabric的伸缩能力是否有影响:
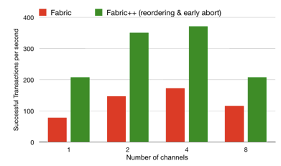
一开始随着通道数量的增长,每秒成功的交易数量也逐渐增多,且Fabric++明显优越于Fabric,但是当通道数量超过4个的时候,交易成功数量又开始减少,说明通道之间会竞争资源

同上,说明客户端之间也会竞争资源
第一次写博客,记录并共享一下读到的好文章,如有不足之处,还望指出。