Android Binder框架实现之Parcel详解一
前言
经过耕耘Android Binder框架实现源码深入分析系列文章告一段落!但是闲暇时间过来阅览发现该系列还是有许多瑕疵,主要是该系列太偏重重点的讲解了,而忽略了一些基本知识点的详细分析,所以这里反过来重新查漏补缺继续完善该系列文章。
Android Binder是Android高级进阶必须攻破的一个知识系列,说它简单吗也是简单就是一个IPC跨进程通信,但是说它复杂吗也复杂因为它将通信逻辑和业务逻辑巧妙地糅合在一起了,造成了学习上的难度!这个篇章不讲任何关于Android Binder的实现机制,而是讲述Android Binder通信过程中涉及的用户数据空间的数据封装容器Parcel的实现。
- 注意:本篇的介绍是基于Android 7.xx平台为基础的,其中涉及的代码路径如下:
frameworks/base/core/java/android/os/Parcel.java
frameworks/native/include/binder/Parcel.h
frameworks/native/libs/binder/Parcel.cpp
frameworks/base/core/jni/android_os_Parcel.cpp
frameworks/base/core/jni/AndroidRuntime.cpp
- 备注:后续为了书写方便将Java层的Parcel简化为J_Parcel,C++层的Parcel简化为C_Parcel,这里重点标注下,以免后续大家阅览的时候产生疑问!
一. 知识前期准备
在正式开始Parcel的源码分析前,还是老规矩磨刀不误砍柴工,先让我们来点前期知识储备再上马,更加事倍功倍!
1.1 序列化和反序列化
我们知道在Android操作系统底层,数据的传输形式是简单的字节序列形式传递,用通俗的化来说就是系统不认识对象,只认识字节序列!而我们为了达到进程通讯的目的,需要先将数据序列化和反序列化!那么它们两者的定义是什么呢:
- 序列化就是将对象转化字节序列的过程
- 相反地,当字节序列被运到相应的进程的时候,进程为了识别这些数据,就要将其反序列化,即把字节序列转化为对象。
而在Android的开发中存在两个用于序列化和反序列化的接口:Serializable接口和Parcelable接口,我们这里不对上述两个接口做过多的阐述,我们只需要知道二者存在如下几个区别:
- 使用范围的区别
- Serializable是属于 Java 自带的,表示一个对象可以转换成可存储或者可传输的状态,序列化后的对象可以在网络上进行传输,也可以存储到本地。
- Parcelable 是属于 Android 专用。不过不同于Serializable,Parcelable实现的原理是将一个完整的对象进行分解。而分解后的每一部分都是Intent所支持的数据类型。
- 实现方式的区别
- Serializable使用IO读写存储在硬盘上。序列化过程使用了反射技术,并且期间产生临时对象。优点代码少
- Parcelable是直接在内存中读写,我们知道内存的读写速度肯定优于硬盘读写速度,所以Parcelable序列化方式性能上要优于Serializable方式很多。但是代码写起来相比Serializable方式麻烦一些
- 使用选择的区别
我们前面知道了其使用的范围和实现的方式了,那么在实际使用中关于二者的选择也比较容易理解了:
- 如果是仅仅在内存中使用,比如activity、service之间进行对象的传递,强烈推荐使用Parcelable,因为Parcelable比Serializable性能高很多。因为Serializable在序列化的时候会产生大量的临时变量, 从而引起频繁的GC
- 如果是持久化操作,推荐Serializable,虽然Serializable效率比较低,但是还是要选择它,因为在外界有变化的情况下,Parcelable不能很好的保存数据的持续性
1.2 进程间数据传递
我们知道在Android中数据可以分为两种即基本数据类型和复杂对象类型,而通常进程间的数据传递也是传递如上两种。对于int,String等基本类型数值,通过IPC通信不断复制达到目标进程即可。但是如果是某个对象呢,如上方法明显不行!我们知道,同一进程间的对象传递都是通过引用来做的,因而本质上就是传递了一个内存的地址,但是这种方式明显在跨进程情况下就不行了。由于采用了虚拟内存机制,两个进程都有自己独立的内存地址空间,所以进程间传递地址值是无效的。而实现进程间复杂对象的传递就得借助前面章节的序列化和反序列化才能实施!
1.3 reinterpret_cast
reinterpret_cast (expression)
type-id 必须是一个指针、引用、算术类型、函数指针或者成员指针。它可以把一个指针转换成一个整数,也可以把一个整数转换成一个指针(先把一个指针转换成一个整数,再把该整数转换成原类型的指针,还可以得到原先的指针值)
reinterpret_cast,是C++里的强制类型转换符。用于进行各种不同类型的指针之间、不同类型的引用之间以及指针和能容纳指针的整数类型之间的转换。转换时,执行的是逐个比特复制的操作。这种转换提供了很强的灵活性,但转换的安全性只能由程序员的细心来保证了。这里我只是简单的介绍下基本概念,让小伙伴们有个基本理解,以免在后面的代码分析中有相关疑惑!
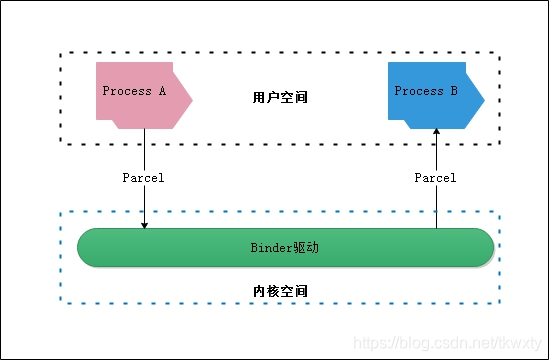
好了,有了前面的相关知识储备,是时候可以正式的开始来进行相关的Parcel分析了。在正式开始分析前还是老规矩附上框架图(即Parcel通过Binder IPC跨进程传递的框架图),如下:

二. Parcel概述
1.1 Parcel简介
通过前面系列博客Android Binder框架实现源码深入分析我们知道Android Binde进行跨进程IPC通信时,通常都是先将数据打包在Parcel对象中,然后通过Binder驱动进行传递。那么这里的Parcel究竟要怎么理解呢!
