我们在实际开发过程中整天new对象,但是你知道对象在内存中是怎样布局的吗?你知道对象中包含了哪些信息吗?下面我们就来探究一下。
64位的虚拟机要求对象的大小必须为8的倍数。
在JVM中,对象在内存中的布局分为三部分:对象头、实例数据和对齐填充。
证明Java对象布局
口说无凭,下面我们就来证明一下。
1、首先导入ojl依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
2、创建一个对象
public class A {
public boolean b;
}
3、测试代码
public class Test {
public static A a=new A();
public static void main(String[] args) {
System.out.println(ClassLayout.parseInstance(a).toPrintable());
}
}
4、运行结果

由运行结果可以证实,对象在内存中的布局分为三部分:对象头、实例数据和对齐填充。
对象头是固定大小的,为12个字节;实例数据根据类型的不同占不同的字节,例如boolean类型占1个字节,int类型占4个字节;64位的虚拟机要求对象的大小必须为8的倍数。而对其填充,主要是为了补齐对象头和实例数据占用内存之后剩余的空间大小,如果对象头和实例数据已经占满了JVM所分配的内存空间,那么就不用再进行对齐填充了。
Java对象头
那么对象头是由什么组成的呢?网上的好多资料都是错的,下面就去看一下openjdk的文档。
openjdk文档:openjdk文档
object header
Common structure at the beginning of every GC-managed heap object. (Every oop points to an object header.) Includes fundamental information about the heap object’s layout, type, GC state, synchronization state, and identity hash code. Consists of two words. In arrays it is immediately followed by a length field. Note that both Java objects and VM-internal objects have a common object header format.
翻译如下:
对象头
在每个gc管理的堆对象开始处的公共结构。(每个oop都指向一个对象头。)包括关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。由两个词组成。在数组中,紧随其后的是长度字段。注意,Java对象和vm内部对象都有一个通用的对象头格式。
由此可知,Java对象头由两个词组成,包括了关于堆对象的布局、类型、GC状态、同步状态和标识哈希码的基本信息。
那么对象头到底由哪两个词组成的呢?接着看openjdk文档。
mark word
The first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic low bit encoding) to synchronization related information. During GC, may contain GC state bits.
klass pointer
The second word of every object header. Points to another object (a metaobject) which describes the layout and behavior of the original object. For Java objects, the “klass” contains a C++ style “vtable”.
由openjdk文档可知,Java对象头由mark word和klass pointer两部分组成。
mark word中存储着对象的HashCode、分代年龄、锁标记位等信息。
klass Pointer,即类型指针,是对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
那么mark word和klass pointer在对象头中是怎样分布的呢?
下面看一下openjdk的源码。
64 bits:
// --------
// unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
// JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
// PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
// size:64 ----------------------------------------------------->| (CMS free block)
//
// unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object)
// JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object)
// narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object)
// unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)
由openjdk的源码可知,mark word占了64bit,所以klass pointer占了32bit。
但是也有一些资料说klass pointer占了64bit,这样说也是对的,因为klass pointer在没开启指针压缩的情况下,klass pointer占64bit,在开启指针压缩的情况下占32bit。指针压缩是默认开启的,这样可以更好节约内存,避免GC压力过大。
那么mark word中每一个bit位代表的是什么意思呢?
