selenium 简介
随着网络技术的发展,目前大部分网站都采用动态加载技术,常见的有 JavaScript 动态渲染和 Ajax 动态加载
对于爬取这些网站,一般有两种思路:
- 分析 Ajax 请求,通过模拟请求得到真实的数据,这种方法在之前的文章中已经多次使用,这里就不再赘述了
- 使用 selenium 模拟浏览器进行动态渲染,从而获取网站返回的真实数据,以下我们将详细讲解这种方法
selenium 究竟是什么呢?简单来说,selenium 就是一个用于 Web 应用程序的测试工具
根据官方文档所说,selenium 最大的优点就是它可以直接运行在浏览器上,模拟用户的真实行为
但同时这也是它最大的缺点,由于需要模拟真实的渲染过程,所以导致它的运行速度变慢
其它详细的说明请参考 :
中文文档
selenium 安装
准备工作
安装 selenium
>pip install selenium
安装驱动
- 在使用 selenium 的时候,必须有对应的浏览器驱动器文件在 Python 的安装目录下,否则会出现异常
- Chrome 驱动器下载官网如下:https://sites.google.com/a/chromium.org/chromedriver/home
- 由于上面的官网需要翻墙才能访问,所以博主也在这里简单的给大家讲讲安装驱动的方法,具体的步骤如下:
-
打开 Chrome 浏览器,在地址栏中输入地址 chrome://settings/help,查看 Chrome 浏览器的版本信息
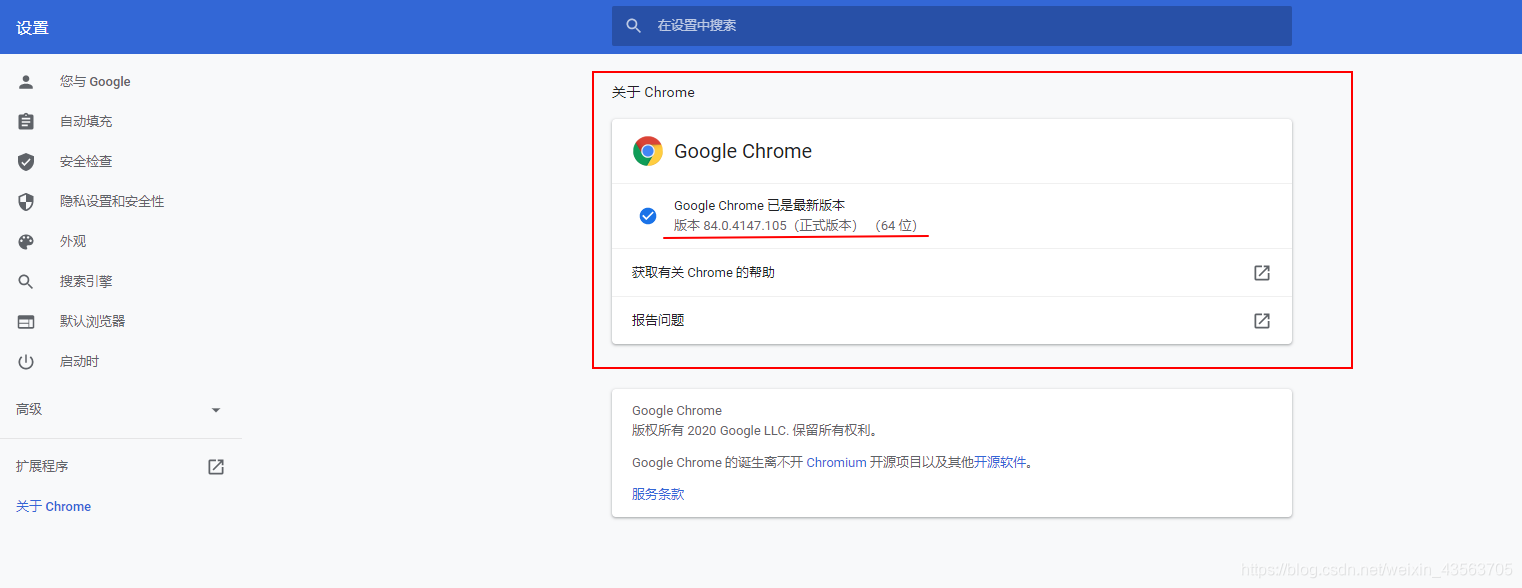
例如 84.0.4147.105
-
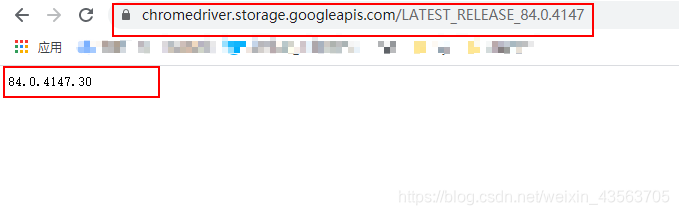
将上面的信息去掉最后一部分后附加到
https://chromedriver.storage.googleapis.com/LATEST_RELEASE_
例如https://chromedriver.storage.googleapis.com/LATEST_RELEASE_84.0.4147
-
-
访问上面的链接,得到对应的驱动器版本信息
例如 84.0.4147.30 -
将上面的信息附加到
https://chromedriver.storage.googleapis.com/index.html?path=,并在最后带上斜杠例如
https://chromedriver.storage.googleapis.com/index.html?path=84.0.4147.30/ -
访问上面的链接,选择合适平台(linux、mac、win)压缩包进行下载
-
等待下载完成后解压,将解压后的文件放到 Python 安装目录下即可
基本使用
- 导入模块
>>> from selenium import webdriver
- 开启浏览器
>>> browser = webdriver.Chrome()
>>> type(browser)
# <class 'selenium.webdriver.chrome.webdriver.WebDriver'>
- 访问页面
使用 WebDriver 对象的 get(url) 方法可以访问对应 URL 的页面
>>> browser.get('https://www.baidu.com')
>>> print(browser.current_url) # current_url 属性可以得到当前网页的 URL
# https://www.baidu.com/
>>> print(browser.page_source) # page_source 属性可以得到当前网页的源代码
- 查找元素
方法一 :
| 方法 | 描述 |
|---|---|
| find_element_by_id(id) | 通过 id 匹配 |
| find_element_by_name(name) | 通过 name 匹配 |
| find_element_by_class_name(name) | 通过 class_name 匹配 |
| find_element_by_tag_name(name) | 通过 tag_name 匹配 |
| find_element_by_link_text(link_text) | 通过 link_text 匹配 |
| find_element_by_partical_link_text(link_text) | 通过 partical_link_text 匹配 |
