13.线性排序:如何根据年龄给100万用户数据排序?
markdown文件已上传至github
桶排序、计数排序、基数排序的时间复杂度都为O(n),所以称为线性排序。之所以能做到线性的时间复杂度,主要原因是
这三个算法都不是基于比较的排序算法,都不涉及元素之间的比较操作。
思考:如何根据年龄给100万用户排序?
归并、快排能够解决这个问题,最快时间复杂度也是O(nlogn),有没有更快的排序方法呢?
1.桶排序
核心思想是将要排序的数据分到几个有序的桶里,每个桶里的数据再单独进行排序。桶内排完序之后,再把每个桶里的数据按照顺序依次取出,组成的序列就是有序的了。

1.桶排序的时间复杂度为O(n).
如果要排序的数据有 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。即将数据分成m份并行进行排序。
桶排序能否替代我们之前讲的排序算法呢?
答案是不能。
首先,要排序的数据需要很容易就能划分成 m 个桶,并且,桶与桶之间有着天然的大小顺序。这样每个桶内的数据都排序完之后,桶与桶之间的数据不需要再进行排序。

其次,数据在各个桶之间的分布是比较均匀的。如果数据经过桶的划分之后,有些桶里的数据非常多,有些非常少,很不平均,那桶内数据排序的时间复杂度就不是常量级了。在极端情况下,如果数据都被划分到一个桶里,那就退化为 O(nlogn) 的排序算法了。
**桶排序比较适合用在外部排序中。**所谓的外部排序就是数据存储在外部磁盘中,数据量比较大,内存有限,无法将数据全部加载到内存中
2.计数排序
计数排序是桶排序的一种特殊情况。当要排序的 n 个数据,所处的范围并不大的时候,比如最大值是 k,我们就可以把数据划分成 k 个桶。每个桶内的数据值都是相同的,省掉了桶内排序的时间。(比如一个省高考有50万人,但分数范围是0分到满分900分。将分数分为901个桶,只需依次扫描每个桶依次输出到数组中就完成了排序)。我们可以用数组来代替桶,数组中的数为值为此下标的数的个数。计数排序代码:
计数排序代码:
// 计数排序,a是数组,n是数组大小。假设数组中存储的都是非负整数。
public void countingSort(int[] a, int n) {
if (n <= 1) return;
// 查找数组中数据的范围
int max = a[0];
for (int i = 1; i < n; ++i) {
if (max < a[i]) {
max = a[i];
}
}
int[] c = new int[max + 1]; // 申请一个计数数组c,下标大小[0,max]
for (int i = 0; i <= max; ++i) {
c[i] = 0;
}
// 计算每个元素的个数,放入c中
for (int i = 0; i < n; ++i) {
c[a[i]]++;
}
// 依次累加
for (int i = 1; i <= max; ++i) {
c[i] = c[i-1] + c[i];
}
// 临时数组r,存储排序之后的结果
int[] r = new int[n];
// 计算排序的关键步骤,有点难理解
for (int i = n - 1; i >= 0; --i) {
int index = c[a[i]]-1;
r[index] = a[i];
c[a[i]]--;
}
// 将结果拷贝给a数组
for (int i = 0; i < n; ++i) {
a[i] = r[i];
}
}