-
Parcel从英文字面意思来理解是打包的意思,即将我们要传输的数据进行相关封装打包,然后通过Binder进行传输,用于实现跨进程数据的通信
-
而Parcel作为Android Binder通信用户层空间的数据载体(这些数据包括基本类型数据和复杂对象数据),它提供了一套机制可以将用户层空间数据进行序列化之后写入到一块内存中,然后接着Binder驱动将数据传输到目标进程中,然后通过反序列化得到复杂对象,如下图所示:
-
从Android系统层面来说,Parcel在Android中是被用来设计存放读取数据的容器的一个工具,Android系统中的Binder进程间通信(IPC)就使用了Parcel类的这种特性来进行客户端与服务端数据交互,并且AIDL的数据也是通过Parcel来交互的。并且在Java层和C++层都实现了Parcel(通过JNI关联到一起的),由于它在C/C++中,直接使用了内存来读取数据,因此,它更有效率。
-
Parcel从存储角度来说,Parcel是内存中的结构的是一块连续的内存,会根据需要自动扩展大小(当然这个是设计者实现的)
-
Parcel从数据传入的角度出发,其传递的数据类型可以分为如下几种类型:
基本数据类型:借助Parcel的方法writePrimitives将基本数据类型从用户空间(源进程)copy到kernel空间(Binder驱动中)再写回用户空间(目标进程,binder驱动负责寻找目标进程)
复杂对象将经过序列化的数据借助Parcel的方法writeParcelable()/writeSerializable()从用户空间(源进程)copy到kernel空间(Binder驱动中)再写回用户空间(目标进程,binder驱动负责寻找目标进程),然后再反序列化
大型数据:通过Parcel的方法writeFileDescriptor通过Binder传递匿名共享内存 (Ashmem)的FileDescriptor从而达到传递匿名共享内存的方式,即传递的是FileDescriptor而并不是真的是大数据,参见博客Android 匿名共享内存的使用
IBinder对象:通过Parcel的方法writeStrongBinder方法,然后经由Kernel binder驱动专门处理来完成IBinder的传递
1.2 Parcel如何打包数据原理浅析
我们知道Parcel对数据打包的方式并不是唯一的,而是根据实际要传输的数据来选择具体方式的。我们知道Android Binder跨进程通讯中涉及的数据基本可以分为两个类型即基本数据类型和复杂对象类型,而我们的Parcel对这些数据类型的打包方式是截然不同的,我们来简单概括一下:
-
对于基本类型数据,譬如String,int等Parcel采取的策略是直接写进Parcel中,但是真的涉及到传输过程并不是真的将上述的基本数据类型传递过去了,而是将其值传递了
-
那么对于一些比较复杂的数据类型,比如一些自己定义的对象,要怎么写进Parcel里呢?我们知道通过一个类new一个对象时,这个object的有效范围只是在一个进程里。如果通过IPC机制直接传递一个object是不现实的。因为Java环境里的对象是通过引用來访问的,由于采用了虚拟内存机制,两个进程都有自己独立的内存地址空间,所以进程间传递地址值是无效的。所以在传递复杂对象时,必须把object拆解成中间形式,然后在IPC里传输这种中间格式。那怎么把一个object拆解成中间形式呢?这就涉及到数据的序列化和反序列化了(关于序列化家伙可以自行阅读相关的博客),其中关于IBinder数据的打包也可以归于这个其中
是不是描述的还是很抽象呢!对于Parcel的传输,我们可以比喻成用传真机來发送一个纸盒子到远方。传真机不是時空传送带,并不会真正可以实现某个物品的跨进程传送,但可以变通來完成,即将复杂数据先"拍扁"成基本数据类型传递到远程端,然后在远程端“反拍扁”基本数据成为复杂数据从而完成了数据的传递,其示意图如下:
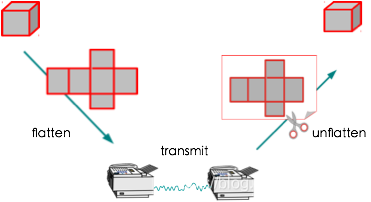
这样,传送一个纸盒子就可以分为三个部分了:
- 把纸盒拆解,得到平面化的图形。
- 把平面化的图形通过传真及传到远端。
- 远端的传真机收到平面化的图形后,就可以打印到纸上,再裁剪,粘帖,就可以得到一個一模一样的紙盒子了。
如果读者有一定的Android Binder基础,那么对这副图应该是更加有深刻的体会了,Android 通过Parcel传递IBinder的过程中涉及的的函数命名规则几乎上面的图示如出一辙。
1.3 Java层Parcel类官方解释
我们知道在Android世界的Java和C/C++层都有实现了Parcel,然后这两个层的Parcel通过JNI关联了起来。那么我们这里采取从上到下的策略来对Parcel庖丁解牛逐步分析!先从Java层的Parcel类开始分析!
1.3.1 Java层Parcel类总体描述
通常熟悉一个人都是先从脸下手,而对于一个Android中的类可以通常可以从官方注解开始,官方对其的定义如下所示:
//Parcel.java
Container for a message (data and object references) that can be sent through an IBinder. A Parcel can
contain both flattened data that will be unflattened on the other side of the IPC (using the various
methods here for writing specific types, or the general Parcelable interface), and references to
live IBinder objects that will result in the other side receiving a proxy IBinder connected with the
original IBinder in the Parcel.
Parcel is not a general-purpose serialization mechanism. This class (and the corresponding Parcelable API
for placing arbitrary objects into a Parcel) is designed as a high-performance IPC transport. As such,
it is not appropriate to place any Parcel data in to persistent storage: changes in the underlying
implementation of any of the data in the Parcel can render older data unreadable.
对着全是英文,一脸蒙逼的小伙伴,在这里我用我蹩脚的英文强制翻译一下(英文高手就路过就好了),这段话的核心如下(这里加入了我的理解,并不是完全就这英文翻译的):
- Parcel是用来盛放消息的容器类(这些消息包括基本类型数据和对象引用),并且Parcel借助Binder机制来进行传输
- Parcel能携带序列化后的数据通过IPC传输后在目的端进行相关的反序列化(至于怎么实现传输这些数据,主要是通过使用Parcel的多种类型的writing函数或者Parcelable接口)的数据)
- Parcel也可以传递IBinder对象,然后在其传输目的端的Parcel中将接收到原来传递的IBinder对象的代理端
- Parcel不是通用的序列化机制(通过前面的章节1.1我们可知Parcel是Android特有的,Java的序列化机制是Serilizable,在效率上不如Parcel)。
- Parcel类(以及用于将任意对象放入Parcel的相应的Parcelable API)谷歌的初衷是被设计用来进行高性能IPC传输的
- Parcel用来进行持久性存储中是不合适的,因为对Parcel中任何数据的基础实现的更改可能会使较旧的数据不可读
1.3.2 Java层Parcel类功能定义
前面的注释对Parcel有了一个整体上的描述,而我们也知道Parcel是用来进行各种数据的封装,然后辅助传输的。接下来的注释正是描述了Parcel支持那些数据以及这些数据可以通过借助什么方法完成传输,这里的相关方法暂时不标,只看支持的数据类型,其注释如下:
The bulk of the Parcel API revolves around reading and writing data of various types. There are six major
classes of such functions available
上面的英文比较简单,用一句话来概括就是"Parcel API的大部分内容围绕各种类型的数据的读写。 有六种主要的此类功能"。通过上面的我们知道了Parcel的整个一生都是围绕着上述六种数据类型绕圈圈的,这六种数据类型如下所示:
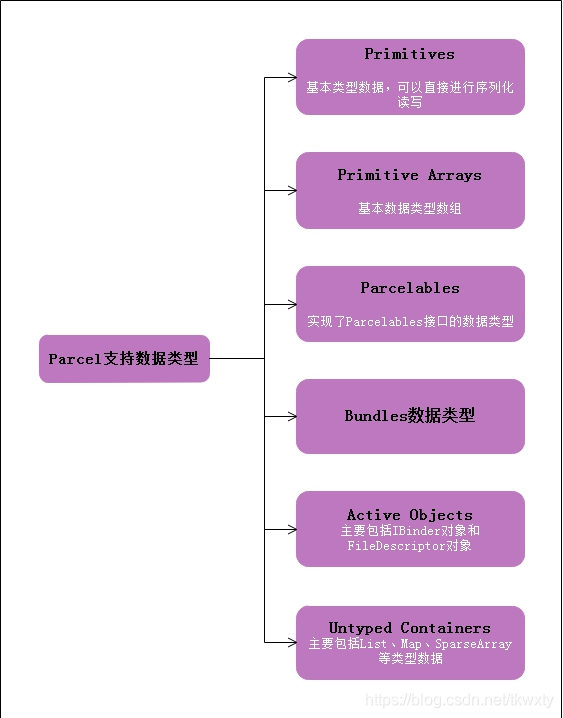
1.4 Java层Parcel类主要变量和方法
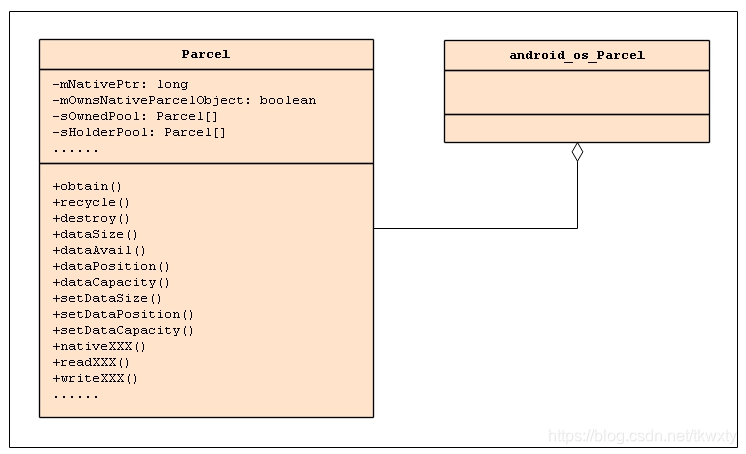