| find_element_by_css_selector(css_selector) | 通过 css_selector 匹配 |
| find_element_by_xpath(xpath) | 通过 xpath 匹配 |
以下尝试使用几种方法匹配输入框:
>>> search_bar = browser.find_element_by_id('kw')
>>> search_bar = browser.find_element_by_css_selector('#kw')
>>> search_bar = browser.find_element_by_xpath('//*[@id="kw"]')
>>> type(search_bar)
# <class 'selenium.webdriver.remote.webelement.WebElement'>
方法二:
>>> from selenium.webdriver.common.by import By
>>> element = browser.find_element(by,value)
- 参数 value 是与匹配方法对应的匹配表达式
- 参数 by 指定匹配方法,其可选值列举如下(和方法一类似)
| 值 | 描述 |
|---|---|
| By.ID | 通过 id 匹配 |
| By.NAME | 通过 name 匹配 |
| By.CLASS_NAME | 通过 class_name 匹配 |
| By.TAG_NAME | 通过 tag_name 匹配 |
| By.LINK_TEXT | 通过 link_text 匹配 |
| By.PARTIAL_LINK_TEXT | 通过 partical_link_text 匹配 |
| By.CSS_SELECTOR | 通过 css_selector 匹配 |
| By.XPATH | 通过 xpath 匹配 |
以下尝试使用几种方法匹配确认按钮:
>>> from selenium.webdriver.common.by import By
>>> button = browser.find_element(By.ID,'su')
>>> button = browser.find_element(By.CSS_SELECTOR,'#su')
>>> button = browser.find_element(By.XPATH,'//*[@id="su"]')
>>> type(button)
# <class 'selenium.webdriver.remote.webelement.WebElement'>
注意 :
对于两种方法来说,若成功找到则返回 WebElement 对象,若没有找到则抛出 NoSuchElementException 异常
当需要查找多个元素时,只需要把方法中的 element 改成 elements 即可,此时返回的是匹配列表
- 元素交互操作
常见的元素交互操作列举如下:- 获取文本节点(可以使用 text 属性获取文本节点)
- 获取元素属性值
>>> button.get_attribute('type')
# 'submit'
- 写入输入框
>>> search_bar.send_keys('Selenium') # 向输入框输入内容
>>> search_bar.clear() # 清空输入框
>>> search_bar.send_keys('Selenium')
>>> from selenium.webdriver.common.keys import Keys
>>> search_bar.send_keys(Keys.ENTER) # 向输入框输入ENTER键
- 点击提交按钮
# 点击提交按钮,等价于上面的 search_bar.send_keys(Keys.ENTER)
>>> button.click()
- 执行交互动作
将动作附加在动作链中串行执行,常用的方法列举如下:
| 方法 | 描述 |
|---|---|
| click(on_element=None) | 鼠标左键点击元素 |
| double_click(on_element=None) | 鼠标左键双击元素 |
| context_click(on_element=None) | 鼠标右键点击元素 |
| click_and_hold(on_element=None) | 按下鼠标 |
| release(on_element=None) | 松开鼠标 |