计数排序只能用在数据范围不大的场景中,如果数据范围 k 比要排序的数据 n 大很多,就不适合用计数排序了。而且,计数排序只能给非负整数排序,如果要排序的数据是其他类型的,要将其在不改变相对大小的情况下,转化为非负整数(整体加上一个整数)。如果要求数据精确到小数后一位,可以将所有数据先乘以10。
3.基数排序
假设我们有 10 万个手机号码,希望将这 10 万个手机号码从小到大排序,你有什么比较快速的排序方法呢?
手机号码有 11 位,范围太大,显然不适合用桶排序和计数排序这两种排序算法。
这个问题里有这样的规律:假设要比较两个手机号码 a,b 的大小,如果在前面几位中,a 手机号码已经比 b 手机号码大了,那后面的几位就不用看了。借助稳定排序算法,这里有一个巧妙的实现思路。还记得我们第 11 节中,在阐述排序算法的稳定性的时候举的订单的例子吗?我们这里也可以借助相同的处理思路,先按照最后一位来排序手机号码,然后,再按照倒数第二位重新排序,以此类推,最后按照第一位重新排序。经过 11 次排序之后,手机号码就都有序了。
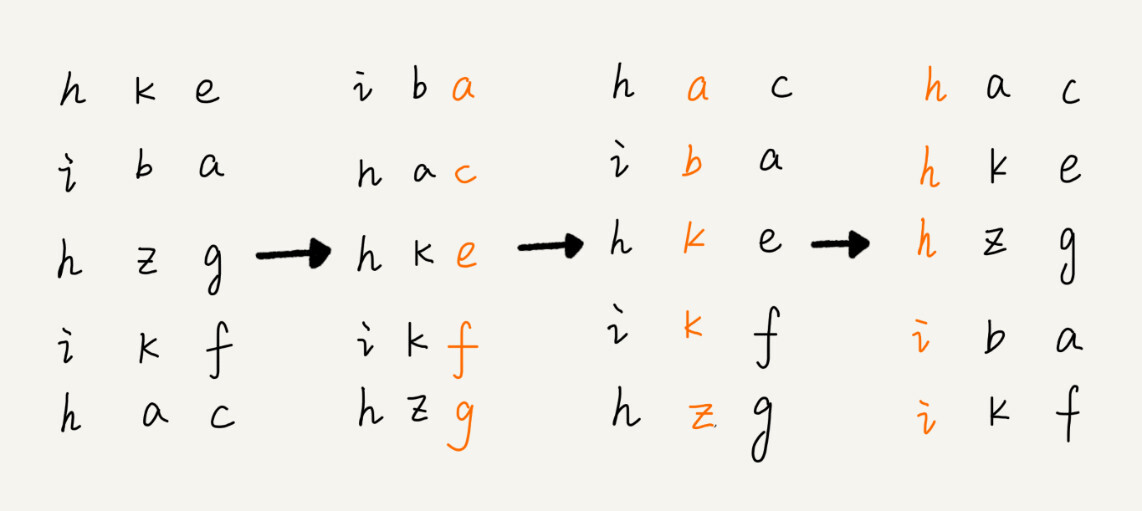
注意:按照每位来排序要求排序算法是稳定的。
根据每一位来排序,我们可以用刚讲过的桶排序或者计数排序,它们的时间复杂度可以做到 O(n)。如果要排序的数据有 k 位,那我们就需要 k 次桶排序或者计数排序,总的时间复杂度是 O(k*n)。当 k 不大的时候,比如手机号码排序的例子,k 最大就是 11,所以基数排序的时间复杂度就近似于 O(n)。
当数据不是等长的,如单词,我们可以把所有单词补齐到相同的长度,位数不够的可以在后面补0(所有字母的ASCII码都大于零)。
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了(高位要后于低位进行排序)。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。
4.解答开篇
如何根据年龄给 100 万用户排序?
用计数排序,根据年龄给 100 万用户排序,就类似按照成绩给 50 万考生排序。我们假设年龄的范围最小 1 岁,最大不超过 120 岁。我们可以遍历这 100 万用户,根据年龄将其划分到这 120 个桶里,然后依次顺序遍历这 120 个桶中的元素。这样就得到了按照年龄排序的 100 万用户数据。
5.思考
我们今天讲的都是针对特殊数据的排序算法。实际上,还有很多看似是排序但又不需要使用排序算法就能处理的排序问题。
假设我们现在需要对 D,a,F,B,c,A,z 这个字符串进行排序,要求将其中所有小写字母都排在大写字母的前面,但小写字母内部和大写字母内部不要求有序。比如经过排序之后为 a,c,z,D,F,B,A,这个如何来实现呢?如果字符串中存储的不仅有大小写字母,还有数字。要将小写字母的放到前面,大写字母放在最后,数字放在中间,不用排序算法,又该怎么解决呢?
法1.利用快速排序的思想,遍历数组,大写从数组尾开始放,小写从数组头开始放。
法2.利用桶排序思想,弄小写,大写两个桶,遍历一遍,都放进去,然后再从桶中取出来就行了。相当于遍历了两遍,复杂度O(n)
6.参考
这个是我学习王争老师的《数据结构与算法之美》所做的笔记,王争老师是前谷歌工程师,该课程截止到目前已有87244人付费学习,质量不用多说。

截取了课程部分目录,课程结合实际应用场景,从概念开始层层剖析,由浅入深进行讲解。本人之前也学过许多数据结构与算法的课程,唯独王争老师的课给我一种茅塞顿开的感觉,强烈推荐大家购买学习。课程二维码我已放置在下方,大家想买的话可以扫码购买。

本人做的笔记并不全面,推荐大家扫码购买课程进行学习,而且课程非常便宜,学完后必有很大提高。