在正式开始Parcel的常用变量和方法分析前,我们先来看看其涉及到的类图关系如下,而我们也会参照这个类图涉及的相关关系进行分析:
1.4.1 Java层Parcel类主要变量
//Parcel.java
private long mNativePtr; // used by native code,该变量保存的是和Java层相对应的C++层的Parcel的地址值
/*
*Flag indicating if mNativePtr was allocated by this object, indicating that we're responsible for its lifecycle.
*/
private boolean mOwnsNativeParcelObject;//此变量用来标定mNativePtr变量是否是由该对象分配的,如果mNativePtr是由该对象分配的就得负责对其回收和销毁等生命周期负责,这个要怎么理解呢,这么说嘛因为Java层的Parcel可能是在Java层创建的那么这个mOwnsNativeParcelObject将会被设置为true,而Java层的Parcel也有可能是C++层通过JNI创建的那么此时的mOwnsNativeParcelObject就是false了
private static final int POOL_SIZE = 6;//默认创建Parcel对象池的大小
private static final Parcel[] sOwnedPool = new Parcel[POOL_SIZE];//Parcel对象池
private static final Parcel[] sHolderPool = new Parcel[POOL_SIZE];//Parcel对象池
这里我们看到Java层Parcel涉及的变量不是很多,其中我们需要关心的有如下几个:
-
mNativePtr: 该变量主要是提供给native层的Parcel使用,保存的是和Java层相对应的C++层的Parcel类的地址值。这种用法在Android中非常常见,通常的规则是如果在Java层和C++有一个命名相同的类然后通过JNI关联起来的话都会见到这种类似变量的身影(譬如MediaPlayer,Surface,MessageQueue等)。
-
POOL_SIZE: 创建默认Parcel对象池的大小值,类似于创建默认HashMap容量大小的默认值
-
sOwnedPool,sHolderPool: Parcel对象池,用于通过Parcel.obtain()快速获取Parcel实例对象
1.4.2 Java层Parcel容器类基本操作方法
我们知道Parcel作为一个容器类,也可以算得上是一种数据结构了,那么就必须满足数据结构的基本定义,提供相对应数据结构基本功能,譬如设置/获取容量的大小,获取当前存储的位置等等。Parcel谷歌出品必属精品当然也有提供,下面我们看看其作为容器类提供的基本方法:
| 方法名称 | 方法功能 |
|---|---|
| int dataSize() | 获取当前Parcel容器类的实际存储的数据总量 |
| int dataAvail() | 获取当前Parcel容器类的可读数据的总量 |
| int dataPosition() | 获取当前Parcel容器类中数据的当前位置值(类似偏移量,这个有数据结构基本理论的话很好理解,读取数据必须知道当前的位置了)有点类似于游标卡池 |
| int dataCapacity() | 当前Parcel容器类的总存储容量,注意这个的返回值要大于dataSize()大小,这也很好理解一个是Parcel的设计存储容量,一个是实际存储容量吗 |
| setDataSize(int size) | 更改Parcel中的实际数据量(这个和dataSize() 对应),该参数值可以大于或者小于dataSize() 的值,并且该值如果大于当前容量(dataCapacity() ),将会进行扩容分配更多的内存 |
| setDataPosition(int pos) | 改变Parcel中的读写位置(或者说是偏移量),必须介于0和dataSize()间,这个Position很重要用于定位实际读写数据的具体位置 |
| setDataCapacity | 设置Parcel的实际存储容量大小 |
Parcel作为一个成熟的数据结构容器类,当上层使用它并且向Parcel填充数据的时候,如果系统发现了超出了Parcel的默认存储能力,它会自动申请所需要的内存空间,并扩展dataCapacity,并且每次写入都是从dataPosition()开始的。只要不断往Parcel填充数据这个过程是周而复始的直到填充结束。
1.4.3 Java层Parcel类读写Primitives基本数据方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Primitives基本数据的操作,其中涉及的方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeByte(byte val) | 向Parcel写入一个byte数据值 |
| byte readByte() | 从Parcel当前偏移量位置读取一个byte数据 |
| writeDouble(double val) | 向Parcel写入一个double类型的双精度浮点值 |
| double readDouble() | 从Parcel当前偏移量位置读取一个double类型的双精度浮点值 |
| writeFloat(float val) | 向Parcel写入一个float类型的单精度浮点值 |
| float readFloat() | 从Parcel当前偏移量位置读取一个float类型的单精度浮点值 |
| writeInt(int val) | 向Parcel写入一个int类型的整形值 |
| int readInt() | 从Parcel当前偏移量位置读取一个int类型的整形值 |
| writeLong(long val) | 向Parcel写入一个long类型的长整形值 |
| long readLong() | 从Parcel当前偏移量位置读取一个long类型的长整形值 |
| writeString(String val) | 向Parcel写入一个String类型字符串 |
| String readString() | 从Parcel当前偏移量位置读取一个String类型的数据 |
通过上面的表格我们可以看到对基本类型数据的读/写方法是成对出现的,即读写必须匹配。且根据Parcel官方注释基本数据的读写遵循主机CPU的字节序来进行的(至于什么是CPU字节序,各位看官请自行百度)
1.4.4 Java层Parcel类读写Primitive Arrays基本数据数组方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Primitive Arrays基本数据数组的操作,其中涉及的方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeBooleanArray(boolean[])/readBooleanArray(boolean[]) | 向Parcel中读/写boolean类型数组,其读/写数据放入参数中 |
| boolean[] createBooleanArray() | 从Parcel读取并返回一个boolean类型数组 |
| writeByteArray(byte[])/readByteArray(byte[]) | 向Parcel中读/写byte类型数组,其读/写数据放入参数中 |
| byte[] createByteArray() | 从Parcel中读取并返回一个byte类型数组 |
| writeCharArray(char[])/readCharArray(char[]) | 向Parcel中读/写char类型数组,其读/写数据放入参数中 |
| char[] createCharArray() | 从Parcel中读取并返回一个char类型数组 |
| writeDoubleArray(double[])/readDoubleArray(double[]) | 向Parcel中读/写double类型数组,其读/写数据放入参数中 |
| double[] createDoubleArray() | 从Parcel中读取并返回一个double类型数组 |
| writeFloatArray(float[])/readFloatArray(float[]) | 向Parcel中读/写float类型数组,其读/写数据放入参数中 |
| float[] createFloatArray() | 从Parcel中读取并返回一个float类型数组 |
| writeIntArray(int[])/readIntArray(int[]) | 向Parcel中读/写int类型数组,其读/写数据放入参数中 |
| int[] createIntArray() | 从Parcel中读取并返回一个int类型数组 |
| writeLongArray(long[])/readLongArray(long[]) | 向Parcel中读/写long类型数组,其读/写数据放入参数中 |
| long[] createLongArray() | 从Parcel中读取并返回一个long类型数组 |
