之前一个朋友麻烦我帮他爬取一下华硕笔记本信息,最后存储为一个csv格式的文件,文件格式为"系列 型号"。本文为本人实现该爬虫的心路旅程。
一、获取系列信息
1. 爬虫可行性分析
- 要爬取一个网页,首先要遵守robots协议,于是我们来看看华硕官网的robots协议:
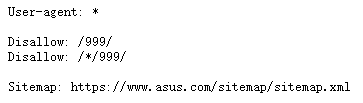
结合上我们要爬取的网址:https://www.asus.com.cn/support,发现不在robots协议中,这方面来分析,这个网页是可爬取的。 - 我们再来看看网页,我们要爬取的数据就是这两个下拉菜单里面的数据,为公开数据,那么这也是可爬取的。

2. 网页分析
2.1 html分析
我首先是检查了一下html,如果数据直接能够通过html获取,那么就可以使用bs4来进行html解析了,html如下:

当时我一阵惊喜,呀,直接bs4解析那不就成了?然后现实是骨干的,以下是requests请求后的结果:

我搜索了一下爬出来的内容,但是并没有select标签,这说明整个页面是js提交上来的页面,所以这个方法放弃。
2.2 网站传入文件分析
我们先来看看,肯定是产品型号的传入的文件好获取,是因为产品型号肯定是一个级联查询,是根据产品系列决定的,所以我们肯定要先选择产品系列,才会向后台提交一个请求,返回数据,所以我们就随便选择一个系列,看这时候网站提交了什么请求,返回了什么数据就行。

我们此时看到红色箭头就是网站初步加载结束到我选择了产品系列为“A/K系列”中间的过程,而这时请求的数据,那必定是产品型号的数据,所以我们很容易就发现了黄色箭头指向的这个文件。细心的同学也会发现这个文件的typeid=6147,和上面图中html中的value值一模一样,那么我们就可以开始猜测,这就是请求不同文件的标签,我们就多选择几个文件,发现只有这个typeid不同,那么证明我们的猜测成功。

于是我们获取了产品型号的json数据,接着来看产品系列的json数据,我这里处理就比较智障了(主要是我也想不出其他更好地办法),就是看着Get开头的文件就点开看看是不是我要的数据。

当然,这里肯定是有过滤的,比如这个GetHighlightLink,明显是获取高亮链接,GetFaqFilters是获取提问解答过滤器,这些都可以直接给pass掉,寻找我们觉得可能的信息。
然后我们看看这个json文件,发现这里Id为6147,就是html上面的value值,就等于是我们寻找的typeId值,所以爬取了这个系列的值后,就等于我们顺手还获取到了型号的链接了。
二、代码书写
代码这里就没什么好说的了,无非就是怎样读取这些json数据,怎样封装,怎样打包放入csv格式的文件中,代码上我有注释,先上代码。
import requests
import json
import os
import csv
def make_csv(crawl_dict):
"""
书写csv文件
:param crawl_dict: 最终爬取的字典
:return:
"""
with open("./data/laptop_data.csv", 'w+', encoding='utf-8') as f:
f.write(u'\ufeff') # 处理Excel打开乱码
# 设置csv文件头
csv_write = csv.writer(f)
csv_head = ['系列', '型号']
csv_write.writerow(csv_head)
for k in crawl_dict.keys():
for model in crawl_dict[k]:
csv_data = [k, model]
csv_write.writerow(csv_data)
csv_break = ['', '']
csv_write.writerow(csv_break)
if __name__ == '__main__':
id_dict = {}
final_dict = {}
# 修改请求头, 伪装成浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/71.0.3578.98 Safari/537.36",
}
product_url = "https://www.asus.com.cn/support/api/product.asmx/GetPDLevel?website=cn&type=1&typeid=155" \
"&productflag=0 "
try:
product = requests.get(product_url, headers=headers, timeout=(60, 60))
product.raise_for_status()
product.encoding = "UTF-8"
product_text = product.text
product_dict = json.loads(product_text)
products = product_dict['Result']['ProductLevel']['Products']['Items'] # 获得产品系列列表
for item in products:
# 循环列表中每一项,每一项为一个dict,dict中第一项为value值,第二项为系列的name值
id_dict[item['Id']] = item['Name']
final_dict[item['Name']] = []
for k in id_dict.keys():
# 循环id字典中的每一项,其中k为value值,用于访问链接,v为系列名字,用户添加数据至final_dict中的列表
model_url = 'https://www.asus.com.cn/support/api/product.asmx/GetPDLevel?website=cn&type=2&typeid=' + k + \
'&productflag=1 '
try:
model = requests.get(model_url, headers=headers, timeout=(60, 60))
model.raise_for_status()
model.encoding = "UTF-8"
model_text = model.text
model_dict = json.loads(model_text)
models = model_dict['Result']['Product'] # 获取型号列表
for item in models:
final_dict[id_dict[k]].append(item['PDName'])
except:
print("页面爬取失败!")
break
print("爬取成功,正在写入文件!")
if not os.path.exists("./data"):
# 如果文件夹data不存在,创建文件夹,并且书写文件,否则直接书写文件
os.makedirs("./data")
make_csv(final_dict)
else:
make_csv(final_dict)
print("文件写入成功!")
except:
print("页面爬取失败!")
这里虽然我没遇到,但是我感觉try里面的try会有问题,这里如果失败了,那么except里面print一个“页面爬取失败!”,然后反手又会再print一个“爬取成功,正在写入文件!”所以我就还没想清楚这里怎么修改,望大佬们指教。