对象的状态一共分为五种状态,分别是无锁、偏向锁、轻量锁、重量锁、 GC标记。对象在不同的状态,每一个bit位所代表的意思也不一样。具体情况如下图所示:
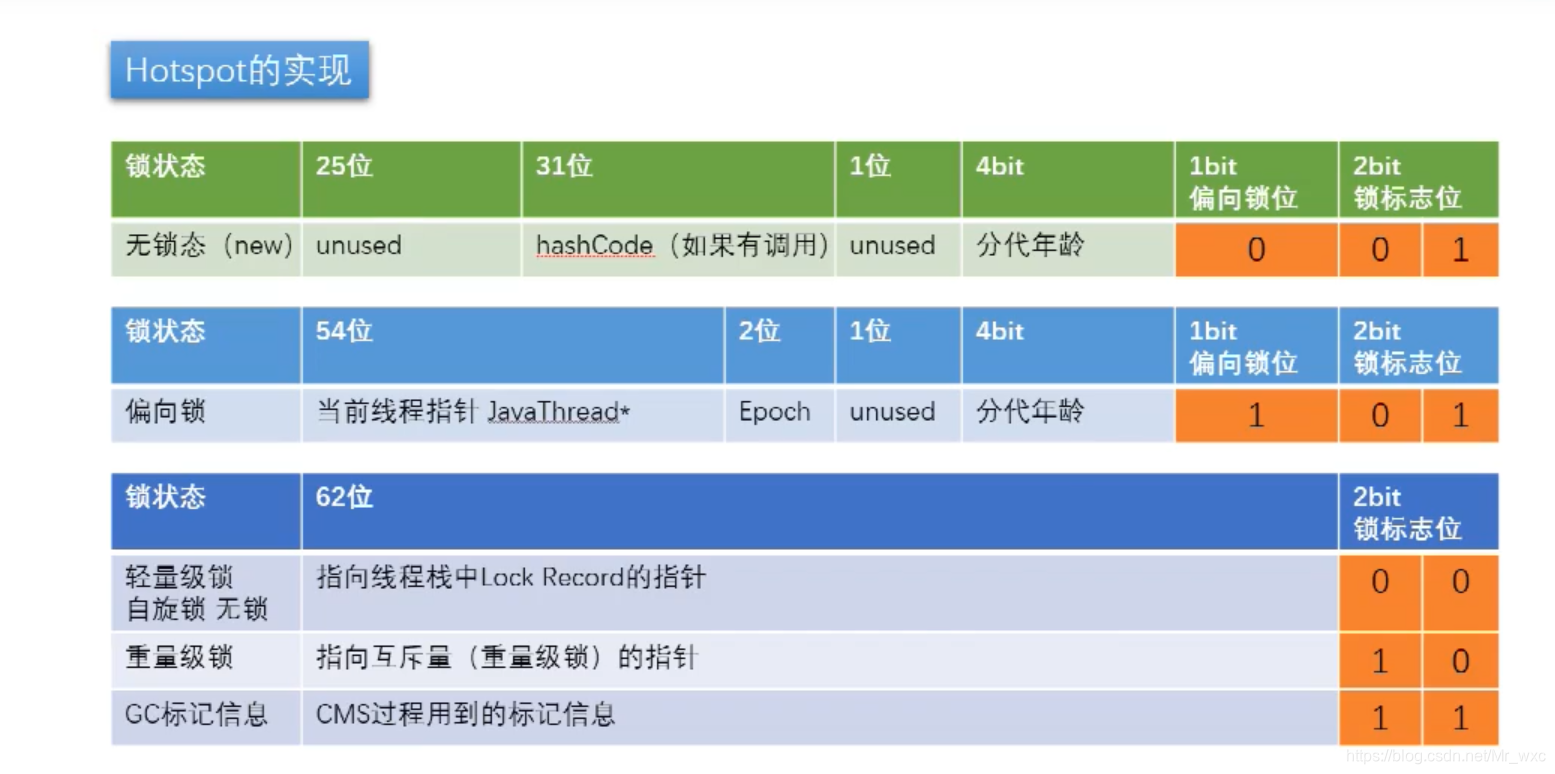
其中,锁标志位占了两个bit,那它是怎样表示五种状态的呢?
jvm把无锁和偏向锁表示为同一个状态01, 然后再根据偏向锁位的标识再去判断是无锁状态还是偏向锁状态,如果偏向锁位的标识为0,表示为无锁;如果偏向锁位的标识为1,表示偏向锁。
对象在无锁状态下的对象布局如下所示:
1540e19d
zzuli.edu.cn.A object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 9d e1 40 (00000001 10011101 11100001 01000000) (1088527617)
4 4 (object header) 15 00 00 00 (00010101 00000000 00000000 00000000) (21)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
如果按照上图所示,那么为什么对象布局的输出结果与我们图中所说的不一样呢?
因为JVM在存储数据时使用的是小端存储,存储数据时会把数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。通俗点来说就是把数据倒过来进行存储。所以此时前8位分别存的就是分带年龄、偏向锁信息和对象状态,往后的31位存储的是对象的哈希值。这样对象布局的输出结果就与上图对应起来了。
我们在开发中经常使用synchronized数据实现线程之间的同步,那你知道synchronized的实现原理吗?知道synchronized的锁升级过程是怎样实现的吗?这都与对象头中的mark word有关,下一篇再来详细介绍synchronized的实现原理,以及锁升级的过程。