| writeStringArray(String[])/readStringArray(String[]) | 向Parcel中读/写String类型数组,其读/写数据放入参数中 |
| String[] createStringArray() | 从Parcel中读取并返回一个String类型数组 |
通过上面的表格我们可以看到对基本类型数组数据的读/写和基本数据的读写差别不大,但是有几点需要注意的:
- 对基本数据类型的数组写入操作通常是先用写入4个字节长度的整形表示数组的长度,然后遍历数组按照基本类型数据写入
- 对基本数据类型的数组读取操作通常是先读取4个字节长度的整形表示数组的长度,依次读取去前面取出的数组长度的基本类型数据
- 对基本类型数据数组的读有两种方式,一种是使用已经创建好的基本数组,另外一种是直接通过Parcel读取并返回回来基本类型数据数组
1.4.5 Java层Parcel类读写Parcelables可序列化数据方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Parcelables可序列化数据方的操作,其中涉及的方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeParcelable(Parcelable, int) | 将这个Parcelable类的名字和内容写入Parcel中,实际上它是通过回调此Parcelable的writeToParcel()方法来写入数据的 |
| T readParcelable(ClassLoader ) | 读取并返回一个新的Parcelable对象 |
| writeParcelableArray(T[] ,int ) | 写入Parcelable对象数组 |
| Parcelable[] readParcelableArray(ClassLoader ) | 兑取Parcelable对象数组 |
关于其怎么实现的暂时不表,我们只需要知道借助上述方法可以读取遵循Parcelables可序列化的对象,谷歌官方解释是高效然后加低级协议不是很明白。
1.4.6 Java层Parcel类读写Bundles数据方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Bundles数据方的操作,其中涉及的方法如下:
| 方法名称 | 方法功能 |
|---|---|
| Bundle readBundle(ClassLoader) | 从Parcel中读取并返回一个新的Bundle对象,ClassLoader用于Bundle获取对应的Parcelable对象 |
| Bundle readBundle() | 从Parcel中读取并返回一个新的Bundle对象 |
| writeBundle(Bundle ) | 向Parcel写入Bundle型数据 |
我们知道Bundles实现了Parcelable相关接口,是一种特殊类型的安全容器,其最大特点是其数据存储采取“键值对”的存取方式,但是相较于HashMap又在一定程度上优化了效率。
1.4.7 Java层Parcel类读写Activity Object数据方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Activity Object数据方的操作。而我们知道Android中的数据接口有很多种,而为什么Parcel缺独领风骚的承担起了Binder传输过程中数据载体的重任,我个人认为其核心就是其支持Active Objects的读写!那么什么是Active Object?通常我们存入Parcel的是对象的内容,而Active Object 写入的则是他们的特殊标志引用。所以在从Parcel中读取这些对象时,大家看到的并不是重新创建的对象实例,而是原来那个被写入的实例。可以猜想到,能够以这种方式传输的对象不会很多,目前主要有两种类型分别如下:
- IBinder: Binder对象是Android通用跨进程通信系统的核心功能。 IBinder接口描述了一个带有Binder对象的抽象协议。 可以将任何此类接口写入Parcel,并且在对端读取时将收到实现该接口的原始对象或将调用传递回原始对象的特殊代理实现(这个现在不理解可以暂时不管,待完整学习了一篇Binder机制你就应该会有所明白了),其涉及的主要方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeStrongInterface(IInterface) | 向Parcel写入一个IInterface类型对象,其实间接写入的也是IBinder类型对象 |
| writeStrongBinder(IBinder) | 向Parcel写入一个IBinder类型对象 |
| IBinder readStrongBinder() | 从Parcel中获取一个IBinder对象 |
- FileDescriptor:如果说Linux中万物操作皆基于文件,那么FileDescriptor就可以认为相关文件操作后的文件描述符,然后该文件描述符可以通过Parcel如下方法进行传递(Android Binder 匿名共享内存的使用),其涉及的主要方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeFileDescriptor(FileDescriptor) | 向Parcel写入一个FileDescriptor类型对象 |
| ParcelFileDescriptor readFileDescriptor() | 从Parcel中读取一个FileDescriptor类型对象 |
1.4.8 Java层Parcel类读写Untyped Containers数据方法
在章节1.3.2我们概括了Parcel支持读取操作的六种基本数据类型,其中就包括对Untyped Containers数据方的操作。那么什么是Untyped Containers数据呢,我们可以通俗的理解为Java支持的标准容器,譬如List,HashMap等。其涉及的常用方法如下:
| 方法名称 | 方法功能 |
|---|---|
| writeArray(Object[]) | 向Parcel写入Object[]类型数据,注意这里Object一定要是Parcel能支持的数据类型 |
| Object[] readArray(ClassLoader ) | 从Parcel中读取Object类型数据 |
| writeList(List) | 向Parcel中写入List数据 |
| readList(List, ClassLoader) | 从Parcel中读取List数据 |
| ArrayList readArrayList(ClassLoader) | 从Parcel中读取ArrayList数据 |
| writeMap(Map) | 向Parcel中写入Map数据 |
| readMap(Map, ClassLoader) | 从Parcel中读取Map数据 |
1.4.9 Java层Parcel类创建和回收方法
Parcel作为一个容器类数据结构对象,必定存在创建和回收的相关方法,其如下所示:
| 方法名称 | 方法功能 |
|---|---|
| Parcel obtain() | 从Parcel对象池中获取空闲的Parcel对象 |
| void recycle() | 清空回收该Parcel对象的内存,然后如有可能将其放入Parcel的对象池中 |
1.4.10 Java层Parcel类异常读写方法
Android在Binder传输过程中不可避免的会发生异常,而Parcel作为Binder数据上层的载体那么必须提供读写异常的方法,这不就安排上了。
| 方法名称 | 方法功能 |
|---|---|
| writeException(Exception e) | 异常处理,将异常结果写入Parcel对象数据的标头即起始位置用于表示Binder传输过程的异常 |
| void readException() | 从Parcel起始位置读取,若读取值为异常,则抛出该异常,否则程序正常运行 |
三. Parcel数据结构容器类的获取,回收及销毁
行文至此,我觉得再写下去我都要疯了!概念性的东西写多了,是时候来整点硬货了。现在正式来开始借助源码来进行相关的实现分析了,在正式分析前,我们先看来看怎么正确使用和获取Jave层Parcel对象,如下所示:
Parcel mParcel = Parcel.obtain();//详见章节3.1
这里我们可以看到并不是直接通过new来进行相关对象创建的,其创建方法和Message的如出一辙通过obtain方法获取,关于谁抄袭了谁这个我们就当吃瓜群众就好了(反正是它谷歌家的事)!至于为什么通过如此方法进行相关的创建,请看下面的分析。
3.1 J_Parcel对象的获取(Parcel.obtain)
//Parcel.java
private static final int POOL_SIZE = 6;
private static final Parcel[] sOwnedPool = new Parcel[POOL_SIZE];
/**
* Retrieve a new Parcel object from the pool.