| move_to_element(to_element) | 移动鼠标到指定元素中央 |
| drag_and_drop(source, target) | 拖拽元素 |
| key_down(value, element=None) | 按下键盘,一般只用在 Ctrl、Alt 和 Shift |
| key_up(value, element=None) | 松开键盘 |
| send_keys(keys_to_send) | 发送键盘输入到当前聚焦元素 |
| send_keys_to_element(element, keys_to_send) | 发送键盘输入到指定元素 |
| pause(seconds) | 在指定的时间内暂停所有的输入 |
| perform() | 执行动作链的所有动作 |
以下示例为滚动到下一页按钮所在位置并点击下一页按钮翻页
>>> from selenium.webdriver.common.action_chains import ActionChains
>>> target = browser.find_element_by_class_name('n')
>>> ActionChains(browser).move_to_element(target).click(target).perform()
- 执行 JavaScript
JavaScript 能完成绝大部分的网页操作,由于内容庞杂,这里就不展开细说了
以下通过一个简单的例子来说明 JavaScript 的作用,其功能为拖动网页至底部:
>>> js = "window.scrollTo(0,document.body.scrollHeight)"
>>> browser.execute_script(js)
- 等待
>>> from selenium.webdriver.support.wait import WebDriverWait
>>> from selenium.webdriver.support import expected_conditions as EC
>>> wait = WebDriverWait(browser,10)
>>> try:
element = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'n')))
except:
browser.quit()
其它的 expected_conditions 方法列举如下:
| 属性 | 描述 |
|---|---|
| title_is(title) | 验证 title 是否等于 browser.title |
| title_contains(title) | 验证 title 是否包含于 browser.title |
| presence_of_element_located(locator) | 验证 locator 元素是否加载在 DOM 中 |
| presence_of_all_elements_located(locator) | 验证 locator 元素是否全部加载在 DOM 中 |
| visibility_of_element_located(locator) | 验证 locator 元素是否可见 |
| invisibility_of_element_located(locator) | 验证 locator 元素是否隐藏 |
| text_to_be_present_in_element(locator,text) | 验证 text 是否包含于 locator 元素的 text 中 |
| text_to_be_present_in_element_value(locator,text) | 验证 text 是否包含于 locator 元素的 value 中 |
| frame_to_be_available_and_switch_to_it(locator) | 验证 locator(frame) 元素是否可切入 |
| element_to_be_clickable(locator) | 验证 locator 元素是否可点击 |
| element_located_to_be_selected(locator) | 验证 locator 元素是否被选中 |
- 关闭浏览器
| 方法 | 描述 |
|---|---|
| close | 关闭当前窗口 |
| quit() | 关闭所有关联窗口 |
一个简单的示例如下:
>>> browser.quit()