* 从Parcel对象池中取出一个新的Parcel对象
*/
public static Parcel obtain() {
//sOwnedPool为我们预先已经创建好了的Parcel对象池
final Parcel[] pool = sOwnedPool;
synchronized (pool) {
Parcel p;
for (int i=0; i<POOL_SIZE; i++) {
p = pool[i];
if (p != null) {
//引用置为空,这样下次就知道这个Parcel已经被占用了,当通过recyle进行回收的时候会通过这个判断是否被引用然后进行回收
pool[i] = null;
if (DEBUG_RECYCLE) {
p.mStack = new RuntimeException();
}
return p;
}
}
}
return new Parcel(0);//如果没有合适的则直接构造一个Parcel对象,详见章节3.2
}
Parcel类的静态方法obtain其代码逻辑如下:
- 查询预置Parcel对象池sOwnedPool中是否有空闲的Parcel对象(因为预置Parcel的对象池大小是6),如果有则取出一个合适的Parcel对象,并将对该Parcel的引用置为空(注意sOwnedPool中该对象还是实际存在的依然在方法区中,只是引用失效了,对于这块不是很熟悉的可以参见博客从Android程序员的角度理解JVM内存布局)。
- 如果Parcel对象池中已经没有合适的Parcel可用了,则直接new一个出来,关于该方法详见3.2
3.2 J_Parcel构造方法(Parcel.Parcel)
闲话短说,直接来看其构造函数:
//Parcel.java
private Parcel(long nativePtr) {
if (DEBUG_RECYCLE) {
mStack = new RuntimeException();
}
init(nativePtr);
}
这里我们需要重点注意的是其构造函数是private,即对外不能直接new出该对象!然后接着继续分析可以看到啥也没有做调用了init方法,这里注意传入的参数值为0。接着继续分析init方法:
private void init(long nativePtr) {
if (nativePtr != 0) {//参数值不为0
mNativePtr = nativePtr;
mOwnsNativeParcelObject = false;
} else {//参数值为0,显然会走这条分析,
mNativePtr = nativeCreate();//一看方法名称就知道这里是一个本地方法,详见3.4
mOwnsNativeParcelObject = true;
}
}
这里我们知道传递进来的参数为0所以会走后面的分支!但是如果传进来的参数不为0,就将参数保存到mNativePtr变量中,该变量保存的是Java层Parcel对应的C++层Parcel对象的地址,同时设置mOwnsNativeParcelObject为false,表示该Java层Parcel对象现在还没有关联上C++层的Parcel对象。因为此时传进来的参数为0,因此函数将调用nativeCreate()函数来创建一个C++层的Parcel对象,并将该对象的地址保存在mNativePtr变量中,设置mOwnsNativeParcelObject为true,表示该Parcel对象已经关联了C++的Parcel对象。
3.3 Java层的Parcel类JNI注册函数
我们知道Parcel存在本地方法,而在正式开始分析其本地方法之前让我们看看其JNI的注册逻辑。在博客Android Zygote进程启动源码分析指南的章节七中我们知道Zygote进程在启动过程中会注册一些的JNI方法,而我们的Parcel的本地方法对应的JNI也是在这个时期注册的,而通过我们前面的框架图也知道Parcel的Java层相关操作最终都是通过JNI交由C++层的Parcel类来执行的。
//AndroidRuntime.cpp
REG_JNI(register_android_os_Parcel)
Parcel类的JNI注册函数实现为:
//android_os_Parcel.cpp
const char* const kParcelPathName = "android/os/Parcel";
int register_android_os_Parcel(JNIEnv* env)
{
jclass clazz = FindClassOrDie(env, kParcelPathName);
//保存Java层的android.os.Parcel类的信息到JNI层的gParcelOffsets变量中
gParcelOffsets.clazz = MakeGlobalRefOrDie(env, clazz);
//将Java层的Parcel中的mNativePtr保存到mNativePtr中
gParcelOffsets.mNativePtr = GetFieldIDOrDie(env, clazz, "mNativePtr", "J");
gParcelOffsets.obtain = GetStaticMethodIDOrDie(env, clazz, "obtain", "()Landroid/os/Parcel;");
gParcelOffsets.recycle = GetMethodIDOrDie(env, clazz, "recycle", "()V");
//数组gParcelMethods中存放了Parcel类的JNI函数与Java本地函数之间的映射关系,通过registerNativeMethods()函数即可注册Parcel类的JNI函数
return RegisterMethodsOrDie(env, kParcelPathName, gParcelMethods, NELEM(gParcelMethods));
}
gParcelOffsets是C++中的静态类变量,在Zygote启动时通过JNI方法来读取android.os.Parcel类信息,并保持到gParcelOffsets结构体变量中,当C++层需要创建Java层的Parcel对象时,通过JNI方法及android.os.Parcel类信息就可以在C++层创建一个Java对象,这种在Java层和C++层拥有相同命名的类之间通常使用这汇总方法关联起来。
3.4 Parcel.nativeCreate
通过章节3.3我们可以知道nativeCreate通过JNI注册的本地函数为android_os_Parcel_create(),让我们分析之而后快:
//android_os_Parcel.cpp
static jlong android_os_Parcel_create(JNIEnv* env, jclass clazz)
{
Parcel* parcel = new Parcel();//详见章节3.5
return reinterpret_cast<jlong>(parcel);//返回C++层Parcel对象的地址值
}
注意这里的返回值为C++层Parcel对象的地址,然后该地址存放在Java层Parcel中的mNativePtr ,这也解释了我在1.4.1 章节说的mNativePtr很重要的原因,因为获取了C++层的Parcel对象的地址,以意味着我们可以通过该值能直接获取该C++层的Parcel对象了,接着继续分析C++层的Parcel的创建,详见章节3.5。
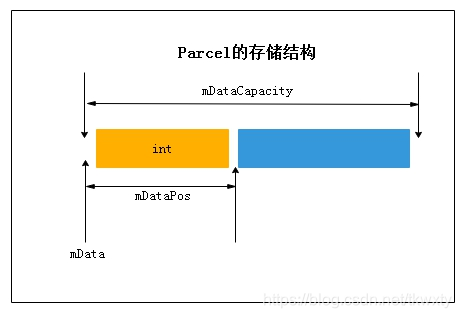
3.5 C_Parcel的构造函数(Parcel::Parcel)
在正式开始分析C++层的Parcel前,先看看它的头文件定义,这里先不做过多分析,因为这里分析过多会让读者晕头转向的,这个只有代入实际的Android Binder交互过程中才更加容易的理解,后续在分析。
//frameworks/native/include/binder/Parcel.h
class Parcel {
public:
...
// 获取数据(返回mData)
const uint8_t* data() const;
// 获取数据大小(返回mDataSize)
size_t dataSize() const;
// 获取数据指针的当前位置(返回mDataPos)
size_t dataPosition() const;
private:
...
status_t mError;
uint8_t* mData; // 数据
size_t mDataSize; // 数据大小
size_t mDataCapacity; // 数据容量
mutable size_t mDataPos; // 数据指针的当前位置
size_t* mObjects; // 对象在mData中的偏移地址
size_t mObjectsSize; // 对象个数
size_t mObjectsCapacity; // 对象的容量
...
}
接着继续分析其构造函数,如下:
//Parcel.cpp
Parcel::Parcel()
{
LOG_ALLOC("Parcel %p: constructing", this);
initState();
}
void Parcel::initState()
{
mError = NO_ERROR;
mData = 0; //数据的地址指针
mDataSize = 0; //数据的大小
mDataCapacity = 0; //数据的容量
mDataPos = 0; //数据的位置
mObjects = NULL; //保存对象的地址指针
mObjectsSize = 0; //对象的个数
mObjectsCapacity = 0; //对象的容量
mNextObjectHint = 0;
mHasFds = false;
mFdsKnown = true;
mAllowFds = true;
mOwner = NULL;
mOpenAshmemSize = 0;
...
}
可以看到C++层的Parcel构建非常简单就是调用initState函数,然后将C++层Parcel类的相关变量进行默认初始化而已。
3.6 Parcel构造过程小结
通过前面对Java层Parcel构造的分析,我们可以看到其跨越了Java层并且通过JNI关联到了C++层,其时序逻辑如下:

通过如上流程,这样就构造了一对Parcel对象,分别是Java层的Parcel和C++层的Parcel对象,Java层的Parcel对象保存了C++层的Parcel对象的地址,而C++层在JNI函数注册时就保存了Java层的Parcel类的信息。通过这种方式就Java层的Parcel就可以很方便地找到与其对应的C++层Parcel对象,同时在C++层也可以创建出一个Java层的Parcel对象。这种套路在Android中非常常见,感兴趣的小伙伴们可以自行阅读相关源码,找找看还有那些相关的类运用了这套流程!
3.7 Parcel数据结构容器类的回收和销毁
抛开Parcel种种功能,将Parcel单纯的作为一个数据结构来说必须存在数据结构相关的回收和销毁机制,而Parcel作为一个成熟的数据结构类,肯定是存相关的机制的。那么Parcel是怎么实现上述两种机制的呢,让我们掰持掰持看看。
3.7.1 Parcel.recycle
我们知道Parcel是一弹双星,构建了J_Parcel和C_Parcel,而为了最大程度的复用Parcel对象,J_Parcel提供了相关的回收机制,即调用其方法recycle,我们看看其实怎么做到回收的!
//Parcel.java
/**
* Put a Parcel object back into the pool. You must not touch
* the object after this call.
* 注释很经典啊,将该Parcel放到对象池之后,你将会失去和它的联系
*/
public final void recycle() {
if (DEBUG_RECYCLE) mStack = null;
freeBuffer();//调用C_Parcel的回收
final Parcel[] pool;
if (mOwnsNativeParcelObject) {//会走此分支,选择合适的对象池
pool = sOwnedPool;
} else {
mNativePtr = 0;
pool = sHolderPool;
}
synchronized (pool) {
for (int i=0; i<POOL_SIZE; i++) {
if (pool[i] == null) {//在前面我们知道通过obtain方法从Parcel对象池中获取Parcel对象的时候,会将取出的的对象池的引用置为空,然后通过判断引用是否为空判断是否有位置然后将此对象加入对象池
pool[i] = this;
return;
}
}
}
}
private void freeBuffer() {
if (mOwnsNativeParcelObject) {
updateNativeSize(nativeFreeBuffer(mNativePtr));
}
}
这里的回收逻辑可以分为两部分:
- J_Parcel的回收是从J_Parcel对象池中引用中找到合适的对象池引用然后将其指向将要回收的J_Parcel在方法区中的位置,而这里的对象池有有两种sOwnedPool和sHolderPool,而通过我们前面的分析可知我们知道此处的对象池是sOwnedPool(sHolderPool和sOwnedPool的唯一区别就是sOwnedPool对象池保存的C_Parcel对象的生命周期需要自己进行管理,感觉很拗口啊!)。
- 继续分析nativeFreeBuffer,可以看到最终调用了C_Parcel的freeData方法进行回收。
//android_os_Parcel.cpp
static jlong android_os_Parcel_freeBuffer(JNIEnv* env, jclass clazz, jlong nativePtr)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);
if (parcel != NULL) {
parcel->freeData();
return parcel->getOpenAshmemSize();
}
return 0;
}
经过如上recyle如上操作之后完成了Parcel的相关回收(即J_Parcel的复用和C_Parcel相关内存的释放和清空),此时用户层就不能对Parcel继续使用了除非重新obtain重新获取。
3.7.2 Parcel.finalize
我们知道C++层的对象的销毁通常是从析构开始的,而Java层的对象销毁是从finalize方法开始的,而我们Java层的Parcel作为一个标准的好青年也遵循了这一伟大的传统逻辑。
//Parcel.java
@Override
protected void finalize() throws Throwable {
if (DEBUG_RECYCLE) {
if (mStack != null) {
Log.w(TAG, "Client did not call Parcel.recycle()", mStack);
}
}
destroy();
}
private void destroy() {
if (mNativePtr != 0) {
if (mOwnsNativeParcelObject) {
nativeDestroy(mNativePtr);//典型的本地方法,注意这里传递的参数未C_Parcel对象的地址值
updateNativeSize(0);
}
mNativePtr = 0;
}
}
在前面的章节3.6的小结分析中我们知道了Parcel在构建过程中会创建两个Parcel对象,一个是Java层的一个是C++层的,J_Parcel销毁非常简单不需要做什么额外的事情,需要重点关注的是C_Parcel,因为Parcel的实际工作基本都是交由C_Parcel来进行实施的,而J_Parcel只是空有一个皮囊罢了。而通过前面的分析,此时的mOwnsNativeParcelObject被置为了true即我们需要负责管理C++层Parcel的销毁,可以看到最终调用了nativeDestroy()方法从而关联到了C_Parcel层,继续深挖分析
//android_os_Parcel.cpp
static void android_os_Parcel_destroy(JNIEnv* env, jclass clazz, jlong nativePtr)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);//通过地址值强制转换成C_Parcel对象
delete parcel;//直接delete parcel对象
}
可以看到这里的逻辑非常简单,通过J_Parcel保存的C_Parcel对象的地址值然后依据该地址值强制转换成C_Parcel对象,最后将该对象delete掉。
四. Parcel数据结构容器类对基本数据的打包过程分析
通过前面的章节我们知道Parcel对传输数据的支持从整个大类上来划分可以分为两种,一种是基本数据及其的封装,另外一种就是就是其核心秘密武器对IBinder类型对象结构的传输支持。本来打算将上述两个类型的传输放在该篇章中全部分析完毕,但是发现如果是如此安排那又是裹脚布了又臭又长了,我分析得累,阅读的小伙伴们会更加类,所以这里只分析基本的数据打包传输流程,这里我们以writeInt/readInt为例说明Parcel怎么对基本数据的传输。
4.1 Parcel.writeInt
在正式进行源码分析前,先奉上相关的时序图如下所示:

/**
* Write an integer value into the parcel at the current dataPosition(),
* growing dataCapacity() if needed.
* 从解释来看就是向Parcel的当前偏移(游标)位置写入一个int整形值
*/
//Parcel.java
public final void writeInt(int val) {
nativeWriteInt(mNativePtr, val);
}
无需多言,可以看到这里调用了nativeWriteInt的本地方法从而借助JNI进入了Native层,继续往下看
//android_os_Parcel.cpp
static void android_os_Parcel_writeInt(JNIEnv* env, jclass clazz, jlong nativePtr, jint val) {
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);//将地址值强制转换成C_Parcel对象
if (parcel != NULL) {
const status_t err = parcel->writeInt32(val);//直接调用C_Parcel的writeInt32函数
if (err != NO_ERROR) {
signalExceptionForError(env, clazz, err);
}
}
}
4.1.1 Parcel::writeInt32()
//Parcel.cpp
#define STRICT_MODE_PENALTY_GATHER (0x40 << 16)
status_t Parcel::writeInt32(int32_t val)
{
return writeAligned(val);
}
这里我们以写入STRICT_MODE_PENALTY_GATHER 为例说明,继续调用writeAligned函数。
4.1.2 Parcel::writeAligned()
//Parcel.cpp
template<class T>
//模板函数
status_t Parcel::writeAligned(T val) {
COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(val)) <= mDataCapacity) {
restart_write:
*reinterpret_cast<T*>(mData+mDataPos) = val;
return finishWrite(sizeof(val));
}
status_t err = growData(sizeof(val));
if (err == NO_ERROR) goto restart_write;
return err;
}
writeAligned()的作用是是写入数据,譬如同步相应的变量,下面渐进分析:
- 我们通过前面章节3.5分析我们知道,在函数writeAligned()中此时mDataPos的初始值=0,sizeof(val)=4,mDataCapacity的初始值=0。因此,if((mDataPos+sizeof(val)) <= mDataCapacity)为false。
- 接下来,会先调用growData(sizeof(val))来增加容量,然后再将数据写入到mData中。
4.1.3 Parcel::growData()
//Parcel.cpp
status_t Parcel::growData(size_t len)
{
if (len > INT32_MAX) {
return BAD_VALUE;
}
size_t newSize = ((mDataSize+len)*3)/2;
return (newSize <= mDataSize)
? (status_t) NO_MEMORY
: continueWrite(newSize);
}
接着继续分析growData(字面理解就可以看出是增加容量),通过代码可以看出Parcel增加容量时,是按1.5倍进行增长,因为此时mDataSize=0,而len=4;因此会执行continueWrite(6)。
4.1.4 Parcel::continueWrite()
//Parcel.cpp
status_t Parcel::continueWrite(size_t desired)
{
size_t objectsSize = mObjectsSize;
...
if (mOwner) {
...
} else if (mData) {
...
// We own the data, so we can just do a realloc().
if (desired > mDataCapacity) {
uint8_t* data = (uint8_t*)realloc(mData, desired);
if (data) {
mData = data;
mDataCapacity = desired;
} else if (desired > mDataCapacity) {
...
}
} else {
...
}
} else {
...
}
return NO_ERROR;
}
接着继续分析continueWrite,此时mObjectsSize的初始值为0,mOwner的初始值为NULL,mData非空;并且,desired=6,mDataCapacity=0。因此,会调用realloc()给mData重新分配内存大小为6字节。分配成功后,更新"数据地址mData"和"数据容量mDataCapacity=6"。接下来,回到writeAligned()中,它会跳转到restart_write标签处。先将int32_t的整形数保存到mData中,然后再调用finishWrite()进行同步。
4.1.5 Parcel::finishWrite()
//Parcel.cpp
status_t Parcel::finishWrite(size_t len)
{
if (len > INT32_MAX) {
return BAD_VALUE;
}
mDataPos += len;
if (mDataPos > mDataSize) {
mDataSize = mDataPos;
...
}
return NO_ERROR;
}
下面我们继续分析finishWrite(),在前面的步骤中已经将数据写入到mData中,现在就通过finishWrite()来改变数据的当前指针位置(方便下一次写入)和数据的大小。此时
(1) len是int32_t的大小,很显然是4个字节,len=4。所以,mDataPos=4。
(2) mDataPos=4,mDataSize=0;因此if(mDataPos>mDataSize)为true,所以,mDataSize=4。
到这里我们就已经分析完了writeInterfaceToken()中的writeInt32()的所有过程了。下面让我们再理一理此时Parcel里面各个变量的值。
mData:它的第0~3个字节保存了int32_t类型的数据STRICT_MODE_PENALTY_GATHER。
mDataPos:值为4,即下一个写入mData中的数据从第4个字节开始。
mDataSize:值为4,即mData中数据的大小。
mDataCapacity:值为6,即mData的数据容量为6字节。
此时,mData的数据如下图所示:

4.1.6 Parcel.writeInt小结
好了writeInt分析完毕了,我们假设Parcel在内存中是以类似数组的存储空间进行存储的(这个只是假设,实际并不是如此),那么此时各个C_Parcel的位置相关的变量值的逻辑如下所示(是不是觉得Parcel还是很简单吗(到这里还是很简单,待分析完成了IBinder的打包和传输你就不会这么说了!),这里需要重点说明的是mData的值肯定不为0,因为内存中的0地址是给系统预留的,但是mDataPos的值是从0开始增长起来的。
4.2 Parcel.readInt()
在正式进行源码分析前,先奉上相关的时序图如下所示:

//Parcel.java
/**
* Read an integer value from the parcel at the current dataPosition().
* 从Parcel的当前偏移量位置读取一个int整形数据
*/
public final int readInt() {
return nativeReadInt(mNativePtr);
}
无需多言,可以看到这里调用了nativeReadInt的本地方法从而借助JNI进入了Native层,继续往下看
//android_os_Parcel.cpp
static jint android_os_Parcel_readInt(JNIEnv* env, jclass clazz, jlong nativePtr)
{
Parcel* parcel = reinterpret_cast<Parcel*>(nativePtr);//将地址值强制转换为C_Parcel对象
if (parcel != NULL) {
return parcel->readInt32();//直接调用C_Parcel的readInt32函数
}
return 0;
}
4.2.1 Parcel::readInt32()
//Parcel.cpp
int32_t Parcel::readInt32() const
{
return readAligned<int32_t>();
}
木有啥好说的,接着往下分析
4.2.2 Parcel::readInt32()
//Parcel.java
template<class T>
T Parcel::readAligned() const {
T result;
if (readAligned(&result) != NO_ERROR) {
result = 0;
}
return result;
}
//模板函数
template<class T>
status_t Parcel::readAligned(T *pArg) const {
COMPILE_TIME_ASSERT_FUNCTION_SCOPE(PAD_SIZE_UNSAFE(sizeof(T)) == sizeof(T));
if ((mDataPos+sizeof(T)) <= mDataSize) {//判断当前偏移量(光标位置)加上模板变量的大小是否超过了总的数据大小
const void* data = mData+mDataPos;//获取实际的读取变量的地址值
mDataPos += sizeof(T);
*pArg = *reinterpret_cast<const T*>(data);//将地址值强制转变成变量,然后以指针的形式返回
return NO_ERROR;
} else {
return NOT_ENOUGH_DATA;
}
}
4.3 Parcel数据结构容器类对基本数据的打包过程分析小结
这里我们以writeInt/readInt为例说明Parcel怎么对基本数据的传输就告一段落了,关于其它的基本类型的读取也可以参照如上的分析依葫芦画瓢的分析,但是有一个关键点需要我们关注那就是写入基本类型数据的时候的偏移量(游标)位置的移动问题。
4.3.1 Parcel数据结构容器类对基本数据的打包偏移量小结
//frameworks/native/include/binder/Parcel.h
class Parcel {
public:
...
// 获取数据(返回mData)
const uint8_t* data() const;
// 获取数据大小(返回mDataSize)
size_t dataSize() const;
// 获取数据指针的当前位置(返回mDataPos)
size_t dataPosition() const;
private:
...
status_t mError;
uint8_t* mData; // 数据
size_t mDataSize; // 数据大小
size_t mDataCapacity; // 数据容量
mutable size_t mDataPos; // 数据指针的当前位置
size_t* mObjects; // 对象在mData中的偏移地址
size_t mObjectsSize; // 对象个数
size_t mObjectsCapacity; // 对象的容量
...
}
还记得我们在分析C_Parcel时候,其变量mDataPos这个值表示当前Parcel要读取/写入的具体位置,当读取/写入时候需要移动该mDataPos,但是针对某些基本数据的写入其mDataPos的偏移并不是变量数据实际所占内存的大小,而是必须要遵循如下规则:
- 实际写入字节:
场景一:写入4个字节 (<=32bit) 例如:boolean,char,int
场景二:实际占用字节(>32bit) 例如:long,float,String(这个还有点特殊,后面再说) 等
- 实际读取字节:
场景一:4个字节 (<=32bit) 例如:boolean,char,int
场景二:实际占用字节(>32bit) 例如:long,float,String 组等
何以为证,代码不会说谎如下:
//Parcel.cpp
status_t Parcel::writeBool(bool val)
{
return writeInt32(int32_t(val));
}
status_t Parcel::writeChar(char16_t val)
{
return writeInt32(int32_t(val));
}
status_t Parcel::writeByte(int8_t val)
{
return writeInt32(int32_t(val));
}
status_t Parcel::readByte(int8_t *pArg) const
{
int32_t tmp;
status_t ret = readInt32(&tmp);
*pArg = int8_t(tmp);
return ret;
}
status_t Parcel::readBool(bool *pArg) const
{
int32_t tmp;
status_t ret = readInt32(&tmp);
*pArg = (tmp != 0);
return ret;
}
status_t Parcel::readChar(char16_t *pArg) const
{
int32_t tmp;
status_t ret = readInt32(&tmp);
*pArg = char16_t(tmp);
return ret;
}
为什么C_Parcel必须遵循如上规则呢,如果大家对C语言熟悉的话,C语言中结构体的内存对齐和Parcel采用的内存存放机制一样,即读取最小字节为32bit,也即4个字节。高于4个字节的,以实际数据类型进行存放,但得为4byte的倍数。所以C_Parcel也必须遵循对其规则,仅此而已。
所以,当我们写入/读取一个数据时,偏移量至少为4byte(32bit),于是,偏移量的公式如下:
f(x)= 4x (x=1,....n)
最后借用一张老李头的图总结下如下:

4.3.2 Parcel数据结构容器类对基本数据读取小结
由于Parcel的设计或者使用过程中不可避免的会出现一些使用不当,但是必须遵循写入和读取相匹配的规则,即读写的数据类型必须相符匹配,不能是写入init然后读取long这个肯定会发生读取错误,那么是读取出来了数据也不会是你想要的。同时对于存在读取异常错误或者偏差的时候,Parcel指定了如下的规则:
- 读取简单基本数据时:对象匹配时,返回当前偏移位置的对象:对象不匹配时,返回0
//Parcl.cpp
template<class T>
T Parcel::readAligned() const {
T result;
if (readAligned(&result) != NO_ERROR) {
result = 0;
}
return result;
}
- 读取复杂对象时:对象匹配时,返回当前偏移位置的对象;对象不匹配时,返回NULL
const flat_binder_object* Parcel::readObject(bool nullMetaData) const
{
const size_t DPOS = mDataPos;
if ((DPOS+sizeof(flat_binder_object)) <= mDataSize) {
...
}
return NULL;
}
小结
Android Binder框架实现之Parcel详解一就到这里告一段落了,将Parcel的基本分析了个七七八八了,基本数据类型的传输打包也分析完毕了,但是还有一个最最重磅的IBinder的打包传输还没有分析,这个将放到后面的章节进行相关的分析。好了,先说再见了。如果对你有帮助,欢迎关注和点赞,当然拍砖也是OK的,各位江湖见!